AI pulse last 7 days
Daily AI pulse from YouTube, blogs, Reddit, HN. Ruthlessly filtered.
Sources (41)▶
- criticalAndrej Karpathy
Były dyrektor AI w Tesli, OpenAI cofounder. Każde video to gold.
- criticalAnthropic
Oficjalny kanał Anthropic. Każdy release Claude'a.
- criticalComfyUI Blog
Release log dla integracji ComfyUI — Luma Uni-1, GPT Image 2, ACE-Step music gen, Seedance. Pokrywa video+image+music+workflow.
- criticalOpenAI Blog
Oficjalny blog OpenAI. Wszystkie release.
- criticalSimon Willison's Weblog
Najlepszy 'thinker' AI. Codzienne posty, deep insights, niska hype rate.
- highAI Explained
Głęboka analiza papers i benchmarków, niska hype rate.
- highAI Jason
Praktyczne tutoriale Claude Code, MCP, workflow vibe codingu.
- highBen's Bites
Daily AI digest, creator-friendly tone. Codex, model releases, agentic AI.
- highCole Medin
Vibe coding + agentic workflows + Claude Code MCP integrations.
- highFal AI Blog
Fal hostuje większość nowych AI image/video modeli — ich blog to wczesne sygnały premier.
- highHN: 3D & Gaussian Splatting
HN signal dla 3D generative — Gaussian Splatting, NeRF, image-to-3D. Próg 20 bo niszowa kategoria (top historic 182pts).
- highHN: AI agents / MCP
HN posty o agentach, MCP, vibe codingu z min 100 pkt.
- highHN: Claude / Anthropic
HN posty z 'Claude' lub 'Anthropic' z min 100 pkt.
- highHugging Face Blog
Releases dla image, video, audio, 3D modeli. Część tech-heavy — Gemini relevance odfiltruje noise. Downgraded z critical: za duży volume na 'must-read' status.
- highIndyDevDan
Claude Code power user, prompty, hooki.
- highInterconnects (Nathan Lambert)
AI policy + research analysis. Niska hype rate, opinionated.
- highLatent Space
Podcast + blog Swyx — wywiady z founderami i deep dives engineeringowe.
- highMatt Wolfe
Comprehensive AI tools weekly digest. ~700K subs.
- highMatthew Berman
AI news, model release reviews, agent demos. Wysoki output.
- highr/aivideo
Community AI video — Sora, Veo, Runway, Kling, LTX. Co naprawdę zaskakuje twórców.
- highr/ClaudeAI
Społeczność Claude'a — power users, tipy, problemy.
- highr/LocalLLaMA
Open-source LLMs, lokalne uruchamianie, benchmarks bez hype.
- highr/StableDiffusion
Największa community open-source image gen (700k+ users). Premiery modeli, LoRA, ComfyUI workflows.
- highRiley Brown
Vibe coding, AI builder workflows, Cursor + Claude tutorials.
- highThe Decoder
Niemiecki AI news outlet po angielsku, dobre breaking news.
- highTheo - t3.gg
TypeScript + AI dev workflows. Hot takes, narrative-driven.
- highYannic Kilcher
Paper reviews i deep dives w research AI.
- lowAI Weirdness
Janelle Shane — playful AI experiments, image gen quirks. Niski volume, unikalna perspektywa.
- mediumbycloud
AI papers digestible — między 2MP a Yannic Kilcher.
- mediumCreative Bloq
Design industry — gdzie AI ingeruje w klasyczne dyscypliny graficzne.
- mediumFireship
100-sec format, often AI/LLM + tech news.
- mediumfxguide
VFX i film industry — coraz więcej AI w pipeline. Profesjonalna perspektywa.
- mediumGreg Isenberg
Solo founder vibe — buduje produkty z AI, podcasty z indie hackers.
- mediumr/ChatGPTCoding
Vibe coding tipy, IDE setupy, prompty. Mix wszystkich modeli.
- mediumr/comfyui
ComfyUI workflows — custom nodes, JSON workflows, optymalizacje.
- mediumr/midjourney
Midjourney community — premiery v7+, style references, prompt patterns.
- mediumr/runwayml
Runway-specific community — premiery features, prompt patterns, comparisons z konkurencją.
- mediumr/SunoAI
Suno music gen community — nowe wersje modelu, lyric prompting techniques. Audio AI ma slaby RSS ecosystem.
- mediumTina Huang
AI workflows for data science, practical applications.
- mediumTwo Minute Papers
Krótkie streszczenia papers AI, świetne dla szybkiego scan'a.
- mediumWes Roth
AI news z bardziej clickbaitowym tonem — filtr Gemini odsiewa hype.
Qwen3.6 27B uncensored heretic v2 Native MTP Preserved is Out Now With KLD 0.0021, 6/100 Refusals and the Full 15 MTPs Preserved and Retained, Available in Safetensors, GGUFs and NVFP4s formats.
A high-performance, uncensored 27B model that successfully retains advanced Multi-Token Prediction (MTP) features for better local inference.
