AI pulse last 7 days
Daily AI pulse from YouTube, blogs, Reddit, HN. Ruthlessly filtered.
Sources (41)▶
- criticalAndrej Karpathy
Były dyrektor AI w Tesli, OpenAI cofounder. Każde video to gold.
- criticalAnthropic
Oficjalny kanał Anthropic. Każdy release Claude'a.
- criticalComfyUI Blog
Release log dla integracji ComfyUI — Luma Uni-1, GPT Image 2, ACE-Step music gen, Seedance. Pokrywa video+image+music+workflow.
- criticalOpenAI Blog
Oficjalny blog OpenAI. Wszystkie release.
- criticalSimon Willison's Weblog
Najlepszy 'thinker' AI. Codzienne posty, deep insights, niska hype rate.
- highAI Explained
Głęboka analiza papers i benchmarków, niska hype rate.
- highAI Jason
Praktyczne tutoriale Claude Code, MCP, workflow vibe codingu.
- highBen's Bites
Daily AI digest, creator-friendly tone. Codex, model releases, agentic AI.
- highCole Medin
Vibe coding + agentic workflows + Claude Code MCP integrations.
- highFal AI Blog
Fal hostuje większość nowych AI image/video modeli — ich blog to wczesne sygnały premier.
- highHN: 3D & Gaussian Splatting
HN signal dla 3D generative — Gaussian Splatting, NeRF, image-to-3D. Próg 20 bo niszowa kategoria (top historic 182pts).
- highHN: AI agents / MCP
HN posty o agentach, MCP, vibe codingu z min 100 pkt.
- highHN: Claude / Anthropic
HN posty z 'Claude' lub 'Anthropic' z min 100 pkt.
- highHugging Face Blog
Releases dla image, video, audio, 3D modeli. Część tech-heavy — Gemini relevance odfiltruje noise. Downgraded z critical: za duży volume na 'must-read' status.
- highIndyDevDan
Claude Code power user, prompty, hooki.
- highInterconnects (Nathan Lambert)
AI policy + research analysis. Niska hype rate, opinionated.
- highLatent Space
Podcast + blog Swyx — wywiady z founderami i deep dives engineeringowe.
- highMatt Wolfe
Comprehensive AI tools weekly digest. ~700K subs.
- highMatthew Berman
AI news, model release reviews, agent demos. Wysoki output.
- highr/aivideo
Community AI video — Sora, Veo, Runway, Kling, LTX. Co naprawdę zaskakuje twórców.
- highr/ClaudeAI
Społeczność Claude'a — power users, tipy, problemy.
- highr/LocalLLaMA
Open-source LLMs, lokalne uruchamianie, benchmarks bez hype.
- highr/StableDiffusion
Największa community open-source image gen (700k+ users). Premiery modeli, LoRA, ComfyUI workflows.
- highRiley Brown
Vibe coding, AI builder workflows, Cursor + Claude tutorials.
- highThe Decoder
Niemiecki AI news outlet po angielsku, dobre breaking news.
- highTheo - t3.gg
TypeScript + AI dev workflows. Hot takes, narrative-driven.
- highYannic Kilcher
Paper reviews i deep dives w research AI.
- lowAI Weirdness
Janelle Shane — playful AI experiments, image gen quirks. Niski volume, unikalna perspektywa.
- mediumbycloud
AI papers digestible — między 2MP a Yannic Kilcher.
- mediumCreative Bloq
Design industry — gdzie AI ingeruje w klasyczne dyscypliny graficzne.
- mediumFireship
100-sec format, often AI/LLM + tech news.
- mediumfxguide
VFX i film industry — coraz więcej AI w pipeline. Profesjonalna perspektywa.
- mediumGreg Isenberg
Solo founder vibe — buduje produkty z AI, podcasty z indie hackers.
- mediumr/ChatGPTCoding
Vibe coding tipy, IDE setupy, prompty. Mix wszystkich modeli.
- mediumr/comfyui
ComfyUI workflows — custom nodes, JSON workflows, optymalizacje.
- mediumr/midjourney
Midjourney community — premiery v7+, style references, prompt patterns.
- mediumr/runwayml
Runway-specific community — premiery features, prompt patterns, comparisons z konkurencją.
- mediumr/SunoAI
Suno music gen community — nowe wersje modelu, lyric prompting techniques. Audio AI ma slaby RSS ecosystem.
- mediumTina Huang
AI workflows for data science, practical applications.
- mediumTwo Minute Papers
Krótkie streszczenia papers AI, świetne dla szybkiego scan'a.
- mediumWes Roth
AI news z bardziej clickbaitowym tonem — filtr Gemini odsiewa hype.

[HIPHOP] Late Night Hustle | Dark Emotional Hip Hop / Trap Song
See how SunoAI can generate mood-specific hip-hop/trap instrumentals, perfect for creative projects or background music, even if you're not a musician.
User u/Guitardep shared "Late Night Hustle," an AI-generated dark emotional hip-hop/trap song created with SunoAI. The track, posted on r/SunoAI, is described as an instrumental blend of modern trap drums, fast hi-hats, deep bass, and atmospheric textures, designed for late-night creative sessions. This piece exemplifies SunoAI's growing capability to produce genre-specific and mood-driven music, offering non-musicians a powerful tool for generating background tracks or inspiration. It showcases the practical application of AI in crafting complex, atmospheric soundscapes for various creative needs.
r/SunoAI·creative_work·05/07/2026, 01:30 PM·/u/GuitardepOpen-sourcing Banodoco Hivemind: 1M+ Discord messages from artists and engineers working deeply with open image/video models, packaged as an agent skill
A massive dataset of real-world discussions from artists and engineers using open image/video AI models is now available, offering a unique resource for building smarter creative…
The Banodoco Hivemind, a substantial dataset comprising over 1 million Discord messages from artists and engineers, has been open-sourced. This collection captures deep, practical discussions around open image and video AI models, offering insights into real-world usage, problem-solving, and creative applications. Packaged as an "agent skill," this resource is designed to enhance the capabilities of AI agents, allowing them to better understand and assist users in creative workflows. It provides a novel foundation for developing more context-aware and helpful AI assistants, moving beyond generic training data to specialized, community-driven knowledge.
r/comfyui·tooling·05/07/2026, 01:30 PM·/u/PetersOdyssey
Open-sourcing Banodoco Hivemind: 1M+ Discord messages from artists and engineers working deeply with open image/video models, packaged as an agent skill
This open-sourced database of over a million Discord messages offers practical insights and best practices for open image/video models, directly queryable by AI agents or users.
Banodoco Hivemind has been open-sourced, providing access to over a million Discord messages collected over three years from artists and engineers deeply engaged with open image and video models. This valuable dataset, previously locked within Discord, is now available as an "agent skill," allowing AI agents or individual users to query it for best practices, comparisons, and specific settings related to various models like Wan Animate or LTX. The creator, /u/PetersOdyssey, emphasizes its utility for surfacing previously siloed knowledge and plans for live updates and eventual public web search indexing. This release offers a unique resource for understanding real-world application and troubleshooting of open-source creative AI tools.
r/StableDiffusion·tooling·05/07/2026, 01:30 PM·/u/PetersOdyssey
[Bollywood pizza] LE ROSE FIORIRANNO PER NOI
This Reddit post features a unique AI-generated music track from Suno AI, blending "Bollywood pizza" themes, offering a quick listen to the platform's creative capabilities.
A Reddit user, u/Fun_Operation8440, recently shared an AI-generated music track titled "LE ROSE FIORIRANNO PER NOI" on the r/SunoAI subreddit. The piece is notably described with the intriguing tag "[Bollywood pizza]", indicating a fusion of genres or styles. This creation serves as a practical demonstration of Suno AI's capabilities in generating diverse and creatively themed musical compositions. While not a new model release or technical breakthrough, it highlights the platform's potential for hobbyists and creative non-developers to produce unique audio content. The track itself is linked to a YouTube video, allowing listeners to experience this specific AI-driven artistic output.
r/SunoAI·creative_work·05/07/2026, 01:18 PM·/u/Fun_Operation8440
SenseNova U1 Interleaved Output: From Single Prompt to Consistent Visual Set
Discover SenseNova U1's new Interleaved function to generate consistent, structured content that seamlessly blends text and images from a single prompt, perfect for tutorials or c…
SenseNova's U1 Fast model has introduced an "Interleaved" output function, allowing users to generate continuous, structured content that combines text and images from a single complex prompt. Unlike traditional single-image generators, this feature aims to process intricate instructions, such as creating a sourdough bread tutorial, by weaving together visual and textual elements logically. The user, /u/ReonNYK, highlights its potential for maintaining stylistic consistency and narrative coherence across multiple outputs, suggesting it could be superior for content creation like comic strips. This represents a significant advancement in multi-modal AI generation, moving beyond isolated images to more integrated storytelling.
r/StableDiffusion·tooling·05/07/2026, 01:17 PM·/u/ReonNYK
[edm/metal/industrial] Copyright This Shit
Explore a user-shared example of Suno AI's impressive ability to generate complex, multi-genre music (EDM, metal, industrial), sparking thoughts on AI-generated content copyright.
Reddit user /u/moonysugar showcased an AI-generated music track on r/SunoAI, blending EDM, metal, and industrial genres. Titled "Copyright This Shit," the post highlights the user's confidence in the piece's quality, suggesting it rivals human-created works. This submission serves as a practical demonstration of Suno AI's advanced capabilities in producing complex, multi-genre musical compositions. It implicitly raises important questions about the copyright status and intellectual property rights of creative content generated by artificial intelligence. The post illustrates how AI tools empower hobbyists to create sophisticated audio, blurring lines between human and machine artistry.
r/SunoAI·creative_work·05/07/2026, 01:10 PM·/u/moonysugar
Elon doubled limits
Free ChatGPT users gain a much more capable GPT-5.5 Instant model and spreadsheet integration, while paid Claude users can now utilize twice as much capacity and leverage new agen…
OpenAI has rolled out GPT-5.5 Instant to all free ChatGPT users, offering substantial improvements in vision, PDF comprehension, web search, and memory, alongside a 52.5% reduction in hallucinations compared to its predecessor. Additionally, ChatGPT now directly integrates with Excel and Google Sheets, enabling users to build sheets, analyze data, and generate formulas within spreadsheets. Anthropic has also significantly boosted its offerings, doubling the usage limits for all paid Claude plans by leveraging SpaceX's Colossus 1 data center. Furthermore, Claude Managed Agents received new capabilities like "Dreaming" for memory, "Outcomes" for success grading, and "Multi-agent orchestration." These developments collectively enhance accessibility and power for both free and paid AI users,…
Ben's Bites·news·05/07/2026, 01:03 PM
AI models follow their values better when they first learn why those values matter
A new Anthropic study shows that teaching AI models *why* certain values matter, before teaching specific behaviors, makes them significantly better at following those values in a…
A study from the Anthropic Fellows Program reveals a significant advancement in aligning large language models (LLMs) with intended values. Researchers discovered that training an LLM on texts explicitly explaining its desired values *before* teaching it specific behaviors leads to substantially better adherence to those principles. This "values-first" approach enables models to maintain their ethical guidelines more effectively, even when encountering novel situations not present in their initial training data. This method represents a crucial step in AI safety, moving beyond simple behavioral examples to instill a deeper understanding of underlying values, potentially leading to more robust and trustworthy AI systems.
The Decoder·news·05/07/2026, 12:45 PM·Maximilian Schreiner
Roblox Scientoloty Speedrun made with SuperGrok
See a humorous AI-generated video "speedrun" in a Roblox style, showcasing the creative capabilities of the SuperGrok tool for generating unique content.
A Reddit user, /u/ginadaspokemon, shared a unique AI-generated video titled "Roblox Scientoloty Speedrun" created with a tool called SuperGrok. This creative work showcases the potential of AI video generation to produce highly specific and humorous content. The video adopts a distinct Roblox-like aesthetic, demonstrating SuperGrok's capability to generate stylized narratives. It provides a concrete example of how AI tools can be leveraged by hobbyists and creative non-developers to create engaging and niche video content, moving beyond generic outputs. This highlights the evolving landscape of AI-powered creative expression in video.
r/aivideo·creative_work·05/07/2026, 12:36 PM·/u/ginadaspokemon
Moodboard 6 - Digital landscape
See a stunning "digital landscape" image created with Midjourney, complete with the exact parameters used for inspiration and experimentation.
Reddit user /u/Heath_co shared a captivating "Moodboard 6 - Digital landscape" image, showcasing the creative capabilities of Midjourney. The post includes the specific parameters used: --profile e762978 --v 8.1 --stylize 1000 --hd. This example highlights how precise parameter tuning can achieve distinct aesthetic results, particularly with a high stylize value and the --hd flag for enhanced detail. While not a new feature release, it provides a concrete instance of artistic expression and technical application for those exploring AI image generation. It serves as valuable inspiration for hobbyists and creative non-developers looking to replicate or adapt similar styles.
r/midjourney·creative_work·05/07/2026, 12:17 PM·/u/Heath_coHelp with Duet Voice Assignment in V5.5 (male/female alternating)
If you're using Suno AI v5.5 for duets, be aware that precise line-by-line voice assignment for multiple characters might be unreliable, often misassigning vocals despite detailed…
A user on Reddit is seeking help with inconsistent voice assignment in Suno AI v5.5, specifically when attempting to create duet or multi-character songs with alternating male and female vocals. Despite employing various prompting techniques, including explicit [Female Voice][Character] tags, style prompts like "vocals alternating male baritone and female soprano," and single-letter tags, the AI frequently misassigns lines, ignoring the specified character voices about 50% of the time. This issue highlights a current challenge in achieving precise vocal control within Suno AI, indicating that reliable line-by-line duet assignment remains an elusive feature for users. The problem persists even with the latest version, affecting complex musical compositions like music hall patter songs.
r/SunoAI·tooling·05/07/2026, 12:16 PM·/u/AloneTradition5725
[Melodic Metal + Chiptune] Mega Man X7 CODE CRUSH by Game HUB Metal Covers
Explore how SunoAI can be used to create sophisticated, genre-blending music covers, like this impressive melodic metal and chiptune rendition of a Mega Man X7 track.
A Reddit user on r/SunoAI shared a fan-made musical cover titled "[Melodic Metal + Chiptune] Mega Man X7 CODE CRUSH by Game HUB Metal Covers." This creative piece demonstrates the advanced capabilities of AI music generation tools like SunoAI to blend distinct genres, specifically melodic metal and chiptune, into a cohesive and engaging track. It showcases how hobbyists and creative non-developers can leverage AI to produce complex, stylized music covers, offering inspiration for personalized content creation. The piece highlights SunoAI's potential for generating specific stylistic elements and intricate arrangements from user prompts.
r/SunoAI·creative_work·05/07/2026, 12:07 PM·/u/Necessary_Olive_3027
Made this with Nano + Kling 3
See a user-generated AI video created with Nano and Kling 3 to get a sense of current creative capabilities and tool combinations in AI video generation.
