AI pulse last 7 days
Daily AI pulse from YouTube, blogs, Reddit, HN. Ruthlessly filtered.
Sources (41)▶
- criticalAndrej Karpathy
Były dyrektor AI w Tesli, OpenAI cofounder. Każde video to gold.
- criticalAnthropic
Oficjalny kanał Anthropic. Każdy release Claude'a.
- criticalComfyUI Blog
Release log dla integracji ComfyUI — Luma Uni-1, GPT Image 2, ACE-Step music gen, Seedance. Pokrywa video+image+music+workflow.
- criticalOpenAI Blog
Oficjalny blog OpenAI. Wszystkie release.
- criticalSimon Willison's Weblog
Najlepszy 'thinker' AI. Codzienne posty, deep insights, niska hype rate.
- highAI Explained
Głęboka analiza papers i benchmarków, niska hype rate.
- highAI Jason
Praktyczne tutoriale Claude Code, MCP, workflow vibe codingu.
- highBen's Bites
Daily AI digest, creator-friendly tone. Codex, model releases, agentic AI.
- highCole Medin
Vibe coding + agentic workflows + Claude Code MCP integrations.
- highFal AI Blog
Fal hostuje większość nowych AI image/video modeli — ich blog to wczesne sygnały premier.
- highHN: 3D & Gaussian Splatting
HN signal dla 3D generative — Gaussian Splatting, NeRF, image-to-3D. Próg 20 bo niszowa kategoria (top historic 182pts).
- highHN: AI agents / MCP
HN posty o agentach, MCP, vibe codingu z min 100 pkt.
- highHN: Claude / Anthropic
HN posty z 'Claude' lub 'Anthropic' z min 100 pkt.
- highHugging Face Blog
Releases dla image, video, audio, 3D modeli. Część tech-heavy — Gemini relevance odfiltruje noise. Downgraded z critical: za duży volume na 'must-read' status.
- highIndyDevDan
Claude Code power user, prompty, hooki.
- highInterconnects (Nathan Lambert)
AI policy + research analysis. Niska hype rate, opinionated.
- highLatent Space
Podcast + blog Swyx — wywiady z founderami i deep dives engineeringowe.
- highMatt Wolfe
Comprehensive AI tools weekly digest. ~700K subs.
- highMatthew Berman
AI news, model release reviews, agent demos. Wysoki output.
- highr/aivideo
Community AI video — Sora, Veo, Runway, Kling, LTX. Co naprawdę zaskakuje twórców.
- highr/ClaudeAI
Społeczność Claude'a — power users, tipy, problemy.
- highr/LocalLLaMA
Open-source LLMs, lokalne uruchamianie, benchmarks bez hype.
- highr/StableDiffusion
Największa community open-source image gen (700k+ users). Premiery modeli, LoRA, ComfyUI workflows.
- highRiley Brown
Vibe coding, AI builder workflows, Cursor + Claude tutorials.
- highThe Decoder
Niemiecki AI news outlet po angielsku, dobre breaking news.
- highTheo - t3.gg
TypeScript + AI dev workflows. Hot takes, narrative-driven.
- highYannic Kilcher
Paper reviews i deep dives w research AI.
- lowAI Weirdness
Janelle Shane — playful AI experiments, image gen quirks. Niski volume, unikalna perspektywa.
- mediumbycloud
AI papers digestible — między 2MP a Yannic Kilcher.
- mediumCreative Bloq
Design industry — gdzie AI ingeruje w klasyczne dyscypliny graficzne.
- mediumFireship
100-sec format, often AI/LLM + tech news.
- mediumfxguide
VFX i film industry — coraz więcej AI w pipeline. Profesjonalna perspektywa.
- mediumGreg Isenberg
Solo founder vibe — buduje produkty z AI, podcasty z indie hackers.
- mediumr/ChatGPTCoding
Vibe coding tipy, IDE setupy, prompty. Mix wszystkich modeli.
- mediumr/comfyui
ComfyUI workflows — custom nodes, JSON workflows, optymalizacje.
- mediumr/midjourney
Midjourney community — premiery v7+, style references, prompt patterns.
- mediumr/runwayml
Runway-specific community — premiery features, prompt patterns, comparisons z konkurencją.
- mediumr/SunoAI
Suno music gen community — nowe wersje modelu, lyric prompting techniques. Audio AI ma slaby RSS ecosystem.
- mediumTina Huang
AI workflows for data science, practical applications.
- mediumTwo Minute Papers
Krótkie streszczenia papers AI, świetne dla szybkiego scan'a.
- mediumWes Roth
AI news z bardziej clickbaitowym tonem — filtr Gemini odsiewa hype.
Running Qwen3.5 / Qwen3.6 with NextN MTP (Multi-Token Prediction) speculative decode in llama.cpp — single RTX 3090 Ti GPU guide
Speed up Qwen 3.5/3.6 models by nearly 3x on a single GPU using NextN Multi-Token Prediction in llama.cpp with this specific build and quantization guide.
This technical guide details how to implement NextN Multi-Token Prediction (MTP) for the Qwen 3.5 and 3.6 model families using llama.cpp. By leveraging MTP, users can achieve approximately 2.9x faster decoding speeds with zero loss in output quality, as the prediction heads are natively integrated into these models. The process currently requires building llama.cpp from specific pull requests (#22400 and #22673) or using a provided fork. A critical step involves a specific quantization override (--tensor-type nextn=q8_0) to prevent output corruption. Benchmarks show the 35B MoE variant reaching an impressive ~150 tokens per second on a single RTX 3090 Ti.
r/LocalLLaMA·tutorial·05/07/2026, 09:56 AM·/u/yes_i_tried_google
ParoQuant: Pairwise Rotation Quantization for Efficient Reasoning LLM Inference
ParoQuant is a new quantization method that preserves the reasoning and logic capabilities of LLMs at low bitrates better than standard techniques.