LLMFan46 has released 'heretic v2', an uncensored fine-tune of the Qwen3.6 27B model. This release is notable for preserving all 15 native Multi-Token Prediction (MTP) modules, which are frequently lost or degraded during the fine-tuning process. The model achieves a very low Kullback–Leibler divergence (KLD) of 0.0021, suggesting it maintains the original model's reasoning capabilities while eliminating refusals. With a refusal rate of only 6%, it is optimized for unrestricted local use. The model is available in multiple formats including Safetensors, GGUF, and NVFP4 to support various hardware setups.
r/LocalLLaMA·model_release·05/07/2026, 02:59 AM·/u/LLMFan46Get faster qwen 3.6 27b
Achieve 50 t/s on Qwen 3.6 27B with 100k context on a single RTX 3090 by using MTP GGUFs and a specific llama.cpp branch.
A user on r/LocalLLaMA shared a method to significantly boost inference speeds for the Qwen 3.6 27B model on consumer hardware. By utilizing Multi-Token Prediction (MTP) GGUF files and a specific pull request for llama.cpp, they achieved speeds of 50 tokens per second on an RTX 3090. The setup involves using Q4_K_M quantization for the model and Q4_0 for the K/V cache to fit a 100k context within 19GB of VRAM. The post includes a step-by-step guide for applying the PR and the exact server configuration flags needed. It also mentions a Mac-specific installation via Homebrew for similar performance gains.
r/LocalLLaMA·tooling·05/06/2026, 11:33 PM·/u/admajicUploaded Unsloth Qwen3.6-35B-A3B UD XL models with MTP grafted, here are the results
MTP (Multi-Token Prediction) can significantly speed up local LLM inference, but its effectiveness varies greatly depending on the model architecture and hardware setup.
User /u/havenoammo released GGUF versions of the Qwen3.6-35B-A3B model featuring 'grafted' Multi-Token Prediction (MTP) layers. While MTP previously showed 2-2.5x speedups on dense models like the 27B variant, results for this MoE (Mixture of Experts) version are more modest, ranging from a 6% to 50% increase in tokens per second. The performance seems highly dependent on the specific GPU configuration and quantization level (Q4 vs Q8). The release includes the isolated MTP layers and conversion scripts on HuggingFace, allowing the community to experiment with speculative decoding. These preliminary results suggest that MoE architectures might not benefit as uniformly from MTP as dense models do in current llama.cpp implementations.
r/LocalLLaMA·tooling·05/06/2026, 09:51 PM·/u/havenoammoKijai LTX 2.3 WIth 12 GB of VRam demo reel
You can now run the high-quality LTX 2.3 22B video model on a standard 12GB VRAM GPU using GGUF quantization and specialized ComfyUI workflows.
A user demonstrated that the LTX 2.3 22B video generation model can produce high-quality 8-second clips on consumer-grade hardware. By utilizing GGUF quantization and specific ComfyUI workflows developed by Kijai, the model fits within 12GB of VRAM, specifically tested on an RTX 3060 with 32GB of system RAM. This is a significant milestone as it brings state-of-the-art open-weight video generation to hobbyist setups. The shared resources include the GGUF model files and optimized workflows available on Civitai. This setup balances performance and accessibility, making long-form AI video generation more feasible for local execution without requiring enterprise-grade hardware.
r/comfyui·tooling·05/06/2026, 09:09 PM·/u/OfficeMagic1Qwen3.6-27B with MTP grafted on Unsloth UD XL: 2.5x throughput via unmerged llama.cpp PR
Boost your local Qwen3.6-27B inference speed by 2.5x using MTP-enabled GGUFs and a custom llama.cpp build.
A community developer has successfully implemented Multi-Token Prediction (MTP) for the Qwen3.6-27B model in GGUF format, achieving a 2.5x increase in token throughput. By 'grafting' Q8-quantized MTP draft heads onto Unsloth UD XL base models, the setup allows for speculative decoding where four tokens are predicted per forward pass. This implementation utilizes an unmerged llama.cpp pull request (#22673) to enable MTP support locally, a feature previously limited to server-side engines like vLLM. The method adds minimal VRAM overhead while significantly improving inference speed on consumer hardware. Detailed build instructions and the conversion script are provided on HuggingFace.
r/LocalLLaMA·tooling·05/06/2026, 11:45 AM·/u/havenoammo
SenseNova-u1 | Low(ish) vram workflow
Run the new SenseNova-u1 multimodal model on 8GB VRAM using a GGUF-optimized ComfyUI workflow for high-res 2048px generations.
SenseNova-u1 is a unified multimodal model now accessible via GGUF quantization, making it runnable on consumer hardware like 8GB VRAM GPUs. The model excels at text rendering, portraiture, and image editing, with a native generation resolution of 2048x2048. Two versions are available: a Turbo variant requiring only 8 steps and a Base variant for 50 steps. While the Q6 GGUF file is approximately 16GB, the VRAM footprint is kept around 5GB during execution. A dedicated ComfyUI workflow has been released on Civitai to help users implement these high-resolution generations efficiently.
r/comfyui·model_release·05/06/2026, 11:13 AM·/u/MFGREBEL2.5x faster inference with Qwen 3.6 27B using MTP - Finally a viable option for local agentic coding - 262k context on 48GB - Fixed chat template - Drop-in OpenAI and Anthropic API endpoints
Run Qwen 3.6 27B locally with 2.5x speedup (up to 28 tok/s) using new MTP support in llama.cpp and optimized GGUF quants.