A Reddit user, /u/Entire-Turnover-8560, posted an AI-generated video created using a combination of tools identified as "Nano" and "Kling 3". This submission on r/aivideo serves as a practical demonstration of current AI video generation capabilities, particularly for creative hobbyists interested in the output quality and stylistic potential of these models. While specific details about "Nano" are not provided, "Kling 3" likely refers to Kuaishou's advanced video generation model, known for its high-fidelity outputs. The post highlights how these tools can be combined to produce compelling visual content, offering inspiration for those exploring AI in creative workflows.
r/aivideo·creative_work·05/07/2026, 11:25 AM·/u/Entire-Turnover-8560
feat: Add Mimo v2.5 model support by AesSedai · Pull Request #22493 · ggml-org/llama.cpp
A new, powerful multimodal AI model, Mimo v2.5, with a massive 1M token context window and MoE architecture, is now supported by `llama.cpp`, making it accessible for local experi…
The popular `llama.cpp` project, known for enabling local inference of large language models, has officially added support for the new Mimo v2.5 model through a recent pull request. This significant update allows hobbyists and creative non-developers to run a highly advanced, multimodal Mixture of Experts (MoE) model on their consumer hardware. Mimo v2.5 features a sparse MoE architecture with 310B total parameters (15B activated), an exceptional 1M token context length, and comprehensive multimodal capabilities spanning text, image, video, and audio, supported by dedicated 729M-param vision and 261M-param audio encoders. This integration democratizes access to cutting-edge AI, making powerful local experimentation more feasible.
r/LocalLLaMA·model_release·05/07/2026, 11:23 AM·/u/jacek2023
The Acorn Throne (2026) lol
Check out this short, speculative AI-generated video titled 'The Acorn Throne (2026)' for a glimpse into creative AI applications.
A Reddit user, /u/Helpmefixit1234, posted a link to an AI-generated video titled "The Acorn Throne (2026)" on the r/aivideo subreddit. This submission highlights a creative application of AI in video generation, offering a speculative or humorous glimpse into potential future content. While specific details about the AI models or techniques used are not provided in the post, it serves as an example of how individuals are leveraging AI for artistic expression and conceptual storytelling. The "2026" in the title suggests a fictional or forward-looking narrative, adding an intriguing layer to the creative piece.
r/aivideo·creative_work·05/07/2026, 11:22 AM·/u/Helpmefixit1234
Google Deepmind takes a stake in EVE Online studio to test AI models
Google Deepmind is using EVE Online's complex social and economic systems as a massive sandbox to train and test advanced AI agents in human-like environments.
Google Deepmind has acquired a minority stake in CCP Games, the developer of the space MMO EVE Online, to use the virtual world as a testing ground for advanced AI models. Unlike previous Deepmind milestones in Go or StarCraft II, EVE Online provides a persistent, player-driven economy and complex social hierarchy that requires long-term strategic planning. This partnership suggests a shift toward training AI agents capable of navigating intricate human-like systems, markets, and social dynamics. The move could eventually lead to more sophisticated autonomous agents or NPCs within the game's ecosystem. It marks a significant step in using massive multiplayer environments for reinforcement learning at scale.
The Decoder·news·05/07/2026, 11:15 AM·Maximilian Schreiner
Claude's new "Dreaming" feature is designed to let AI agents learn from their mistakes
Claude agents can now "dream" by reviewing past sessions to clean up memory and distill new insights asynchronously, improving performance over time.
Anthropic has introduced a "Dreaming" feature for Claude Managed Agents, enabling them to refine their performance through asynchronous reflection. This process involves reviewing previous agent sessions to identify errors, remove redundant or outdated memory entries, and extract actionable insights for future tasks. Alongside this, Anthropic launched "Outcomes" and "Multiagent Orchestration" into public beta, focusing on goal-oriented evaluation and complex task delegation. Unlike standard memory, Dreaming allows agents to consolidate knowledge without manual intervention, effectively creating a self-improving loop. This update addresses the common issue of memory bloat and context degradation in long-running AI workflows.
The Decoder·tooling·05/07/2026, 10:59 AM·Matthias Bastian
DeepSeek nears $45bn valuation as China’s ‘Big Fund’ leads investment talks
DeepSeek is securing $45B in funding, ensuring they remain a dominant force in the open-weights LLM space for the foreseeable future.
DeepSeek, the developer of the highly efficient V3 and R1 models, is reportedly in talks for its first major investment round that could value the company at $45 billion. The funding is expected to be led by China’s National Integrated Circuit Industry Investment Fund, known as the 'Big Fund.' This move marks a significant shift as DeepSeek, previously funded by high-frequency trading firm High-Flyer Quant, seeks massive capital to scale its compute resources. The valuation would place DeepSeek among the world's most valuable AI startups, rivaling US-based giants like Anthropic. For the local LLM community, this suggests a long-term commitment to developing state-of-the-art models that often challenge proprietary alternatives.
r/LocalLLaMA·news·05/07/2026, 10:21 AM·/u/Nunki08Running Qwen3.5 / Qwen3.6 with NextN MTP (Multi-Token Prediction) speculative decode in llama.cpp — single RTX 3090 Ti GPU guide
Speed up Qwen 3.5/3.6 models by nearly 3x on a single GPU using NextN Multi-Token Prediction in llama.cpp with this specific build and quantization guide.
This technical guide details how to implement NextN Multi-Token Prediction (MTP) for the Qwen 3.5 and 3.6 model families using llama.cpp. By leveraging MTP, users can achieve approximately 2.9x faster decoding speeds with zero loss in output quality, as the prediction heads are natively integrated into these models. The process currently requires building llama.cpp from specific pull requests (#22400 and #22673) or using a provided fork. A critical step involves a specific quantization override (--tensor-type nextn=q8_0) to prevent output corruption. Benchmarks show the 35B MoE variant reaching an impressive ~150 tokens per second on a single RTX 3090 Ti.
r/LocalLLaMA·tutorial·05/07/2026, 09:56 AM·/u/yes_i_tried_google
I built a tool to mix two artists on one image with region masks — Van Gogh + Picasso, no training, arbitrary refs
Mix different artistic styles in specific parts of an image using masks and IP-Adapters without any training or fine-tuning.
A new open-source tool allows users to apply distinct artistic styles to specific regions of an image using spatial masks. Built on Stable Diffusion 1.5, the system utilizes ControlNet (Canny and Tile) for structural integrity and two IP-Adapters for style injection. The technical core involves spatial routing, where each adapter's contribution is masked within the cross-attention layers to prevent 'muddy' averaging of styles. It offers three modes: global mixing, painterly emphasis, and region-specific stylization. While effective, the author notes that aggressive style weights can distort realistic faces and small color details. The project includes a GitHub repository with a Colab notebook and a Hugging Face Space for testing.
r/StableDiffusion·tooling·05/07/2026, 09:24 AM·/u/Longjumping_Gur_937
Prompt share: heroine crash landing into mech transformation with a mechanical tiger
Learn how to prompt complex cinematic sequences involving crash landings and mechanical transformations in AI video tools.
This post on r/aivideo showcases a high-quality cinematic sequence generated using AI video tools, specifically focusing on a heroine's crash landing and subsequent transformation into a mechanical tiger. The author provides the exact prompt used, which is valuable for creators trying to master complex motion and object consistency. The video demonstrates significant progress in handling multi-stage actions within a single generation or sequence. By sharing the prompt, the creator offers a template for others to experiment with physics-heavy scenes and sci-fi transformations. This type of community sharing helps bridge the gap between simple text-to-video and professional-grade AI cinematography.
r/aivideo·creative_work·05/07/2026, 09:20 AM·/u/Accomplished-Tax1050Is anyone actually getting good results with Flux2.DEV?
If you're struggling to get sharp, realistic images from Flux2.DEV, you're not alone; a user reports consistent issues with hazy outputs and a limited LoRA ecosystem, seeking comm…
A Reddit user on r/StableDiffusion, /u/Extension-Yard1918, has reported persistent issues achieving sharp, realistic images with the Flux2.DEV model over several months of testing. Despite efforts like increasing resolution and step count, and experimenting with different samplers and settings, the generated outputs consistently appear hazy, soft, or foggy, failing to match the quality of models like Z-Image Turbo. The user also notes a weak image editing feature and a nearly nonexistent LoRA ecosystem, questioning if the problem lies with the model's training data, VAE, scheduler, or their own workflow. They are seeking practical advice and specific settings from the community to unlock Flux2.DEV's potential.
r/StableDiffusion·opinion·05/07/2026, 09:15 AM·/u/Extension-Yard1918
How Unreal Engine 5 indie game Beastro uses 'paper puppets' to reinvent RPG art
Learn how an indie studio uses Unreal Engine 5 to blend 2D 'paper puppet' aesthetics with 3D environments for a unique RPG look.
Beastro is an upcoming indie RPG that stands out by using a 'paper puppet' art style within Unreal Engine 5. Art director Kate Rado explains that the game's visuals are inspired by puppet theater and tactile, physical objects like food. Instead of traditional 3D modeling for characters, the team uses flat, illustrated assets that move like puppets, creating a charmingly weird atmosphere. This approach allows a small team to achieve a high-fidelity look without the overhead of complex 3D character animation. The project demonstrates how modern engines can be leveraged for non-photorealistic, highly stylized creative directions.
Creative Bloq·creative_work·05/07/2026, 09:00 AM· Alan Wen
So Far This is My Favorite Use-Case for LTX 2.3/ComfyUI
Discover a practical workflow for using the LTX 2.3 video model in ComfyUI to achieve high-quality, consistent video generation on local hardware.
The Reddit community is exploring the capabilities of LTX 2.3, a new video generation model, specifically within the ComfyUI node-based interface. This post demonstrates a high-quality use-case that highlights the model's strengths in temporal consistency and motion fidelity. LTX 2.3 is designed to be more accessible for local execution on consumer GPUs than previous state-of-the-art video models. The author's workflow provides a practical example of how to integrate this model into complex creative pipelines. This demonstration is particularly valuable for creators looking for alternatives to closed-source video tools like Runway or Luma.
r/StableDiffusion·tooling·05/07/2026, 08:33 AM·/u/optimisoprimeothe man next door
A high-quality example of AI-generated narrative horror, showcasing current capabilities in character consistency and atmospheric storytelling.
The Man Next Door is a short AI-generated video shared on the r/aivideo subreddit, focusing on a suspenseful, uncanny valley narrative. The piece demonstrates significant progress in maintaining character consistency and environmental details across multiple shots, a common challenge in AI cinematography. It utilizes a dark, cinematic aesthetic to evoke a sense of dread, highlighting how creators are moving beyond simple prompt-to-video clips toward structured storytelling. The creator likely employed high-end tools like Runway Gen-3 or Luma Dream Machine, given the fluid motion and lighting quality. This work serves as a benchmark for hobbyists looking to blend AI visuals with traditional suspense tropes.
r/aivideo·creative_work·05/07/2026, 08:18 AM·/u/Parallelkarma
testing LTX 2.3 1.1 distilled on my gpu. pretty much decent for creating ugc content or short tiktok vlog.
Distilled LTX 2.3 enables fast, high-quality local video generation on mid-range GPUs like the RTX 4060 Ti when paired with the latest CUDA/Torch updates.
A user on r/comfyui demonstrates the performance of the distilled LTX 2.3 1.1 model for generating short-form video content locally. The test highlights significant performance gains when using updated software stacks, specifically Torch 2.11.0 and CUDA 13.0. Running on consumer-grade hardware (RTX 4060 Ti 16GB), the model is capable of producing decent quality UGC and TikTok-style vlogs. The post includes a link to the specific ComfyUI workflow used for these results. This release represents a step forward in making high-quality video generation accessible on mid-range local GPUs.
r/comfyui·tooling·05/07/2026, 08:10 AM·/u/aziib
testing LTX 2.3 v1.1 distilled on my gpu. pretty decent for creating ugc content or short tiktok vlog.
LTX 2.3 v1.1 distilled runs efficiently on mid-range consumer GPUs (RTX 4060 Ti) for short video content when using updated Torch and CUDA drivers.
A user report demonstrates the performance of LTX 2.3 v1.1 distilled for creating short-form video content like TikTok vlogs. Running on an RTX 4060 Ti 16GB, the model shows significant speed improvements when paired with PyTorch 2.11.0 and CUDA 13.0 in ComfyUI. The distilled version of the model is specifically optimized for faster inference while maintaining enough quality for social media use cases. The post highlights the importance of driver and library updates for maximizing performance on consumer-grade hardware, making high-quality video generation more accessible.
r/StableDiffusion·tooling·05/07/2026, 08:10 AM·/u/aziibwhy llama.cpp can’t combine speculative decode methods?
Users are seeking to combine MTP and ngram speculative decoding in llama.cpp to maximize speed in coding tasks, but current implementation limits them to one method.
A technical discussion on r/LocalLLaMA highlights a current limitation in llama.cpp regarding speculative decoding methods. A user testing Qwen 3.6 27B with Multi-Token Prediction (MTP) found that while MTP is effective, combining it with ngram speculation would be ideal for agentic coding. Ngram is particularly fast at predicting repeated code blocks, which occurs frequently during file edits. Currently, llama.cpp only supports one speculative method at a time via command-line arguments. The community is exploring whether this is a fundamental architectural constraint or a temporary implementation hurdle that could be resolved to further boost local inference speeds.
r/LocalLLaMA·tooling·05/07/2026, 07:53 AM·/u/Qwoctopussythe part of using claude code nobody talks about
AI tools like Claude Code offer 'rented understanding': you ship fast but lose the deep knowledge required to maintain the code later.
The author reflects on the hidden cost of using Claude Code: the erosion of deep code ownership. While features are shipped in record time, the lack of cognitive resistance during the writing process means the developer doesn't truly internalize how the code works. This leads to a 'rented understanding' that evaporates shortly after the task is finished, making future debugging or refactoring difficult. The post warns that while demos focus on the speed of the 'green diff,' they ignore the long-term mental debt of living in a codebase you didn't mentally construct. Ultimately, the developer feels like a tenant in a house they didn't build, where someone else chose the wallpaper.
r/ClaudeAI·opinion·05/07/2026, 07:17 AM·/u/Consistent-Arm-875Creative Mission day #7: Festival Sunset Moment [Progressive house]
Learn how to craft sophisticated Progressive House tracks in Suno using specific musical terminology and systematic prompt variations.
This 'Creative Mission' post provides a comprehensive template for generating Progressive House music using Suno AI. It focuses on the 'festival sunset' vibe, utilizing technical terms like sidechain compression, Juno-style pads, and 909 hi-hats to guide the model effectively. The author includes three prompt variations to demonstrate how swapping a single element, such as an acoustic piano for an Oberheim synth, or removing vocals entirely, changes the emotional impact. Beyond prompts, it offers historical context on the genre and reference tracks like Eric Prydz’s 'Opus' for benchmarking. This is a high-quality example of how to move beyond simple prompts toward intentional sound design in AI music.
r/SunoAI·tutorial·05/07/2026, 07:00 AM·/u/Grenar
Claude's New "Infinite" Context Window Model, Doubled Rate Limits, Multi-Agent Cordination, & More!
Anthropic doubles Claude's rate limits and previews 'infinite' context windows alongside multi-agent orchestration for autonomous coding.
Anthropic’s 'Code with Claude' developer conference signaled a shift from chatbots to fully autonomous software engineering systems. The company announced a doubling of rate limits for all paid plans, supported by a massive new compute partnership with SpaceX involving 220,000 GPUs. New capabilities include multi-agent orchestration, where a lead agent delegates tasks to specialized sub-agents, and a 'dreaming' feature for iterative self-improvement based on past sessions. Looking ahead, Anthropic teased next-gen models featuring 'infinite' context windows and enhanced 'code taste' focused on maintainability. These updates aim to transform Claude into a persistent, long-horizon reasoning workforce for complex dev workflows.
AI Jason·news·05/07/2026, 06:44 AM·WorldofAI▶Watch here

Xyren New Cyberpunk action MV - "Ray Crash", a fusion of kpop and action film
A high-quality example of AI-driven music video production blending K-pop aesthetics with cyberpunk action, showcasing advanced character consistency.