ParoQuant introduces Pairwise Rotation Quantization, a novel technique designed to minimize information loss during the compression of reasoning-heavy LLMs. Unlike standard quantization methods that often degrade complex logic chains, ParoQuant uses a pairwise approach to handle outlier weights more effectively. The release includes a dedicated GitHub repository and pre-quantized models on HuggingFace for immediate testing. This is particularly significant for users running large reasoning models on consumer hardware where VRAM is limited. Initial benchmarks suggest superior performance in maintaining Chain of Thought (CoT) coherence compared to traditional 4-bit methods.
r/LocalLLaMA·tooling·05/07/2026, 02:07 AM·/u/Total-Resort-3120
Quality comparison between Qwen 3.6 27B quantizations (BF16, Q8_0, Q6_K, Q5_K_XL, Q4_K_XL, IQ4_XS, IQ3_XXS,...)
For 16GB VRAM users, Qwen 3.6 27B at IQ4_XS quantization is the ideal choice, balancing high-quality reasoning (like SVG generation) with usable local performance.
A detailed community benchmark by /u/bobaburger compares various quantization levels of the Qwen 3.6 27B model to find the optimal balance for 16GB VRAM hardware. The test uses a creative and difficult task: tracking a non-standard chess game from PGN and rendering the board state as functional SVG code. Results show that while BF16 and Q8 are near-perfect, IQ4_XS emerges as the recommended 'sweet spot' for consumer GPUs, maintaining spatial reasoning where lower quants (Q3 and below) fail. The author also demonstrates significant performance gains using the TurboQuant fork of llama.cpp, reaching 22 tokens per second on an RTX 5060 Ti.
r/LocalLLaMA·tooling·05/06/2026, 05:10 AM·/u/bobaburger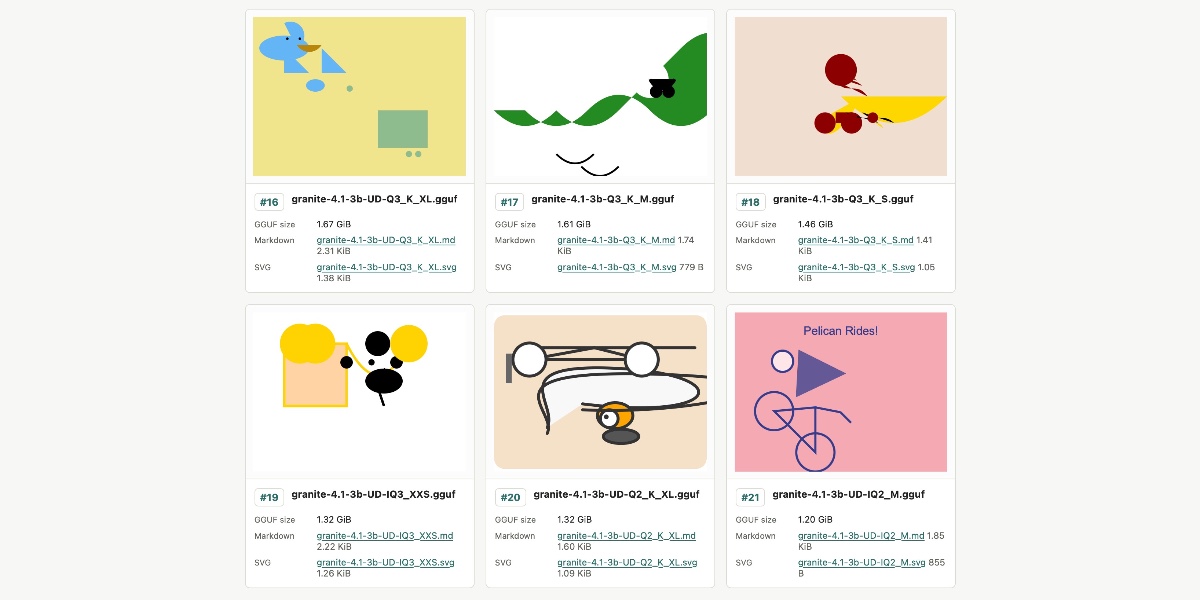
Granite 4.1 3B SVG Pelican Gallery
IBM's new Granite 4.1 3B model struggles with complex SVG generation regardless of quantization level, serving as a reality check for small model capabilities.
IBM recently released the Granite 4.1 family of LLMs, featuring 3B, 8B, and 30B versions under the Apache 2.0 license. Simon Willison tested the 3B model's creative capabilities using 21 different GGUF quantized variants provided by Unsloth. The experiment focused on generating an SVG of a pelican riding a bicycle to see if higher precision (larger file size) improved output quality. Surprisingly, the results were consistently poor across all sizes, from 1.2GB to 6.34GB, with no clear correlation between quantization level and visual accuracy. This suggests that for complex spatial reasoning like SVG coding, the base capabilities of a 3B model may be the bottleneck rather than the quantization method.
Simon Willison's Weblog·model_release·05/04/2026, 11:49 PM
Relevance auto-scored by LLM (0–10). List shows top 30 from the last 7 days.