A new optimization for Qwen 3.6 27B leverages Multi-Token Prediction (MTP) via a llama.cpp Pull Request to achieve 2.5x faster inference. User /u/ex-arman68 shared custom GGUF quants that include fixed chat templates and support for massive context windows, reaching up to 262k on 48GB RAM using q4_0 KV cache compression. The setup requires compiling a specific experimental branch of llama.cpp but delivers approximately 28 tokens per second on Apple Silicon. Detailed hardware recommendations for both Mac and NVIDIA users are provided, covering various RAM configurations from 16GB to 80GB. Note that vision capabilities currently conflict with MTP in this experimental build.
r/LocalLLaMA·tooling·05/06/2026, 09:35 AM·/u/ex-arman68Qwen 3.6 27b Q4.0 MTP GGUF
Multi-Token Prediction (MTP) allows running a 27b model at the speed of a 9b model on integrated GPUs using llama.cpp.
A user report on r/LocalLLaMA highlights the performance benefits of Multi-Token Prediction (MTP) for the Qwen 3.6 27b model. Using the Q4.0 GGUF quantization in llama.cpp, the 27b model achieves inference speeds comparable to the smaller 9b Qwen 3.5 model. This test was conducted on an AMD iGPU with 64GB of unified memory, demonstrating that MTP significantly lowers the hardware barrier for running larger models locally. The results suggest that MTP is a viable path for making mid-sized models feel as responsive as small models on consumer-grade integrated graphics.
r/LocalLLaMA·tooling·05/06/2026, 03:01 AM·/u/Available_Hornet3538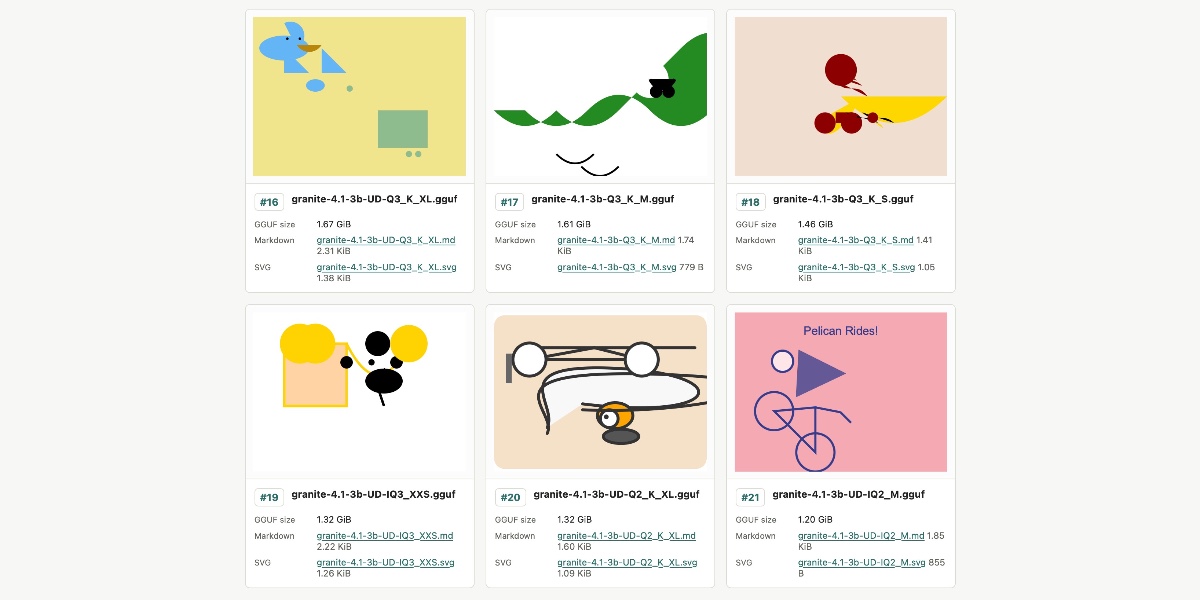
Granite 4.1 3B SVG Pelican Gallery
IBM's new Granite 4.1 3B model struggles with complex SVG generation regardless of quantization level, serving as a reality check for small model capabilities.
IBM recently released the Granite 4.1 family of LLMs, featuring 3B, 8B, and 30B versions under the Apache 2.0 license. Simon Willison tested the 3B model's creative capabilities using 21 different GGUF quantized variants provided by Unsloth. The experiment focused on generating an SVG of a pelican riding a bicycle to see if higher precision (larger file size) improved output quality. Surprisingly, the results were consistently poor across all sizes, from 1.2GB to 6.34GB, with no clear correlation between quantization level and visual accuracy. This suggests that for complex spatial reasoning like SVG coding, the base capabilities of a 3B model may be the bottleneck rather than the quantization method.
Simon Willison's Weblog·model_release·05/04/2026, 11:49 PM
Relevance auto-scored by LLM (0–10). List shows top 30 from the last 7 days.