This AI-generated music video titled 'Ray Crash' by Xyren showcases a sophisticated blend of K-pop visual styles and cyberpunk action sequences. The project demonstrates the current capabilities of AI video tools in maintaining character consistency and complex motion across multiple scenes. It serves as a benchmark for creators looking to fuse music and narrative action without traditional film crews. The visual fidelity suggests the use of advanced generative models, highlighting the shift toward AI-native entertainment and high-end digital production.
r/aivideo·creative_work·05/07/2026, 06:16 AM·/u/BlackPuppeteer
[AINews] Anthropic-SpaceXai's 300MW/$5B/yr deal for Colossus I, ARR growth is 8000% annualized
Anthropic scales up with a $5B compute deal using xAI's Colossus 1 and reports 80x revenue growth, alongside new features for Claude Managed Agents.
Anthropic's second annual developer event focused on massive infrastructure and business growth rather than a new model release. The headline is a strategic partnership with xAI, where Anthropic will utilize the Colossus 1 supercomputer in a deal valued at approximately $5 billion per year. This positions xAI as a "neocloud" provider for its competitors. Anthropic also reported a staggering 8000% annualized ARR growth and introduced three new features for Claude Managed Agents. While some expected a "Claude 4" announcement, the event served as a celebration of recent shipping velocity and a signal of the company's aggressive scaling trajectory.
Latent Space·news·05/07/2026, 05:57 AMBurned through my Claude limits in a weekend with Claude Design. Here's what I'd do differently
Optimize your Claude Design workflow by locking briefs in chat first and using visual references to save tokens and improve output quality.
A user shares seven practical lessons for mastering Claude Design while managing strict usage limits. The core advice is to finalize the creative brief and copy in standard Claude chat before moving to the design interface to save tokens. Key technical tips include setting up a design system (colors, fonts) immediately and using screenshots instead of descriptive adjectives to guide the AI. For developers, linking specific subdirectories rather than entire repositories prevents context lag and wastes less context window. Finally, the author emphasizes using built-in UI sliders for minor adjustments instead of wasting prompts on simple layout changes.
r/ClaudeAI·tutorial·05/07/2026, 05:12 AM·/u/Intelligent-Lynx-953
Google just turned this MMO into an AGI experiment
Robotics companies are using human teleoperation to bypass the data bottleneck, while Google explores MMOs like Eve Online to train AGI in complex social environments.
Wes Roth and Dylan Curious discuss the accelerating pace of humanoid robotics, highlighting Figure's achievement of producing one robot per hour. They explore 1X Technologies' strategy of using human teleoperators to perform household tasks, which serves as a data collection method to train autonomous models. The conversation also touches on Google DeepMind's interest in Eve Online as a training ground for AGI, given the game's complex social and economic systems. The hosts introduce the concept of "robotic slop"—low-level, repetitive household chores that robots could handle before achieving full manual dexterity. This "flywheel effect" suggests that early data collection through teleoperation will lead to exponential improvements in robotic autonomy.
Wes Roth·news·05/07/2026, 03:41 AM·Wes Roth▶Watch here
My Claude dreams at night and remembers everything. Better than mempalace.
A new open-source MCP server that gives Claude persistent long-term memory across sessions using local embeddings and background consolidation.
Developer /u/Mental-Spray-5263 has released iai-mcp, an open-source local daemon designed to provide Claude with persistent long-term memory across different sessions. The tool captures conversations and organizes them into three memory tiers, automatically feeding relevant context back into new chats without manual copy-pasting. It utilizes local neural embeddings for retrieval and AES-256 encryption for security, ensuring data stays private. A standout feature is background consolidation, where the system optimizes and links memories while the machine is idle. Performance benchmarks show over 99% verbatim recall and retrieval times under 100ms, with a session-start overhead of approximately 3,000 tokens.
r/ClaudeAI·tooling·05/07/2026, 03:08 AM·/u/Mental-Spray-5263THE BELL — Psychological WWII Horror Teaser 2
A high-quality teaser for an AI-generated WWII horror film demonstrating the cinematic potential of Runway's video generation tools.
This teaser, titled "THE BELL," showcases a psychological horror story set during World War II, created using Runway's generative video tools. The project highlights the increasing capability of AI to maintain consistent atmosphere, character design, and lighting across multiple shots. Unlike early AI videos characterized by heavy morphing, this piece demonstrates improved temporal stability and a deliberate cinematic aesthetic. It serves as a benchmark for independent creators looking to produce high-fidelity narrative content without traditional film budgets. The creator, Pinballerz, focuses on mood and historical texture to elevate the AI-generated imagery.
r/runwayml·creative_work·05/07/2026, 03:06 AM·/u/PinballerzQwen3.6 27B uncensored heretic v2 Native MTP Preserved is Out Now With KLD 0.0021, 6/100 Refusals and the Full 15 MTPs Preserved and Retained, Available in Safetensors, GGUFs and NVFP4s formats.
A high-performance, uncensored 27B model that successfully retains advanced Multi-Token Prediction (MTP) features for better local inference.
LLMFan46 has released 'heretic v2', an uncensored fine-tune of the Qwen3.6 27B model. This release is notable for preserving all 15 native Multi-Token Prediction (MTP) modules, which are frequently lost or degraded during the fine-tuning process. The model achieves a very low Kullback–Leibler divergence (KLD) of 0.0021, suggesting it maintains the original model's reasoning capabilities while eliminating refusals. With a refusal rate of only 6%, it is optimized for unrestricted local use. The model is available in multiple formats including Safetensors, GGUF, and NVFP4 to support various hardware setups.
r/LocalLLaMA·model_release·05/07/2026, 02:59 AM·/u/LLMFan46
ClaudePlaysPokemon Opus 4.7 run ongoing!
Watch Claude Opus 4.7 tackle Pokemon Red in real-time, demonstrating a massive leap in agentic efficiency and spatial reasoning compared to previous versions.
ClaudePlaysPokemon is a live benchmark project by an Anthropic employee where the latest Claude models play Pokemon Red without human help. The current run features the new Opus 4.7, which is showing a significant performance leap, reaching 5 badges in just 15,779 steps—three times faster than Opus 4.5. The model uses vision to navigate, maintaining its own notes and using spatial logic to solve mazes. Unlike competitors like GPT-5 or Gemini, this setup uses a lean harness with minimal tools, making it a purer test of raw model cognition. Viewers can watch the live reasoning trace to see how the LLM verifies wall coordinates and plans its next moves.
r/ClaudeAI·creative_work·05/07/2026, 02:54 AM·/u/mobcat_40Most lyric videos show lyrics too early — so I tested different pacing styles
Improve the emotional impact of your AI music videos by delaying lyric display to prevent viewers from reading ahead of the vocals.
A creator on r/SunoAI shared findings from testing different lyric pacing styles for AI-generated music videos. They observed that displaying lyrics too early causes viewers to read ahead, which diminishes the emotional impact of the vocals. The experiment compared four styles: early display, word-by-word, delayed cinematic, and karaoke-style sync. The delayed cinematic approach proved most effective, as it forces the audience to listen to the performance rather than just reading text. This subtle timing adjustment can make AI music videos feel more professional and immersive by prioritizing the auditory experience.
r/SunoAI·creative_work·05/07/2026, 02:33 AM·/u/Unlikely_Hyena1345
THE BELL — Psychological WWII Horror Teaser 2
A high-quality example of using AI video tools to create a cohesive, atmospheric psychological horror teaser set in WWII.
This post showcases the second teaser for THE BELL, a psychological horror project set during World War II, created using AI video generation tools. The video demonstrates significant progress in maintaining visual consistency and atmospheric storytelling within the AI video medium. It features eerie, photorealistic imagery of soldiers and supernatural elements, highlighting the potential for independent creators to produce cinematic-quality trailers. The project reflects the growing trend of AI cinema, where creators leverage generative models to bypass traditional production costs. While the specific tools used aren't listed in the snippet, the quality suggests advanced platforms like Kling, Runway Gen-3, or Luma Dream Machine.
r/aivideo·creative_work·05/07/2026, 02:29 AM·/u/Pinballerz
ParoQuant: Pairwise Rotation Quantization for Efficient Reasoning LLM Inference
ParoQuant is a new quantization method that preserves the reasoning and logic capabilities of LLMs at low bitrates better than standard techniques.
ParoQuant introduces Pairwise Rotation Quantization, a novel technique designed to minimize information loss during the compression of reasoning-heavy LLMs. Unlike standard quantization methods that often degrade complex logic chains, ParoQuant uses a pairwise approach to handle outlier weights more effectively. The release includes a dedicated GitHub repository and pre-quantized models on HuggingFace for immediate testing. This is particularly significant for users running large reasoning models on consumer hardware where VRAM is limited. Initial benchmarks suggest superior performance in maintaining Chain of Thought (CoT) coherence compared to traditional 4-bit methods.
r/LocalLLaMA·tooling·05/07/2026, 02:07 AM·/u/Total-Resort-3120
Never got good results from Klein? Me neither, til now
Stop using turbo LoRAs with Klein 9B; it achieves peak quality and speed with just 4 steps natively.
A user on r/comfyui discovered why many creators struggle to get high-quality results from the Klein 9B model. The issue stems from incorrectly applying turbo LoRAs or using too many sampling steps, which degrades the output. Klein 9B is designed to be natively fast and performs optimally with only 4 steps without any speed-up modifications. The post includes a downloadable ComfyUI workflow and clarifies licensing terms, stating that while outputs can be used commercially, the model itself requires a commercial license from Black Forest Labs for business use. This finding explains the polarizing reception of the model and provides a clear path to better prompt adherence and speed.
r/comfyui·tutorial·05/07/2026, 01:43 AM·/u/Support_Marmosetthe part nobody warns you about
AI lets you build prototypes at lightning speed, but the resulting technical debt and messy architecture can lead to weeks of painful debugging.
A developer shares a cautionary tale about the hidden costs of rapid AI-assisted development. While the initial prototype was built in just three days, the author spent the following two weeks trapped in a debugging hell caused by AI-generated technical debt. The post highlights issues like 800-line functions, poor naming conventions, and inconsistent state management that agents often introduce. It serves as a reminder that while AI can generate code quickly, the lack of architectural oversight leads to a codebase that feels like inheriting a house from someone who hated you. The author warns that the honeymoon phase of vibe coding is often followed by a grueling, repetitive maintenance phase that is rarely discussed.
r/ClaudeAI·opinion·05/07/2026, 01:05 AM·/u/aerofotoNeed advice on hardware purchasing decision: RTX 5090 vs. M5 Max 128GB for agentic software development
Choosing between Nvidia and Apple for local AI coding: RTX 5090 wins on raw speed for fast iterations, while M5 Max wins on memory capacity for massive codebases.
This discussion evaluates the trade-offs between the RTX 5090 and M5 Max (128GB) for local agentic software development using models like Qwen 3.6 27B. The RTX 5090 provides approximately 3x faster token generation, which is vital for rapid code iteration, but its 32GB VRAM limits context windows and quantization levels (Q4/Q5). Conversely, the M5 Max's 128GB of unified memory supports massive context and higher precision models, though at significantly lower speeds. The author considers a multi-agent setup where a high-level orchestrator manages faster sub-agents for codebase exploration. Technical factors like Multi-Token Prediction (MTP) and MLX optimizations are highlighted as potential game-changers for Apple Silicon's usability in agentic workflows.
r/LocalLLaMA·tooling·05/07/2026, 12:34 AM·/u/BawbbySmith
The Ballad of Broncosaurus
A high-quality example of AI-driven narrative storytelling, blending western aesthetics with prehistoric themes through multimodal generation.
The Ballad of Broncosaurus is a creative AI-generated music video shared on the r/aivideo subreddit that blends western aesthetics with prehistoric themes. The project demonstrates the current capabilities of multimodal AI storytelling by combining high-fidelity generative video with a thematic AI-composed soundtrack. While the specific tech stack is not disclosed by the author, the visual consistency and temporal stability suggest the use of advanced motion models like Runway Gen-3 or Kling. This piece serves as a benchmark for how individual creators can execute complex narrative concepts without a traditional production crew. It highlights the shift from simple prompt-to-video clips to structured, multi-scene narrative works.
r/aivideo·creative_work·05/07/2026, 12:24 AM·/u/HeadOpen4823
Clippy Reloaded - a really sarky useful Clipboard node with no click.
Streamline your ComfyUI workflow with a new clipboard node that automatically copies data without manual clicks.
Clippy Reloaded is a new custom node for ComfyUI designed to simplify data handling by automatically sending outputs to the system clipboard. Unlike standard clipboard nodes that require manual interaction, this version focuses on a "no-click" experience, triggering whenever a value passes through it. It features a humorous, sarcastic interface reminiscent of the classic Microsoft Office assistant. This tool is particularly useful for creators who frequently move prompts, seeds, or hex codes between ComfyUI and other applications. The node aims to reduce friction in repetitive creative tasks within the node-based environment.
r/comfyui·tooling·05/07/2026, 12:13 AM·/u/shootthesoundClippy Reloaded - a really sarky useful Clipboard node with no click.
Automatically import your system clipboard into ComfyUI workflows every time you queue a prompt, eliminating manual pasting.
Clippy Reloaded is a custom node for ComfyUI designed to streamline the process of getting text into your workflows. Instead of manually pasting text into a node, this tool automatically pulls whatever is currently in your system clipboard the moment you queue a prompt. This is particularly useful for users who frequently copy prompts, descriptions, or parameters from external websites or LLM chats. The node eliminates repetitive clicking and pasting, acting as a dynamic input source. It is available as an open-source repository on GitHub for easy integration into existing ComfyUI setups.
r/StableDiffusion·tooling·05/07/2026, 12:11 AM·/u/shootthesoundThree browser games built with Claude (25M plays). Two of them are 8,000-line HTML files.
You can build a viral, revenue-generating web business with zero prior coding experience by using Claude/Cursor, provided you focus on shipping and iteration.
A non-developer shared a case study of building three viral browser games (dialed.gg) using Claude and Cursor, reaching 25 million total plays and 200,000 daily active users. The first two games were massive 8,000-line single HTML files, proving that functional, complex apps can be built without following traditional software architecture. The project now generates low five-figure monthly revenue from ads, with operational costs around $3,500/month for AI and hosting. A key lesson is that Claude will not proactively refactor code; the user eventually had to migrate to Next.js and TypeScript to scale. This case study highlights the power of 'vibe coding' for rapid prototyping and monetization.
r/ClaudeAI·creative_work·05/07/2026, 12:09 AM·/u/gteehan
Pandora’s Box | A Greek Mythology AI Short Film
See how current AI video tools can be used to create a visually consistent narrative short film with high production value.
This AI-generated short film reimagines the myth of Pandora's Box through a series of highly detailed cinematic sequences. The creator utilizes advanced video generation models to achieve impressive visual consistency across different shots of characters and environments. It represents a growing trend in the AI video community of moving beyond random clips toward structured, narrative-driven storytelling. The aesthetic leans heavily into epic, dark fantasy visuals with high-fidelity textures and dramatic lighting. While the specific technical stack is not listed, the output highlights significant improvements in temporal stability and character rendering in generative tools.
r/aivideo·creative_work·05/07/2026, 12:06 AM·/u/Outside-Objective828
What If Ancient Japan Was Built in Deep Space | 4K Cinematic Journey
Explore a high-fidelity visual concept blending feudal Japanese aesthetics with sci-fi, showcasing the latest capabilities in AI-driven cinematic world-building.
This creative project, shared on the r/aivideo subreddit, presents a 4K cinematic exploration of a 'Space Japan' concept. The video utilizes advanced AI video generation tools to blend traditional architectural elements, like pagodas and torii gates, with futuristic deep-space environments. It serves as a benchmark for how far AI has come in maintaining stylistic consistency across complex, imaginative prompts. The creator focuses on high-resolution textures and atmospheric lighting to achieve a professional film look. While the specific tools used aren't detailed, the quality suggests the use of top-tier models like Sora or Kling. This work highlights the potential for solo creators to produce high-concept visual narratives without a massive VFX budget.
r/aivideo·creative_work·05/06/2026, 11:45 PM·/u/PenguinBWGet faster qwen 3.6 27b
Achieve 50 t/s on Qwen 3.6 27B with 100k context on a single RTX 3090 by using MTP GGUFs and a specific llama.cpp branch.
A user on r/LocalLLaMA shared a method to significantly boost inference speeds for the Qwen 3.6 27B model on consumer hardware. By utilizing Multi-Token Prediction (MTP) GGUF files and a specific pull request for llama.cpp, they achieved speeds of 50 tokens per second on an RTX 3090. The setup involves using Q4_K_M quantization for the model and Q4_0 for the K/V cache to fit a 100k context within 19GB of VRAM. The post includes a step-by-step guide for applying the PR and the exact server configuration flags needed. It also mentions a Mac-specific installation via Homebrew for similar performance gains.
r/LocalLLaMA·tooling·05/06/2026, 11:33 PM·/u/admajic
Expertly Kissed
A showcase of AI video's growing ability to handle complex human interactions like kissing without the typical 'melting face' artifacts.
This Reddit post showcases a high-fidelity AI-generated video focusing on a complex human interaction: kissing. Historically, AI video models have struggled with the physical contact and fluid dynamics of two faces merging, often resulting in visual artifacts or 'melting' effects. The video demonstrates significant progress in temporal consistency and realistic skin deformation. While the specific model used isn't explicitly named in the title, the quality suggests the use of latest-generation tools like Luma Dream Machine or Kling. This serves as a benchmark for how far video synthesis has come in handling intimate human movements.
r/aivideo·creative_work·05/06/2026, 11:18 PM·/u/theJunkyardGold
Ernie Image Lora training - my take
Practical insights and visual benchmarks for training LoRAs on the Ernie model, highlighting necessary adjustments to standard training workflows.
The author presents their findings and visual results from training a LoRA on the Ernie image model, a less common alternative to the Stable Diffusion ecosystem. The post includes specific technical insights into the training process, highlighting how hyperparameters like learning rate and rank need adjustment compared to standard SDXL workflows. Visual benchmarks provided via Imgur demonstrate the model's proficiency in handling complex architectural details and specific artistic styles. This contribution is particularly valuable for users looking to diversify their toolkit beyond mainstream models and understand the nuances of cross-architecture fine-tuning. It serves as both a technical guide and a proof-of-concept for the Ernie model's flexibility.
r/StableDiffusion·tutorial·05/06/2026, 10:53 PM·/u/malcolmrey
My Reference Latent Node including Auto Masking and Timesteps per image is out tomorrow
A new ComfyUI node simplifies character consistency with built-in auto-masking and granular timestep control for reference images.
A new custom node for ComfyUI, developed by /u/shootthesound, introduces advanced Reference Latent capabilities for image generation. The node stands out by integrating auto-masking directly, reducing the need for manual mask preparation or external nodes. It also allows users to define specific timesteps for each reference image, providing much finer control over how much influence a reference has during the diffusion process. This is particularly useful for maintaining character consistency or transferring specific styles without overriding the entire generation. The release represents a streamlined approach to complex multi-image conditioning workflows that previously required cumbersome setups.
r/comfyui·tooling·05/06/2026, 10:32 PM·/u/shootthesoundMy Reference Latent Node including Auto Masking and Timesteps per image is out tomorrow
A new ComfyUI node that offers precise control over reference images through auto-masking and per-image timestep scheduling.
Developer /u/shootthesound has released ReferenceLatentPlus, a new custom node for ComfyUI designed to refine how reference images influence generations. The tool introduces auto-masking capabilities and allows users to set specific timesteps for each reference image, providing granular control over when and how much a source image affects the output. It includes integrated VAE input and maximum resolution controls, simplifying the pipeline for piping multiple images directly into a workflow. This release addresses the need for more precise element extraction from source material without complex manual masking. The node is now publicly available on GitHub for integration into existing Stable Diffusion setups.
r/StableDiffusion·tooling·05/06/2026, 10:31 PM·/u/shootthesound
[WIP] ComfyUI Powered Klein 2 KV Edit i2i plugin (Chromium)
A browser sidebar plugin that lets you perform advanced image-to-image edits via ComfyUI using the Klein 2 KV model architecture.
Developer /u/deadsoulinside has released a Work-In-Progress (WIP) Chromium extension that integrates ComfyUI directly into the browser sidebar. The tool focuses on image-to-image (i2i) workflows using the Klein 2 KV architecture, which offers high prompt-based control over image manipulation. Users can create, save, and categorize custom prompts within the plugin's interface. To function, it requires a local ComfyUI instance with API mode and CORS enabled, specifically targeting the Flux-2-Klein 9B model and Qwen 3 text encoders. The project is open-source, serving as a template for others to build upon or port to Firefox.
r/StableDiffusion·tooling·05/06/2026, 10:12 PM·/u/deadsoulinsideUploaded Unsloth Qwen3.6-35B-A3B UD XL models with MTP grafted, here are the results
MTP (Multi-Token Prediction) can significantly speed up local LLM inference, but its effectiveness varies greatly depending on the model architecture and hardware setup.
User /u/havenoammo released GGUF versions of the Qwen3.6-35B-A3B model featuring 'grafted' Multi-Token Prediction (MTP) layers. While MTP previously showed 2-2.5x speedups on dense models like the 27B variant, results for this MoE (Mixture of Experts) version are more modest, ranging from a 6% to 50% increase in tokens per second. The performance seems highly dependent on the specific GPU configuration and quantization level (Q4 vs Q8). The release includes the isolated MTP layers and conversion scripts on HuggingFace, allowing the community to experiment with speculative decoding. These preliminary results suggest that MoE architectures might not benefit as uniformly from MTP as dense models do in current llama.cpp implementations.
r/LocalLLaMA·tooling·05/06/2026, 09:51 PM·/u/havenoammoKijai LTX 2.3 WIth 12 GB of VRam demo reel
You can now run the high-quality LTX 2.3 22B video model on a standard 12GB VRAM GPU using GGUF quantization and specialized ComfyUI workflows.
A user demonstrated that the LTX 2.3 22B video generation model can produce high-quality 8-second clips on consumer-grade hardware. By utilizing GGUF quantization and specific ComfyUI workflows developed by Kijai, the model fits within 12GB of VRAM, specifically tested on an RTX 3060 with 32GB of system RAM. This is a significant milestone as it brings state-of-the-art open-weight video generation to hobbyist setups. The shared resources include the GGUF model files and optimized workflows available on Civitai. This setup balances performance and accessibility, making long-form AI video generation more feasible for local execution without requiring enterprise-grade hardware.
r/comfyui·tooling·05/06/2026, 09:09 PM·/u/OfficeMagic1Acestep 1.5 XL Base Workflow?
Get the ComfyUI workflows for ACE-Step 1.5XL text-to-music generation, though be aware of potential vocal quality issues in the latest base version.
A user on r/comfyui has shared direct links to workflows for ACE-Step 1.5XL Base and ACE-Step 1.5 (4b LLM), which are models designed for text-to-music generation. While these workflows allow for integrated audio creation within ComfyUI, the author notes a significant drop in vocal quality in the 1.5XL version compared to the older 4b LLM variant. The issue persists across various prompts and default settings, resulting in audio that sounds low-bitrate or 'off'. This post serves as both a resource for those wanting to experiment with AI music and a warning about current technical limitations. It highlights the ongoing challenges in maintaining audio fidelity when scaling these specific generative models.
r/comfyui·tooling·05/06/2026, 08:48 PM·/u/uhf789Great results with Qwen3.6-35B-A3B-UD-Q5_K_XL + VS Code and Copilot
A complete, reproducible configuration for running Qwen 3.6-35B locally in VS Code, achieving ~100 t/s for high-quality coding tasks on consumer hardware.
A user on r/LocalLLaMA shared a highly successful local coding setup using the Qwen 3.6-35B model (MoE architecture) via llama.cpp on an AMD R9700 GPU. The post includes the exact startup command for the Vulkan server, a VS Code chatLanguageModels.json configuration, and a complex React/TypeScript prompt that generated a fully functional website. Performance metrics show generation speeds of ~100 tokens/second, though large 38k token prompts cause a 17-second prefill delay. The setup utilizes context checkpointing and flash attention to maintain efficiency. This serves as a practical blueprint for developers looking to replace paid coding assistants with local LLMs.
r/LocalLLaMA·tooling·05/06/2026, 08:47 PM·/u/supracodeHas anyone tried Zyphra 1 - 8B MoE?
Zyphra released ZAYA1-8B, a reasoning MoE that uses less than 1B active parameters to deliver high-end math and logic performance on local hardware.
Zyphra has announced the release of ZAYA1-8B, a new Mixture of Experts (MoE) model focused on reasoning and intelligence density. Despite having 8 billion total parameters, it utilizes fewer than 1 billion active parameters during inference, making it exceptionally efficient for local deployment. The developers claim it outperforms much larger open-weight models in mathematics and logic benchmarks. Notably, the model was trained using AMD hardware and leverages test-time compute to narrow the gap with frontier models like DeepSeek-V3.2. This release highlights a trend toward hyper-efficient, specialized reasoning models that prioritize logic over raw parameter count.
r/LocalLLaMA·model_release·05/06/2026, 08:39 PM·/u/appakaradiUniReasoner: Using LLMs as "Universal Reasoners" to Fix Prompt Alignment
UniReasoner improves image accuracy by letting an LLM critique its own visual draft before the final diffusion step.
UniReasoner is a new framework designed to solve the "understanding-generation gap" in text-to-image models. It leverages the fact that multimodal LLMs are better at verifying images than generating them from scratch. The system uses a three-stage pipeline where an LLM first creates a coarse visual draft using discrete tokens. It then performs a "grounded evaluation" to identify errors like incorrect object counts or missing elements. Finally, a diffusion model such as SANA uses the original prompt, the draft, and the critique to produce a highly accurate final image. This method moves beyond simple prompt rewriting by using SigLIP-based discretization for spatial reasoning.
r/StableDiffusion·model_release·05/06/2026, 08:39 PM·/u/Formal_Drop526
Age of Automata - Trailer for my Steampunk Series
A high-quality example of AI-driven world-building and cinematic storytelling in the steampunk genre, showcasing impressive visual consistency.
This Reddit post showcases a cinematic trailer for an AI-generated series titled 'Age of Automata.' The creator utilizes advanced generative video models to craft a cohesive steampunk aesthetic, featuring intricate mechanical designs and atmospheric environments. The project demonstrates the current capability of AI to maintain visual consistency across multiple shots, which remains a significant challenge in AI filmmaking. While the specific tools used are not explicitly detailed in the post, the visual fidelity suggests the use of high-end platforms like Runway Gen-3 or Luma Dream Machine. It serves as a benchmark for hobbyists looking to move from isolated clips to structured narrative content.
r/aivideo·creative_work·05/06/2026, 08:37 PM·/u/AdComfortable5161
The GB10 Solution Atlas is now open source, the inference engine made for the community with breakneck inference speeds (Qwen3.6-35B-FP8 100+ tok/s)
Atlas is a high-performance, Rust-based open-source inference engine that delivers 3x faster speeds than vLLM on Blackwell hardware by removing Python overhead.
Atlas is a newly open-sourced inference engine written in pure Rust and CUDA, designed to bypass the performance bottlenecks of the standard Python/PyTorch stack. Optimized for NVIDIA Blackwell (GB10) architecture, it achieves over 100 tokens per second on Qwen3.5-35B models using NVFP4 precision and Multi-Token Prediction (MTP). The engine features a lightweight 2.5GB Docker image with sub-2-minute cold starts and provides native support for OpenAI and Anthropic API formats. By rewriting the stack from HTTP handlers to kernel dispatch, the developers claim a 3x throughput increase over vLLM. Future updates aim to bring these optimizations to AMD Strix Halo and RTX 6000 Blackwell hardware.
r/LocalLLaMA·tooling·05/06/2026, 08:36 PM·/u/Live-Possession-6726
LTX 2.3 is pretty much all I use for video gen at this point -- Scene from my current story-driven fantasy project -- Info on process/workflow in comments.
LTX 2.3 is emerging as a top-tier choice for consistent, story-driven AI video, with practical workflows now available for independent creators.
A creator showcases a high-quality fantasy scene generated using LTX 2.3, a video generation model from Lightricks. The post highlights the model's capability for narrative-driven projects, with the author claiming it has become their primary tool for video production. Unlike typical AI video demos, this project focuses on temporal consistency and story-driven aesthetics rather than just visual spectacle. The author provides specific workflow details in the comments, offering insights into how to achieve professional-grade results. This indicates a growing maturity in open or accessible video models for independent creators.
r/StableDiffusion·creative_work·05/06/2026, 08:33 PM·/u/foxditMost people seem obsessed with token generation speed, but isn’t prefill the real bottleneck? Am I missing something?
For agentic workflows and large contexts, prefill speed (how fast the model 'reads' the prompt) is a bigger bottleneck than generation speed.
A technical discussion on r/LocalLLaMA highlights that while benchmarks prioritize generation speed (tokens/s), the prefill stage is the actual bottleneck for many advanced users. Prefill is the initial phase where the model processes the input prompt before generating the first token. For agentic workflows involving large codebases or long RAG contexts, waiting for the model to 'ingest' data takes significantly longer than reading the output. The author notes that even 15 t/s generation is acceptable, but slow prefill (e.g., 300 t/s on a Qwen 27B) creates noticeable lag. This suggests that hardware and software optimizations should prioritize prompt processing for professional, high-context use cases.
r/LocalLLaMA·opinion·05/06/2026, 08:02 PM·/u/wbulotIs there any interest for a Character dataset evaluation script ?
A new tool is being developed to help curate LoRA training datasets by detecting face mirroring and scoring image quality and variety.
A Reddit user has developed a Python script with a Gradio interface designed to optimize datasets for training LoRAs of real people. The tool addresses two specific problems: detecting mirrored faces to prevent unnaturally symmetrical results and providing a relevancy score based on image quality and variety. By filtering out redundant or low-quality images, the script aims to improve the final model's fidelity. While currently in the feedback stage, the author is gauging community interest before a public release. This could be a valuable utility for hobbyists struggling with manual dataset curation.
r/StableDiffusion·tooling·05/06/2026, 07:54 PM·/u/HumbleSousVideGeekExaggerated PCI-E bandwidth concerns?
PCIe bandwidth concerns for multi-GPU setups are likely exaggerated; even a 4.0 x4 link handles high-speed prefill for mid-range cards using vLLM and Tensor Parallelism.
A user on r/LocalLLaMA conducted benchmarks to test if PCIe bandwidth is a true bottleneck for multi-GPU local LLM setups on consumer hardware. Using two RTX 5060 Ti 16GB cards with vLLM and Tensor Parallelism (TP=2), they found that peak bandwidth during prefill reached only 3-4 GB/s. This represents about 50% of the capacity of a PCIe 4.0 x4 slot, suggesting that even limited chipset-connected slots are sufficient for mid-range cards. The test involved high-speed quants like NVFP4, achieving prefill rates up to 1700 t/s. These findings suggest hobbyists can scale to 3 or 4 GPUs using M.2 adapters without needing expensive workstation-grade motherboards.
r/LocalLLaMA·news·05/06/2026, 07:54 PM·/u/ziphnor
ZAYA1-8B: Frontier intelligence density, trained on AMD
ZAYA1-8B is a new 8B model that claims to outperform Llama 3.1 8B, proving that high-density intelligence can be achieved using AMD-based training stacks.
Zyphra has released ZAYA1-8B, a new language model designed to maximize intelligence density within the 8-billion parameter class. The model reportedly outperforms Llama 3.1 8B and Gemma 2 9B across several key benchmarks, including MMLU and GSM8K. Notably, ZAYA1-8B was trained entirely on AMD Instinct MI300X accelerators, showcasing a viable alternative to the NVIDIA-dominated training ecosystem. This release targets developers looking for high-performance models that can run efficiently on consumer hardware or edge devices. The architecture focuses on better data efficiency and architectural refinements to squeeze more reasoning capability out of fewer parameters.
r/LocalLLaMA·model_release·05/06/2026, 07:43 PM·/u/carbocation
Making a full length fantasy movie ( Magehold )
A showcase of how AI video tools are maturing from short experimental clips into full-length, consistent narrative filmmaking.
Independent creator MosskeepForest has unveiled 'Magehold', an ambitious project aiming to produce a full-length fantasy movie using AI video generation tools. The project demonstrates the current state of the art in maintaining visual consistency across multiple scenes, a significant challenge for generative video. It features high-fidelity character designs and expansive environmental storytelling, moving beyond the typical 5-second clips seen on social media. This effort represents a growing trend of 'solo-studio' productions where AI handles the heavy lifting of visual effects and cinematography. The release serves as a benchmark for how hobbyists can leverage current LLM and video models to build complex, long-form narratives.
r/aivideo·creative_work·05/06/2026, 07:36 PM·/u/MosskeepForest
Anyone else tried this RefineAnything LoRA? Pretty impressed so far
A new ComfyUI plugin and LoRA workflow for surgical image refinement, perfect for fixing text, logos, and small details without affecting the rest of the image.
The RefineAnything project provides a specialized LoRA and workflow for surgical image repairs, specifically targeting text, logos, and product labels. A new ComfyUI plugin, ComfyUI-RefineNode, has been released to automate the manual labor of mask preparation, reference alignment, and pasting back the refined region. The plugin is model-agnostic, meaning it can enhance any local detail repair workflow, not just the RefineAnything LoRA. It supports both scribble masks and bounding boxes, ensuring the rest of the image remains 100% untouched. A technical tip from the developer suggests avoiding the 'index_timestep_zero' method to prevent noticeable color shifts during the process.
r/StableDiffusion·tooling·05/06/2026, 07:32 PM·/u/liangkun43
Google's Design.md is a design team in a file
Use .md files to store your design system's DNA (typography, colors, motion) and attach them to AI agent prompts to ensure consistent, high-end aesthetics across your entire app.
Greg Isenberg and designer Meng To discuss 'design.md,' a workflow that uses structured Markdown files to define a project's visual DNA for AI agents. By providing specific instructions on typography, spacing, and motion in an .md file, builders can prevent 'design drift'—the tendency for AI-generated UI to become generic after the initial prompt. The method allows non-designers to maintain consistency across different platforms like Lovable, Cursor, and v0. Meng To emphasizes that while 'vibe-coding' is popular, professional results require a 'design memory' that the AI can reference. This approach bridges the gap between high-level creative vision and the technical execution of AI-assisted development.
Greg Isenberg·tooling·05/06/2026, 07:13 PM·Greg Isenberg▶Watch here

OpenAI built a networking protocol with AMD, Broadcom, Intel, Microsoft, and NVIDIA to fix AI supercomputer bottlenecks
OpenAI and tech giants released MRC, an open-source protocol that makes training massive models faster and cheaper by optimizing how 100,000+ GPUs communicate.
OpenAI, in collaboration with industry leaders like NVIDIA, Microsoft, and AMD, has introduced MRC (Multi-Path Remote Communication), an open-source networking protocol designed for AI supercomputing. The protocol addresses the massive data bottlenecks inherent in training LLMs across tens of thousands of GPUs. By enabling data transmission across hundreds of paths simultaneously, MRC reduces the required network switch layers from four down to just two. This architecture supports clusters of over 100,000 GPUs while significantly lowering power consumption and hardware costs. Currently, the protocol is operational within OpenAI's Stargate supercomputer project, signaling a shift towards more efficient, standardized AI infrastructure.
The Decoder·tooling·05/06/2026, 07:13 PM·Matthias BastianvLLM V0 to V1: Correctness Before Corrections in RL
vLLM V1 is a major upgrade optimized for RL and reasoning models, focusing on output correctness and significantly better inference performance.
vLLM is transitioning from V0 to V1, marking a major architectural overhaul focused on Reinforcement Learning (RL) workflows. The update emphasizes a 'Correctness Before Corrections' philosophy, addressing the critical need for high-fidelity outputs in complex reasoning tasks. This shift is particularly relevant for serving modern models like DeepSeek-R1 that rely on long-chain reasoning and RL-based optimization. The new version aims to significantly reduce overhead and improve throughput while maintaining strict output validation. It represents a move towards more robust, production-ready inference for the next generation of agentic and reasoning LLMs.
Hugging Face Blog·tooling·05/06/2026, 07:06 PM
Anthropic taps SpaceX's Colossus-1 data center for 220,000 GPUs to power Claude
Anthropic is scaling up massively by leasing SpaceX's Colossus-1 data center, which will double Claude Code rate limits and boost API capacity for Opus models.
Anthropic is taking over the full computing capacity of SpaceX's Colossus-1 data center, utilizing over 220,000 NVIDIA GPUs and 300 megawatts of power. The facility is expected to be operational within a month, providing a massive boost to Anthropic's training and inference capabilities. Consequently, the company is doubling rate limits for Claude Code and increasing API limits for its high-end Opus models. This scale of infrastructure suggests that Anthropic is gearing up for the release of significantly more powerful frontier models. The partnership highlights the intensifying competition for massive-scale compute resources in the AI industry.
The Decoder·news·05/06/2026, 06:42 PM·Matthias Bastian
[Z-Image] REALSTAGRAM_ZIMG — subtle realism LoRA for Z-Image Turbo (works with any character LoRA)
Enhance Z-Image Turbo generations with a subtle, candid Instagram realism LoRA that stacks perfectly with character models.
REALSTAGRAM_ZIMG is a new realism-enhancing LoRA specifically designed for the Z-Image Turbo and De-Turbo models. It aims to shift image outputs away from the typical "AI-perfect" look toward a more amateur, candid Instagram aesthetic. The LoRA is lightweight (Rank 64, 325 MB) and does not require a trigger word, making it easy to integrate into existing prompts. It is optimized for stacking with character LoRAs at a strength of 0.2 to 0.6 to maintain character identity while adding subtle texture and lighting improvements. A ComfyUI workflow is provided to help users get started immediately.
r/StableDiffusion·tooling·05/06/2026, 06:35 PM·/u/Existing-House1230
Interactive Video Generation (Causal Forcing) - High Speed!
Generate high-speed interactive videos even on mid-range GPUs like the RTX 3060, with potential for real-time performance on high-end hardware.
Causal Forcing is a new approach to interactive video generation that emphasizes speed and efficiency. The release includes open-source code and models, with a community-repackaged version for ComfyUI. Performance benchmarks show that an RTX 3060 can generate a 2-second video (848x480) in just 11 seconds using only 4 steps. On high-end GPUs like the RTX 4090 or 5090, users report near real-time generation speeds. The model is lightweight, peaking at 6GB VRAM, making it accessible for hobbyists with mid-range hardware. This represents a significant step toward fluid, interactive AI video tools.
r/StableDiffusion·model_release·05/06/2026, 05:53 PM·/u/ZerOne82
GOLDEN AXE THE MOVIE
A high-quality fan trailer for a hypothetical Golden Axe movie, showcasing current AI video generation capabilities in fantasy world-building.
This fan-made project reimagines the classic Sega beat 'em up Golden Axe as a cinematic live-action movie trailer. The creator uses advanced AI video generation tools to bring iconic characters like Ax Battler, Tyris Flare, and Gilius Thunderhead to life with impressive visual consistency. The video demonstrates how AI can now handle complex fantasy aesthetics, including magic effects, mythical creatures, and period-accurate armor. Unlike earlier AI videos, this piece shows improved temporal stability and a cohesive art direction that mirrors 80s and 90s high-fantasy cinema. It serves as a benchmark for how hobbyists can prototype intellectual property adaptations without a Hollywood budget.
r/aivideo·creative_work·05/06/2026, 05:20 PM·/u/Feeling_Painting_281
New in Claude Managed Agents: dreaming, outcomes, multiagent orchestration, and webhooks.
Build smarter, self-improving agent workflows with new memory ('dreaming'), quality-check ('outcomes'), and multi-agent features on the Claude Platform.
Anthropic has introduced significant updates to Claude Managed Agents, focusing on long-term performance and reliability. The standout feature, 'Dreaming', allows agents to review past sessions and curate memories, reportedly increasing task completion rates by 6x in early tests. 'Outcomes' introduces a rubric-based grading system where a separate agent validates work and forces iterations until quality standards are met. Additionally, multiagent orchestration now supports parallel processing by delegating tasks to specialized sub-agents. These tools, along with new webhook support, move Claude closer to an autonomous, production-ready platform for complex business logic.
r/ClaudeAI·tooling·05/06/2026, 05:12 PM·/u/ClaudeOfficialAnthropic Just Secured a Reserve.
Anthropic is massively scaling its training power by securing 220,000+ NVIDIA GPUs through a new partnership with SpaceX.
Anthropic has announced a strategic partnership with SpaceX to utilize the full compute capacity of the Colossus 1 data center. This agreement grants Anthropic access to over 300 megawatts of power and a massive deployment of more than 220,000 NVIDIA GPUs, expected to be online within the month. This scale of infrastructure is significantly larger than most current AI clusters, indicating a massive push for the next generation of Claude models. The move highlights the intensifying arms race for compute resources among top-tier AI labs. By securing this reserve, Anthropic ensures it has the hardware necessary for training and serving increasingly complex frontier models.
r/ClaudeAI·news·05/06/2026, 05:05 PM·/u/DragonflyOk7139
Raiders of the Lost Clump; Claypocalypse now; Top Gum, and others
Impressive showcase of AI-driven claymation parodies, demonstrating high stylistic consistency and texture fidelity in video generation.
This post showcases a series of AI-generated video parodies of iconic films like Indiana Jones and Top Gun, reimagined in a detailed claymation aesthetic. Created by Breaking_Clay_Labs, the videos demonstrate a high level of temporal consistency and stylistic fidelity, which are often difficult to achieve in AI video generation. The clay texture and movement mimic traditional stop-motion techniques effectively, providing a blueprint for creators looking to replicate specific physical mediums. It highlights the evolving capability of video models to handle complex textures and character movements without losing the intended hand-crafted feel.
r/aivideo·creative_work·05/06/2026, 04:46 PM·/u/Breaking_Clay_LabsHigher usage limits for Claude and a compute deal with SpaceX
Claude users will see significantly higher message limits thanks to a major infrastructure and compute partnership between Anthropic and SpaceX.
Anthropic has announced a significant increase in usage limits for Claude Pro and Team users, addressing a primary pain point for power users. This capacity boost is fueled by a new strategic partnership with SpaceX to secure massive compute resources and infrastructure. While the technical specifics of the SpaceX deal remain under wraps, it likely involves leveraging SpaceX's expertise in rapid infrastructure deployment and power management for data centers. This move allows Anthropic to better compete with OpenAI's scale and reduces the frequency of 'limit reached' messages during intensive tasks. The collaboration signals a shift where AI labs seek unconventional infrastructure partners to bypass traditional cloud bottlenecks.
r/ClaudeAI·news·05/06/2026, 04:38 PM·/u/Dependent_Top_8685
Analysis of the 100 most popular hardware setups on Hugging Face
See which GPUs actually dominate the AI landscape, from enterprise A100s to the consumer RTX 4090s favored for local LLM execution.
Hugging Face CEO Clement Delangue released an analysis of the top 100 hardware configurations used on the platform. The data underscores NVIDIA's market capture, with the A100 and H100 leading for heavy workloads, while the RTX 3090 and 4090 remain the top choices for local enthusiasts. This report offers a factual look at the compute landscape, moving beyond hype to show what hardware is actually accessible to developers. It highlights the importance of VRAM capacity for running modern LLMs locally. For the creative-tech community, this serves as a benchmark for building and optimizing tools that fit the most common user profiles.
r/LocalLLaMA·news·05/06/2026, 04:35 PM·/u/clem59480Peak hours limit reduction gone thanks to partnership with SpaceX
Claude users can now enjoy unlimited access even during peak hours thanks to a new infrastructure partnership with SpaceX.
Anthropic has announced a strategic partnership with SpaceX to eliminate usage limits during peak hours for Claude users. This collaboration likely leverages SpaceX's Starlink satellite constellation to enhance global connectivity and infrastructure resilience. For power users, this means consistent access to high-end models without the common 'capacity reached' interruptions during busy workdays. The move represents a significant shift in how AI providers scale their backend to meet massive concurrent demand. By integrating with satellite-based infrastructure, Anthropic aims to provide a more reliable service compared to competitors relying solely on traditional terrestrial data centers.
r/ClaudeAI·news·05/06/2026, 04:25 PM·/u/neilmcd
SpaceX Conpute Deal - Double Limits
Anthropic partners with SpaceX to boost compute capacity, removing peak-hour limits for Claude Code and raising API rate limits for Opus models.
Anthropic has announced a strategic partnership with SpaceX to significantly expand its computational infrastructure. This deal addresses capacity constraints that previously limited high-end users and developers. Key updates include the removal of peak-hour usage restrictions for Claude Code on Pro and Max plans, ensuring more consistent performance throughout the day. Furthermore, API rate limits for the Opus model family have been substantially increased. This infrastructure boost indicates Anthropic's commitment to scaling its most resource-intensive models to meet professional demand.
r/ClaudeAI·news·05/06/2026, 04:24 PM·/u/Deep_Proposal_7683Claude just saved me from sending money to a scammer and now I feel 90 years old
Use Claude as a second pair of eyes for suspicious emails; it's surprisingly good at spotting subtle social engineering and phishing tactics.
A Reddit user shared a story about how Claude identified a highly sophisticated vendor impersonation scam that nearly succeeded. The phishing email mimicked the vendor's writing style and referenced real projects, making it difficult for a human to detect. Claude analyzed the text and flagged specific manipulation tactics, such as artificial urgency and unusual payment routing. This highlights the growing necessity of using LLMs as a defensive layer against AI-generated or highly targeted social engineering. The incident underscores a shift where AI is becoming an essential tool for personal cybersecurity verification.
r/ClaudeAI·news·05/06/2026, 04:14 PM·/u/Proof-Wrangler-6987
Made a music video in Runway with Seedance+Suno. All based from one of my Sora 2 clips.
A high-quality music video demonstration showing a complex AI pipeline involving Sora 2, Seedance, and Suno for synchronized motion and audio.
This creative showcase by user /u/Riot87 demonstrates a multi-stage AI production pipeline for music videos. The creator started with base footage generated in Sora 2, then utilized Seedance for motion synchronization and Suno for the musical score. Final assembly and refinement were handled within Runway. This workflow highlights the shift from single-prompt generation to complex, multi-tool orchestration to achieve professional-looking results. It serves as a benchmark for what is possible when combining specialized generative models for video, dance, and audio in a cohesive project.
r/runwayml·creative_work·05/06/2026, 04:11 PM·/u/Riot87
DeepSeek V4 AI Beats Billion Dollar Systems…For Free
DeepSeek V4 is a powerful new open-source AI model that reportedly outperforms expensive commercial systems, offering advanced capabilities for free.
DeepSeek has released its new AI model, DeepSeek V4, which is being highlighted for its impressive performance. The model reportedly surpasses the capabilities of much larger and more expensive "billion-dollar" proprietary systems, yet it is available for free. This release signifies a notable advancement in the open-source LLM landscape, potentially democratizing access to high-tier AI capabilities. For creative non-developers and hobbyists, this means access to a powerful tool without significant financial investment, pushing the boundaries of what's achievable with freely available AI.
Two Minute Papers·model_release·05/06/2026, 04:07 PM·Two Minute Papers▶Watch here

Google speeds up Gemma 4 threefold with multi-token prediction
You can now generate text with Google's Gemma 4 models up to three times faster thanks to a new multi-token prediction technique.
Google has introduced multi-token prediction drafters for its Gemma 4 open model family, significantly accelerating text generation. This new feature allows Gemma 4 models to generate text up to three times faster than before. The technique involves a smaller auxiliary model that proposes several tokens simultaneously, which the main Gemma model then validates in a single pass. This enhancement provides a substantial performance boost for users working with Gemma 4, making it more efficient for various creative and development tasks.
The Decoder·model_release·05/06/2026, 04:05 PM·Matthias Bastian
LTX2.3 + ID LoRS + Prompt relay + Keyframes
Discover a powerful, all-in-one workflow for Stable Diffusion that simplifies creating AI videos with consistent characters, dynamic prompts, and advanced animation techniques.
A Reddit user, /u/Brief-Leg-8831, shared a comprehensive workflow on Civitai for generating advanced AI videos using Stable Diffusion. This 'all-in-one' setup integrates several powerful techniques including LTX2.3, ID LoRA for character consistency, Prompt relay for dynamic narrative progression, ControlNet for precise pose control, and Keyframes for animation timing. The workflow also incorporates a detailer, upscaler, and custom audio synchronization, offering a robust solution for creating complex and high-quality AI-generated video content. It addresses common challenges in AI video production by combining multiple tools into a streamlined process.
r/StableDiffusion·tooling·05/06/2026, 04:03 PM·/u/Brief-Leg-8831
Ella - [AI orchestrated music video generation | more info in comments]
Discover how AI can orchestrate and generate entire music videos, offering a new avenue for creative expression and automated visual storytelling synchronized with audio.
User /u/TasTepeler showcased "Ella," an AI-orchestrated music video generation project on r/aivideo. This initiative demonstrates a sophisticated approach to creating music videos where artificial intelligence manages the synchronization and visual composition in response to audio. The project highlights the growing capability of AI to move beyond simple image or video generation towards more complex, integrated creative tasks. It represents a significant step in automating the labor-intensive process of music video production, offering creative non-developers and hobbyists a glimpse into future possibilities for dynamic visual content creation.
r/aivideo·creative_work·05/06/2026, 04:01 PM·/u/TasTepelerLive blog: Code w/ Claude 2026
Get real-time technical insights and roadmap updates from Anthropic's 2026 developer event via Simon Willison's live notes.
Simon Willison provides live-blog coverage of Anthropic's 'Code w/ Claude' event in May 2026. The keynote sessions focus on the evolution of Claude Code and the broader ecosystem of AI-driven development tools. This report captures real-time announcements regarding model updates, new developer APIs, and Anthropic's strategy for autonomous coding agents. It serves as a crucial primary source for understanding how the industry leader in coding LLMs is positioning itself for the year. The blog format offers granular insights and technical details that often precede official press releases.
Simon Willison's Weblog·news·05/06/2026, 03:58 PM
LTX2.3 + Prompt relay + Keyframes | 2027 ChatGPT self awareness event 😝
Master complex video transitions in ComfyUI using a comprehensive LTX2.3 workflow that integrates prompt relaying and keyframe control.
A new advanced ComfyUI workflow for the LTX2.3 video model has been shared, focusing on the synergy between prompt relaying and keyframes. The setup allows for complex narrative transitions and visual consistency by chaining prompts and managing motion via keyframes. Beyond basic generation, the workflow integrates ID LoRA for character consistency, ControlNet for structural guidance, and a detailer/upscaler pass for high-quality output. It also includes support for custom audio synchronization. While the author notes that the results can be finicky, the provided Civitai link offers a complete all-in-one solution for creators looking to push the boundaries of AI video.
r/comfyui·tooling·05/06/2026, 03:57 PM·/u/Brief-Leg-8831[Release] PaperStrip_FX COMP | An experimental scan-like strip compositor
A new experimental ComfyUI node for creating stylized 'paper strip' or 'scan-line' visual effects in AI-generated images and videos.
PaperStrip_FX COMP is an experimental tool released for ComfyUI that introduces a unique scan-like strip compositing effect. Developed by user TasTepeler, this node allows artists to slice and rearrange images into horizontal or vertical strips, mimicking physical paper collages or digital scanning glitches. It provides a creative way to post-process AI-generated content directly within the ComfyUI environment, eliminating the need for external video editing software for these specific visual styles. The release includes the workflow and custom nodes necessary to implement these transitions or static effects. This tool is particularly useful for creators seeking lo-fi, analog aesthetics in their digital generative workflows.
r/comfyui·tooling·05/06/2026, 03:56 PM·/u/TasTepeler
Follow-up: Trying to make NVIDIA GPUs plug-and-play on Macs. Found hidden RDMA symbols Apple doesn't want you to see — zero-copy GPU memory sharing might already work.
Hidden macOS features suggest Apple is preparing for zero-copy GPU memory sharing, potentially allowing NVIDIA eGPUs to work seamlessly with Mac AI clusters.
A researcher has discovered hidden RDMA (Remote Direct Memory Access) capabilities in macOS while attempting to make NVIDIA Blackwell GPUs work via Thunderbolt 5. By reverse-engineering libibverbs.dylib, the author found that Apple's RDMA subsystem already supports zero-copy memory sharing with Metal GPU buffers, a feature previously undocumented. This means data can move from an Apple GPU to a network cluster without intermediate CPU copies. Furthermore, hidden symbols like ibv_reg_dmabuf_mr suggest that Apple is internally preparing for GPUDirect RDMA, which would allow external NVIDIA VRAM to integrate directly into the Mac's memory fabric. While currently blocked by NVIDIA GSP firmware initialization issues on TB5, the discovery paves the way for massive hybrid AI clusters combining A…
r/LocalLLaMA·tooling·05/06/2026, 03:27 PM·/u/Street-Buyer-2428
These pirates are getting ambitious
High-fidelity AI video is reaching a point where cinematic character consistency and complex environments are becoming accessible to solo creators.
This Reddit post showcases a high-quality AI-generated video featuring a pirate theme, demonstrating the current state of cinematic AI video generation. The video displays complex lighting, character consistency, and fluid motion that were difficult to achieve just months ago. While the specific tools used aren't explicitly detailed in the snippet, the output quality suggests the use of advanced models like Kling, Luma Dream Machine, or Runway Gen-3 Alpha. It serves as a benchmark for what independent creators can now produce in terms of visual storytelling without a traditional VFX budget. The clip highlights the ambitious nature of AI creators pushing for feature-film aesthetics.
r/aivideo·creative_work·05/06/2026, 03:24 PM·/u/NaturalSelectyHOT TAKE: local models + agent harnesses are now capable enough to hand off junior-level IT professional tasks to [human written]
Local models like Qwen3.6 combined with agent harnesses are now capable of autonomously handling complex, multi-step IT administration tasks previously reserved for humans.
An IT veteran with 30 years of experience reports that local LLMs have reached a tipping point for practical automation. Using Qwen3.6 27b within the Hermes Agent harness, the user successfully automated a series of junior-level tasks: system patching, Docker installation, and setting up multiple GitHub repositories with local model services. The agent completed in 90 minutes what typically takes a human three hours, demonstrating the ability to troubleshoot errors and request approvals autonomously. The post suggests a future where 'admin agents' are embedded in infrastructure, fundamentally changing the labor ratio in IT departments. This highlights the shift from simple chat interfaces to tenacious agentic loops that can execute real-world system commands.
r/LocalLLaMA·tooling·05/06/2026, 03:21 PM·/u/Porespellar
Thanks to the sub my silly node and workflow got 3k downloads overnight, therefore I fixed some bugs, unified some features, and uploaded the latest and the greatest version to HF.
A new ComfyUI node that automates character consistency and scene composition using a structured Qwen-based procedural prompting system.
The ComfyUI Character Composer is a procedural prompt system designed to streamline character consistency and scene composition. Built upon the Qwen-Image-Edit-Rapid-AIO ecosystem, it provides a structured approach to generation, reducing the need for manual LLM prompting or copy-pasting. The tool features a unified txt2img and img2img workflow and utilizes a SFW JSON library for managing assets. Following a viral reception on Reddit with over 3,000 downloads, the developer has updated the node with bug fixes and unified features. It aims to offer more controllable generation for users working with complex character-driven workflows.
r/StableDiffusion·tooling·05/06/2026, 03:14 PM·/u/Mundane-Ad-5737
The promise and panic of Unity AI’s open beta rollout explained
Unity's AI tools (Muse and Sentis) enter open beta, offering generative assets and on-device model execution, while sparking debate over game quality.
Unity has launched the open beta for its AI suite, primarily featuring Unity Muse for asset generation and Unity Sentis for deploying neural networks on end-user devices. Muse allows developers to generate textures, sprites, and animations via natural language prompts, aiming to accelerate prototyping. Sentis is particularly notable as it enables running LLMs or other models locally within the game engine across multiple platforms. The rollout has sparked a polarized reaction in the gamedev community, with some praising the efficiency and others fearing a surge of 'AI slop' or low-effort content. This move represents Unity's attempt to democratize complex game systems while navigating the ethical and aesthetic concerns of generative AI.
Creative Bloq·tooling·05/06/2026, 03:00 PM· Ian DeanVibe coding and agentic engineering are getting closer than I'd like
As AI agents become more reliable, the focus of software quality is shifting from 'clean code' to 'proven real-world usage' and human-led architectural oversight.
Simon Willison explores the blurring lines between 'vibe coding' (non-expert, result-oriented) and 'agentic engineering' (professional, process-oriented). He admits that as tools like Claude Code improve, even experienced engineers are tempted to skip line-by-line reviews, treating agents as 'black box' internal teams. This shift challenges traditional software evaluation; since AI can generate perfect-looking READMEs and tests in minutes, real-world usage becomes the only true metric of quality. Willison also notes that while productivity has jumped from 200 to 2,000 lines a day, the inherent complexity of software remains a barrier that still requires human expertise to navigate safely.
Simon Willison's Weblog·opinion·05/06/2026, 02:24 PMQwen3.6 27B NVFP4 + MTP on a single RTX 5090: 200k context working in vLLM
You can now run Qwen3.6 27B with a massive 200k context window on a single RTX 5090 using NVFP4 quantization and vLLM.
A user successfully ran Qwen3.6 27B on a single RTX 5090 with 32GB VRAM, achieving a stable 200k context window. The setup utilizes NVFP4 quantization via the compressed-tensors library and vLLM's MTP (Multi-Token Prediction) for speculative decoding. Benchmarks show generation speeds between 65-75 tokens/second at 200k context, with TTFT (Time To First Token) dropping significantly when using prefix caching. This configuration demonstrates the potential of Blackwell's FP4 support for handling large-scale local inference. The author provides exact vLLM parameters and stability data for others to replicate the results on consumer hardware.
r/LocalLLaMA·tooling·05/06/2026, 02:05 PM·/u/Maheidem
Release: LoRA Lister + Trigger happy: local LoRA stacks, list testing, and prompt sync *Link inside*
Manage and test multiple LoRAs easily in ComfyUI with automatic trigger word syncing, stack saving, and sequential batch testing.
LoRA Lister and Trigger Happy are new custom nodes for ComfyUI designed to streamline LoRA management. LoRA Lister allows users to create, save, and reorder stacks of LoRAs with individual strength controls and visual state indicators. It features a List mode for batch-testing an entire library by stepping through models one by one. The tool automatically fetches metadata, including trigger words and preview images, from CivitAI and caches them locally. Trigger Happy complements this by automatically injecting relevant trigger words into the prompt and offering advanced text encoding features. It can also extract prompts from existing images and handle complex prompt merging.
r/comfyui·tooling·05/06/2026, 01:57 PM·/u/KitchenTight7894
Kindergarten-grade nouns
Claude Opus struggles with distinguishing between words people recognize and words they frequently use, revealing a bias in its training data towards written production frequency…
A Reddit user, /u/babelphishy, discovered a significant limitation in Claude Opus's understanding of human vocabulary familiarity while developing a word game. Opus struggles to differentiate between words adults recognize (like "stethoscope" or "campanile") and those they frequently use or write about. This issue stems from its training corpus (Wikipedia, news, Reddit, Twitter) being heavily skewed towards production frequency (Zipf's law), rather than general recognition. The model therefore undervalues words learned in school but rarely posted online, leading to an inaccurate assessment of a word's "obscurity" for a typical human. This insight highlights a crucial bias in LLM training data and its impact on nuanced language understanding.
r/ClaudeAI·news·05/06/2026, 01:46 PM·/u/babelphishy
ChatGPT ads are now open to small businesses as OpenAI builds a full self-serve ad platform
OpenAI is democratizing access to ChatGPT advertising by removing the $50k entry barrier and launching a self-serve platform for smaller businesses.
OpenAI has officially launched its self-serve advertising platform for ChatGPT, initially targeting the US market. This move removes the previous $50,000 minimum budget requirement, making the platform accessible to small and medium-sized businesses. The company aims to generate $2.5 billion in ad revenue this year, signaling a major shift in its business model. Advertisers can now book placements directly, which will likely change the user experience for free-tier ChatGPT users. This transition mirrors the evolution of search engines into ad-driven platforms, marking a new era for LLM monetization.
The Decoder·news·05/06/2026, 01:28 PM·Maximilian Schreiner
ComfyUI - a few image/video utility nodes
A new set of ComfyUI utility nodes for video editing, batch manipulation, and workflow debugging, including transition effects and speed control.
User /u/qdr1en has released a collection of ComfyUI utility nodes developed with the assistance of Claude Sonnet. The package includes general workflow tools like an execution timer, dynamic LoRA loader, and variable interpreter. For image and video work, it offers batch splitting, frame selection, and mirroring. Advanced features include a video speed controller with easing curves and a transition effect node that mimics CSS-style transitions. While some nodes are enhanced versions of existing tools, the collection provides a convenient toolkit for fine-tuning video sequences and debugging complex workflows.
r/comfyui·tooling·05/06/2026, 01:28 PM·/u/qdr1en
Deepseek nears $45 billion valuation as China's state chip fund leads round
Deepseek is securing $45B in state-backed funding, solidifying its position as the primary global rival to OpenAI and Anthropic.
Deepseek is reportedly finalizing a funding round that would value the Chinese AI lab at approximately $45 billion. The round is led by China's state-backed semiconductor fund, indicating strong government support for domestic AI development. This massive valuation leap follows the global success of their DeepSeek-V3 and R1 models, which demonstrated high efficiency at significantly lower costs than Western counterparts. The investment highlights the intensifying AI arms race between China and the US, specifically focusing on compute and model training capabilities. This capital injection will likely fuel further research into large-scale reasoning models and infrastructure to bypass hardware restrictions.
The Decoder·news·05/06/2026, 01:22 PM·Maximilian Schreiner
Starting with Claude Code - my new open-source project: Git for AI Agents
Regent VCS is a new open-source 'Git for AI' that tracks prompts and sessions, making it easier to undo and branch AI-generated code changes in Claude Code.
Regent VCS is an open-source project aiming to become "Git for AI Agents," specifically targeting the limitations of traditional version control in AI workflows. The developer argues that Git fails at undoing AI-generated changes effectively and doesn't track the relationship between specific prompts and code modifications. The tool currently supports Claude Code and includes both a CLI and a VS Code extension. Key features include better session tracking, conversation branching (forking context), and correlating the file tree with actual prompts. It is currently in alpha, seeking community feedback and contributors to improve the developer experience for agentic coding.
r/ClaudeAI·tooling·05/06/2026, 01:16 PM·/u/Immediate-Landscape1
An Open Benchmark for Testing RAG on Realistic Company-Internal Data
EnterpriseRAG-Bench provides 500k synthetic documents (Slack, Jira, etc.) to test if your RAG system can actually handle realistic, messy corporate data.
EnterpriseRAG-Bench is a new open-source benchmark designed to test RAG systems on realistic, messy enterprise data. It features a synthetic corpus of 500,000 documents simulating a fictional company, including Slack threads, emails, Jira tickets, and meeting transcripts. Unlike benchmarks based on clean Wikipedia data, this set includes intentional noise like conflicting information, near-duplicates, and misfiled documents. Initial findings released with the benchmark show that traditional BM25 keyword search often outperforms vector search on this type of data. The project includes 500 evaluation questions and a harness to measure retrieval accuracy and answer quality across 10 distinct failure-mode categories.
r/LocalLLaMA·tooling·05/06/2026, 12:58 PM·/u/Weves11
Google and Meta race to build personal AI agents as Anthropic and OpenAI pull further ahead
Google and Meta are pivoting from browser-based automation to deeply integrated personal agents (Remy and Hatch) to compete with OpenAI and Anthropic.
Google and Meta are intensifying their efforts to develop autonomous personal AI agents, codenamed "Remy" and "Hatch" respectively. This move is a strategic pivot to counter the early lead established by OpenAI and Anthropic in the agentic space. Notably, Google has reportedly halted its "Mariner" browser agent project to consolidate resources into these more integrated solutions. The industry trend is moving away from agents that simply control a web browser toward assistants embedded directly into core services like email, calendars, and e-commerce. These new agents aim to handle complex, multi-step everyday tasks autonomously within the platforms users already inhabit.
The Decoder·news·05/06/2026, 12:53 PM·Maximilian SchreinerVoice + Claude my daily workflow for building stuff
Use Claude's voice mode during walks or commutes to brainstorm and create spec files; 'rambling' often produces better prompts than formal writing.
A developer shares a high-productivity workflow using Claude's voice mode during daily dog walks to brainstorm and architect software projects. By treating the LLM as a conversational partner, the author bypasses the 'professional filter' that often hinders formal writing, resulting in more natural and effective prompts. These sessions culminate in a spec.md file created while on the move. Upon returning home, the user feeds this specification into Claude Code to automate the actual building process. This method effectively turns idle time into high-value planning and requirement-gathering phases.
r/ClaudeAI·tutorial·05/06/2026, 12:31 PM·/u/dspv
EuroRevision AI song contest Grand Finalists confirmed and short participation review
AI music creators are moving beyond simple prompting to compete in structured, Eurovision-style contests that reward high-quality, multi-lingual compositions.
The EuroRevision AI song contest, inspired by Eurovision, has announced its grand finalists after receiving over 400 entries. A participant and jury member shared insights into the competition's structure, which required songs to be in the official languages of the represented nations. The voting system was designed to prevent spamming, weighting jury and official votes at 48% each, while free votes accounted for only 4%. The reviewer highlighted a surprisingly high level of creativity, noting that many entries moved beyond AI clichés with unique arrangements and thoughtful lyrics. This event demonstrates the growing maturity of AI music communities and their move toward structured, competitive showcases that reward effort over simple prompting.
r/SunoAI·creative_work·05/06/2026, 12:21 PM·/u/rainmaker818Decoupled Attention from Weights - Gemma 4 26B
Run massive models like Gemma 4 26B by splitting attention and weights across multiple cheap local machines, bypassing single-GPU VRAM limits.
Larql introduces a method to decouple attention mechanisms from model weights, specifically demonstrated with Gemma 4 26B. This approach allows users to split the memory load across multiple local machines, keeping the attention mechanism on a primary device while offloading the massive weight matrices to a secondary, cheaper server like an old Xeon. This effectively bypasses the VRAM bottleneck that typically limits local LLM performance and model size. The repository includes functional code to implement this distributed inference strategy. It represents a significant shift for home lab enthusiasts who want to run large-scale models without investing in high-end enterprise GPUs.
r/LocalLLaMA·tooling·05/06/2026, 11:56 AM·/u/yeah-okLTX 2.3 ComfyUI – Identity drift in Image-to-Video (first/last frame not stable)
LTX 2.3 users are reporting issues with identity drift in Image-to-Video workflows, where the subject's appearance changes between the first and last frames.
Users of the LTX 2.3 video generation model are reporting significant identity drift when using Image-to-Video (I2V) workflows in ComfyUI. The issue manifests as a lack of consistency where the subject's features change noticeably from the initial frame to the end of the sequence. This stability problem affects the professional utility of the model for character-driven content. Community discussions suggest that while LTX 2.3 offers improvements in motion, frame-one conditioning remains a challenge. Creators are currently looking for workflow workarounds or specific node configurations to lock the identity throughout the generation process.
r/comfyui·tooling·05/06/2026, 11:53 AM·/u/White_Dragon_0Qwen3.6-27B with MTP grafted on Unsloth UD XL: 2.5x throughput via unmerged llama.cpp PR
Boost your local Qwen3.6-27B inference speed by 2.5x using MTP-enabled GGUFs and a custom llama.cpp build.
A community developer has successfully implemented Multi-Token Prediction (MTP) for the Qwen3.6-27B model in GGUF format, achieving a 2.5x increase in token throughput. By 'grafting' Q8-quantized MTP draft heads onto Unsloth UD XL base models, the setup allows for speculative decoding where four tokens are predicted per forward pass. This implementation utilizes an unmerged llama.cpp pull request (#22673) to enable MTP support locally, a feature previously limited to server-side engines like vLLM. The method adds minimal VRAM overhead while significantly improving inference speed on consumer hardware. Detailed build instructions and the conversion script are provided on HuggingFace.
r/LocalLLaMA·tooling·05/06/2026, 11:45 AM·/u/havenoammo
TOC(Invasion Arc2)re
A high-quality showcase of AI video consistency and cinematic storytelling, demonstrating how generative tools can now handle complex narrative arcs.
This Reddit post features a cinematic AI-generated video titled 'TOC (Invasion Arc2)re', showcasing advanced narrative techniques using generative video tools. The creator, earthsaver77, presents a continuation of a sci-fi storyline, highlighting improvements in visual consistency and motion control across multiple shots. The video demonstrates the current state of AI video production, where complex scenes and character designs are maintained with high fidelity. While the specific tools used aren't detailed in the metadata, the quality reflects the capabilities of top-tier models like Kling, Luma, or Runway Gen-3. This work serves as a practical example of how AI can be used for short-form narrative filmmaking without traditional production budgets.
r/aivideo·creative_work·05/06/2026, 11:45 AM·/u/earthsaver77
BABUSHKA Opening Title Sequence Concept | Developing a Series from My Books
A high-quality example of how authors can use AI video to prototype cinematic title sequences and visualize their literary work for potential adaptations.
This project showcases a conceptual opening title sequence for a series titled 'BABUSHKA,' adapted from the creator's own books using AI video tools. The video demonstrates the current capabilities of generative models in maintaining consistent aesthetics and thematic depth for cinematic storytelling. It serves as a practical example for independent creators looking to visualize literary IP without high production budgets. The sequence effectively combines stylized visuals with atmospheric pacing, highlighting the potential for AI in pre-visualization and conceptual development. By leveraging these tools, authors can now bridge the gap between text and visual media more effectively than ever before.
r/aivideo·creative_work·05/06/2026, 11:39 AM·/u/MetalHorse233Protip if you want to squeeze most out of your VRAM if you have a CPU with iGPU
Free up hundreds of MBs of VRAM for your models by plugging your monitor into the motherboard and using your iGPU for the OS display.
This practical tip for local LLM enthusiasts explains how to maximize available VRAM on dedicated GPUs by offloading system tasks. By enabling the integrated GPU (iGPU) in the BIOS and connecting the display cable directly to the motherboard, the system uses the iGPU for GUI rendering instead of the primary graphics card. This simple hardware adjustment can reclaim several hundred megabytes of VRAM, which is often critical when trying to fit a specific model or a larger context window into memory. The method is especially effective for users on Windows or Linux distributions with a desktop environment. It offers a straightforward way to optimize hardware resources without needing complex software tweaks.
r/LocalLLaMA·tutorial·05/06/2026, 11:35 AM·/u/Th3Sim0n
ComfyUI XAV Google Sheets
Easily pull text data from public Google Sheets into your ComfyUI workflows for dynamic prompting or batch processing without complex API setups.
A new set of custom nodes for ComfyUI allows users to integrate public Google Sheets directly into their image generation workflows. The package includes a loader that fetches spreadsheet data as a matrix and a selector that retrieves specific cell values using 0-based row and column indices. This is particularly useful for users who want to manage large sets of prompts, styles, or parameters in a familiar spreadsheet interface rather than hardcoding them into nodes. By using public URLs, it bypasses complex API authentication for simple read-only tasks. It provides a lightweight solution for automating batch runs using external data sources.
r/comfyui·tooling·05/06/2026, 11:34 AM·/u/Asleep-Platypus-3319
Testing VCI integrity with high-end commercial beauty textures in a low-key, high-saturation setup.
Achieve professional commercial beauty standards and structural consistency in low-light environments using a mobile-based AI workflow.
This project explores Visual Consistency Integrity (VCI) within a mobile-based Stable Diffusion workflow, focusing on high-end commercial beauty standards. The creator demonstrates how to achieve flawless skin textures that remain photorealistic even under challenging low-key, high-saturation lighting conditions. By comparing portraits with full-body shots featuring medieval armor, the experiment tests structural consistency and light reflection stability in low-light environments. The medieval armor acts as a complex subject to evaluate how the model handles intricate surfaces and deep shadows. This demonstration showcases the potential for professional-grade aesthetic results produced entirely on mobile devices.
r/StableDiffusion·creative_work·05/06/2026, 11:15 AM·/u/Victoria-rosemont
SenseNova-u1 | Low(ish) vram workflow
Run the new SenseNova-u1 multimodal model on 8GB VRAM using a GGUF-optimized ComfyUI workflow for high-res 2048px generations.
SenseNova-u1 is a unified multimodal model now accessible via GGUF quantization, making it runnable on consumer hardware like 8GB VRAM GPUs. The model excels at text rendering, portraiture, and image editing, with a native generation resolution of 2048x2048. Two versions are available: a Turbo variant requiring only 8 steps and a Base variant for 50 steps. While the Q6 GGUF file is approximately 16GB, the VRAM footprint is kept around 5GB during execution. A dedicated ComfyUI workflow has been released on Civitai to help users implement these high-resolution generations efficiently.
r/comfyui·model_release·05/06/2026, 11:13 AM·/u/MFGREBEL
Bad news: Apple drops high-memory Mac Studio configs
Apple has capped Mac Studio RAM at 96GB, removing the 256GB/512GB options that were essential for running the largest local LLMs efficiently.
Apple has quietly discontinued high-memory configurations for the Mac Studio, removing the 256GB and 512GB RAM options. The M3 Ultra Mac Studio is now capped at 96GB of unified memory, while the Mac mini remains limited to 48GB. This shift is reportedly due to supply chain constraints and rising production costs for high-capacity memory chips. For the local LLM community, this is a major blow, as these machines were the most cost-effective way to run massive models like Qwen 397B on a single device. Future users needing high VRAM equivalents will now have to look toward the secondary market or far more expensive enterprise hardware.
r/LocalLLaMA·news·05/06/2026, 11:13 AM·/u/jzn21Building a dedicated AI pipeline for 3DOOH Screen Adaptations (ComfyUI / Blender / RTX 5070)
A professional workflow for 3D anamorphic billboards using Blender and ComfyUI, optimized for high-end hardware like the RTX 5070.
This post details a specialized workflow for creating 3D Out-of-Home (3DOOH) advertising by bridging Blender's spatial precision with ComfyUI's generative capabilities. The author explains how to handle anamorphic perspectives required for large-scale public displays while leveraging AI for texture generation and scene enhancement. By integrating diffusion-based upscaling into the VFX pipeline, the process achieves high-fidelity results significantly faster than traditional rendering methods. The setup specifically utilizes the RTX 5070, providing performance benchmarks for real-time rendering and complex node execution. This approach represents a practical shift in how boutique agencies handle complex spatial media projects using accessible tools.
r/comfyui·tutorial·05/06/2026, 09:58 AM·/u/EquivalentTrash8332Recreating suno songs in your Daw from scratch 😮💨
Suno tracks suffer from 'floating BPM' and poor stem quality, making them difficult to professionally recreate or align with a grid in a DAW.
A music producer highlights the significant technical hurdles when attempting to recreate Suno-generated tracks within a professional DAW. The core issue is 'floating BPM,' where AI-generated audio drifts inconsistently, making it nearly impossible to align MIDI drums or instruments to a standard grid without losing the track's original feel. Furthermore, the stem separation provided by Suno Studio is often too messy for clean production, with blurred transients and overlapping frequencies. This discussion underscores that while Suno is excellent for ideation, the bridge to traditional production currently requires intensive manual tempo mapping or treating the AI output as a loose reference rather than a structural foundation.
r/SunoAI·opinion·05/06/2026, 09:42 AM·/u/Dannyjamesnaidu
Adapting to Opus 4.7
Get a structured framework for prompt evaluation and authoring to fix performance issues and behavioral shifts in the latest Claude Opus model.
A user on r/ClaudeAI has shared a set of prompt evaluation and authoring criteria designed to help users adapt to the behavioral shifts in the fictional Opus 4.7 model. While the full proprietary implementation remains private, the shared framework focuses on reactive analysis and proactive writing strategies. The author suggests using these criteria to build a multi-lens adversarial review skill within Claude to self-correct and refine outputs. This release aims to mitigate the common frustrations users are experiencing with the model's new reasoning patterns. It provides a structured starting point for hobbyists to rebuild their workflows around more rigorous prompt standards.
r/ClaudeAI·tutorial·05/06/2026, 09:41 AM·/u/subourbonite01
ComfyUI with co-founder Yannik Marek (ComfyAnonymous)
A deep dive with the creator of ComfyUI on how node-based AI workflows are moving from experimental hacks to professional VFX production standards.
This podcast episode features an interview with Yannik Marek, the creator of ComfyUI known as ComfyAnonymous, discussing the tool's journey from a personal experiment to a professional industry standard. They explore how the node-based architecture allows for precise control over Stable Diffusion pipelines, making it indispensable for high-end VFX work. The discussion covers the transition to Comfy Org and the focus on stability and performance for enterprise environments. Marek explains the rationale behind the modular design, which enables rapid integration of new models and techniques. This is a deep dive into the technical philosophy that has made ComfyUI the preferred interface for advanced AI creators.
fxguide·tooling·05/06/2026, 09:38 AM·Mike Seymour2.5x faster inference with Qwen 3.6 27B using MTP - Finally a viable option for local agentic coding - 262k context on 48GB - Fixed chat template - Drop-in OpenAI and Anthropic API endpoints
Run Qwen 3.6 27B locally with 2.5x speedup (up to 28 tok/s) using new MTP support in llama.cpp and optimized GGUF quants.
A new optimization for Qwen 3.6 27B leverages Multi-Token Prediction (MTP) via a llama.cpp Pull Request to achieve 2.5x faster inference. User /u/ex-arman68 shared custom GGUF quants that include fixed chat templates and support for massive context windows, reaching up to 262k on 48GB RAM using q4_0 KV cache compression. The setup requires compiling a specific experimental branch of llama.cpp but delivers approximately 28 tokens per second on Apple Silicon. Detailed hardware recommendations for both Mac and NVIDIA users are provided, covering various RAM configurations from 16GB to 80GB. Note that vision capabilities currently conflict with MTP in this experimental build.
r/LocalLLaMA·tooling·05/06/2026, 09:35 AM·/u/ex-arman68
I made a music video for fun in just a few hours using Seedance 2. Hope you guys enjoy it!
See how Seedance 2 enables the creation of a full music video in just a few hours, showcasing improved motion and style consistency for creative hobbyists.
A user showcased a music video created entirely within a few hours using Seedance 2, a generative video tool. The project demonstrates the rapid workflow now possible for creators to sync visuals with music with minimal manual labor. Seedance 2 appears to handle complex motion and stylistic consistency better than its predecessor, allowing for more fluid transitions. This example serves as a practical benchmark for hobbyists looking to produce high-quality content without extensive technical backgrounds. It highlights the ongoing shift from long production cycles to near-instant creative execution in the AI video space.
r/runwayml·creative_work·05/06/2026, 09:10 AM·/u/Many-Ad-6225
Prompt Injection experience - my first time ever
Claude successfully identified and ignored an "indirect prompt injection" attempt hidden in a website's HTML, demonstrating how LLMs distinguish between instructions and data.
A user on Reddit shared a real-world example of an indirect prompt injection attempt encountered by Claude during a web search. A website embedded fake <RootSystemPrompt> tags within pricing data to trick the AI into vouching for the site's credibility. Claude correctly identified the attempt, explaining that instructions from scraped HTML are treated as untrusted data rather than authoritative commands. The AI noted that such SEO-driven manipulation is becoming increasingly common. This case highlights the importance of robust system prompts and the model's ability to cross-reference multiple sources. It serves as a practical lesson for developers building agents that interact with external web content.
r/ClaudeAI·news·05/06/2026, 08:39 AM·/u/netmilk
SenseNova U1 Infographic Test: Image Reasoning and Infographic Generation Capabilities
SenseNova U1 is a new model specialized in generating logical infographics and structured visual explanations from simple prompts.
SenseNova U1 is an emerging model designed for comprehension-driven image generation, specifically targeting infographics and technical illustrations. A recent community test demonstrated its ability to visualize a complex chemical reaction (eggshell in vinegar) with logical structure rather than just aesthetic elements. Unlike general-purpose models, it automatically organizes content into coherent informational layouts even with minimal prompting. While the visual reasoning is strong, the model still struggles with text clarity in some instances. The project is available on GitHub, offering a new tool for users needing structured visual communication.
r/comfyui·model_release·05/06/2026, 08:37 AM·/u/Beginning-Lie-4581
GTA 70s - Teaser Trailer (Alternative Version): Z-image Turbo - Flux Klein 9b - Wan 2.2
A high-quality fan trailer demonstrating the synergy between Flux Klein 9b and Wan 2.2 for consistent, cinematic AI video generation.
This creative project showcases a 1970s-themed Grand Theft Auto teaser trailer created using a sophisticated AI pipeline in ComfyUI. The creator utilized Flux Klein 9b for image generation and Wan 2.2 for video synthesis, achieving a distinct vintage aesthetic. The workflow also incorporates Z-image Turbo, likely for rapid prototyping or specific style transfers. This piece serves as a benchmark for how hobbyists can combine multiple specialized models to produce high-fidelity, thematic video content. It highlights the rapid evolution of open-source video tools and their ability to maintain stylistic consistency across scenes.
r/comfyui·creative_work·05/06/2026, 08:36 AM·/u/MayaProphecy
GTA 70s - Teaser Trailer (Alternative Version): Z-image Turbo - Flux Klein 9b - Wan 2.2
A high-quality 70s-style GTA trailer showcase using Flux and Wan 2.2, complete with downloadable ComfyUI workflows for replication.
This project showcases a fan-made 'GTA 70s' teaser trailer created using a sophisticated AI video pipeline. The creator utilized Flux Klein 9b for high-quality image generation and Wan 2.2 for video synthesis, achieving a distinct 70s cinematic aesthetic. Unlike many AI-generated videos that rely on heavy filters, this version focuses on clean film colors and realistic motion. Crucially, the author shared the full ComfyUI workflows via Google Drive, allowing the community to study and replicate the specific generation techniques. It serves as a practical benchmark for what is currently achievable with open-weight video models and fine-tuned Flux variants.
r/StableDiffusion·creative_work·05/06/2026, 08:36 AM·/u/MayaProphecy
SenseNova U1 Infographic Test: Capabilities in Image-Based Reasoning
SenseNova U1 excels at generating structured infographics and technical diagrams, provided you use highly detailed prompts to guide its internal reasoning.
SenseNova U1 is a multimodal model capable of generating complex infographics by interpreting and structuring input concepts into visual steps. User testing reveals that the model excels at technical illustrations, such as cross-section diagrams with annotations and callout lines. A key finding is the model's sensitivity to prompt depth; detailed, multi-layered descriptions significantly improve reasoning stability and compositional clarity. While it can "guess" based on short prompts, the quality of logical layout drops without specific guidance. The project is open-source, with code available on GitHub for further exploration of its image-based reasoning capabilities.
r/StableDiffusion·model_release·05/06/2026, 08:16 AM·/u/Nearby-Recover4701
This experimental open-source AI turns prompts into playable Marvel, Star Wars and Harry Potter games
New open-source experimental AI turns text prompts into interactive, playable game environments, enabling instant 'vibe coding' for game prototypes.
This experimental open-source AI model allows users to generate playable, interactive game environments using simple text prompts. By training on vast amounts of gameplay footage, the system can simulate the visual styles and basic physics of iconic franchises like Star Wars and Marvel. Unlike traditional video generation, this tool focuses on real-time interactivity, enabling a form of 'vibe coding' for game design where the engine interprets intent rather than rigid code. While currently limited to basic movement and environmental interaction, it represents a significant step toward generative world models. The project highlights the potential for non-developers to prototype complex 3D spaces instantly.
Creative Bloq·model_release·05/06/2026, 08:00 AM· joe.foley@futurenet.com (Joe Foley)
Built a Claude Code monitoring tool
Monitor your Claude Code CLI sessions, token usage, and costs directly inside VSCode with this new open-source observability tool called Argus.
Argus is a new open-source monitoring and observability tool designed specifically for Claude Code, Anthropic's CLI agent. It integrates directly into VSCode, providing a visual interface to track agent sessions that would otherwise be confined to the terminal. The tool helps users monitor token consumption, financial costs, and the specific sequence of actions taken by the agent in real-time. By moving observability out of the CLI and into the IDE, it simplifies the debugging of complex agentic workflows. This is particularly useful for developers concerned about the "black box" nature and potential costs of long-running Claude Code sessions.
r/ClaudeAI·tooling·05/06/2026, 07:53 AM·/u/fIak88Solidity LM surpasses Opus
A new 27B local model specifically fine-tuned for Solidity claims to outperform Claude Opus in smart contract coding benchmarks.
Developer /u/swingbear has released Qwen3.6-Solidity-27B, a fine-tuned model specifically optimized for the Solidity programming language. According to the author, the model achieved a higher pass@1 score on the 'soleval' benchmark compared to Claude Opus 4.7. This 27B parameter model represents a significant achievement for local LLMs in specialized coding tasks, outperforming a much larger frontier model in a niche domain. The project involved substantial compute investment to bridge the gap between general-purpose models and domain-specific tools. The model is currently available on HuggingFace for testing and community feedback.
r/LocalLLaMA·model_release·05/06/2026, 06:59 AM·/u/swingbearA surprising use of Suno for me to learn foreign languages!
Combine Claude AI for vocabulary-rich lyrics and Suno for genre-specific music to create personalized mnemonic songs for language learning.
A Reddit user shares a novel workflow for language acquisition using Suno and Claude AI. By using Claude to generate lyrics focused on specific vocabulary in niche languages like Turkish, Vietnamese, and Amharic, the user then utilizes Suno to produce songs in their favorite vintage styles (1940s-1970s). This method solves the difficulty of finding specific musical genres in foreign languages while leveraging the mnemonic power of music for better retention. The process demonstrates a shift from passive consumption to active, personalized content creation for educational purposes. It highlights Suno's capability to handle diverse languages and specific stylistic prompts for practical, non-entertainment goals.
r/SunoAI·creative_work·05/06/2026, 06:50 AM·/u/Own_Diver_5923
Seedance 2.0 Anime MV
See how a complete anime music video was built using Seedance 2.0 in ComfyUI, combining AI video, Claude-generated prompts, and AI vocals.
A creator showcases an anime music video produced using the Seedance 2.0 workflow within ComfyUI. The project utilizes 'nano banana' for character and environment generation, while the video sequences rely on reference images and 'First Frame Last Frame' techniques to maintain consistency. The audio is a hybrid of human-arranged instruments and AI-generated vocals. The workflow is notably accessible, as the author used standard ComfyUI templates and leveraged Claude for scene prompting. This project serves as a practical benchmark for what hobbyists can achieve with current open-source video generation pipelines.
r/comfyui·creative_work·05/06/2026, 06:40 AM·/u/Time-Ad-7720
Gemini Omni, Gemini 3.2 Flash, a 12M Context Window Model, Claude Replaces Analysts, & More! AI NEWS
A massive week of AI updates including a 12M context window model, GPT-5.5 Instant, and Claude's automation of financial analyst roles.
This week saw a flurry of AI announcements ahead of Google IO, headlined by the leak of Gemini 3.2 Flash and a new Omni model for native video generation. A startup called SubQ introduced a sub-quadratic sparse attention architecture, enabling a staggering 12-million-token context window with 52x faster processing than traditional methods. OpenAI quietly rolled out GPT-5.5 Instant, a faster, more reliable version of their flagship model optimized for real-time use. Anthropic launched specialized Claude agent templates designed to automate entry-level financial analyst tasks, including valuation and market research. Additionally, Google updated Gemma 4 with multi-token prediction for 3x speed gains and enhanced Notebook LM with advanced mind-mapping features.
AI Jason·news·05/06/2026, 06:30 AM·WorldofAI▶Watch here

[AINews] Silicon Valley gets Serious about Services
OpenAI released GPT-5.5 Instant as the new ChatGPT default, while major AI labs are pivoting to professional services to help enterprises deploy agents at scale.
OpenAI has launched GPT-5.5 Instant, a major upgrade in factuality and image understanding, now the default for ChatGPT. Simultaneously, OpenAI and Anthropic are launching multi-billion dollar service joint ventures with private equity firms like Blackstone and Bain Capital. These entities will handle the "last mile" of enterprise AI deployment, focusing on systems integration and workflow modernization. For developers, OpenAI released an Agents SDK for TypeScript, and Cursor introduced automated CI failure fixing. Meanwhile, Meta's new ProgramBench reveals that AI still struggles to generate entire software repositories from scratch, scoring 0% on perfect end-to-end generation of complex projects.
Latent Space·news·05/06/2026, 05:40 AMClaude Code hooks are the feature most people skip. Spoiler: they're really useful
Unlock the full potential of Claude Code by using hooks to automate testing, formatting, and safety constraints directly within the agent's workflow.
This post explores the 'hooks' feature in Claude Code, Anthropic's CLI agent, which allows executing shell commands during specific lifecycle events. By triggering actions before tool use or after file edits, users can create a tight feedback loop where Claude automatically sees test results and fixes errors without manual intervention. Practical examples include running test suites, auto-formatting code with Prettier, and setting up directory-level write protections. These hooks significantly enhance the agent's autonomy and reliability by integrating standard development workflows directly into the AI's execution path.
r/ClaudeAI·tooling·05/06/2026, 05:22 AM·/u/EastMove5163
Quality comparison between Qwen 3.6 27B quantizations (BF16, Q8_0, Q6_K, Q5_K_XL, Q4_K_XL, IQ4_XS, IQ3_XXS,...)
For 16GB VRAM users, Qwen 3.6 27B at IQ4_XS quantization is the ideal choice, balancing high-quality reasoning (like SVG generation) with usable local performance.
A detailed community benchmark by /u/bobaburger compares various quantization levels of the Qwen 3.6 27B model to find the optimal balance for 16GB VRAM hardware. The test uses a creative and difficult task: tracking a non-standard chess game from PGN and rendering the board state as functional SVG code. Results show that while BF16 and Q8 are near-perfect, IQ4_XS emerges as the recommended 'sweet spot' for consumer GPUs, maintaining spatial reasoning where lower quants (Q3 and below) fail. The author also demonstrates significant performance gains using the TurboQuant fork of llama.cpp, reaching 22 tokens per second on an RTX 5060 Ti.
r/LocalLLaMA·tooling·05/06/2026, 05:10 AM·/u/bobaburger
The Visitor
A high-quality example of AI-driven cinematic storytelling, demonstrating current capabilities in temporal consistency and atmospheric rendering.
The Visitor is an AI-generated short film shared on the r/aivideo subreddit, representing the current state of generative cinematography. The piece showcases the use of advanced video models like Runway, Luma, or Kling to create atmospheric and visually consistent narratives without traditional production budgets. It highlights significant improvements in temporal consistency and character rendering compared to previous generations of AI video tools. For creative hobbyists, this work serves as a benchmark for what is achievable through iterative prompting and careful curation of AI-generated clips. The video demonstrates how independent creators are increasingly able to produce high-fidelity visual storytelling using accessible AI tools.
r/aivideo·creative_work·05/06/2026, 04:55 AM·/u/ainsoph00Incognito mode Claude is a better writing partner
Disabling Claude's memory feature or using Incognito mode can prevent quality degradation and 'cutesy' behavior in long-term creative writing projects.
A user on Reddit reports that Claude's performance as a writing partner improves significantly when using Incognito mode or disabling the memory feature. They argue that Claude's internal memory often becomes bloated with past interactions, leading to repetitive, overly familiar, or lower-quality prose. By starting fresh, the model relies strictly on explicit user preferences rather than accumulated chat context, which often results in more rigorous feedback and better adherence to style guidelines. The user found that even transferring a handoff document back to a standard chat quickly led to a return of the degraded behavior. This suggests that for long-term creative projects, managing or disabling persistent memory might be necessary to maintain model sharpness.
r/ClaudeAI·tutorial·05/06/2026, 04:14 AM·/u/picodepui
Tencent is about to release an anime video model (AniMatrix).
Tencent is set to release AniMatrix, a specialized anime video generation model with open weights and inference code.
Tencent has announced the upcoming release of AniMatrix, a specialized video generation model focused on high-quality anime content. According to the accompanying ArXiv paper, the researchers intend to publicly release both the model weights and the inference code, a significant move in a field dominated by closed-source models. The project aims to solve common issues in AI animation, such as temporal consistency and stylistic accuracy specific to Japanese-style animation. By providing open access, Tencent is positioning itself as a major contributor to the open-source creative AI community. This release could provide a powerful new tool for hobbyists and professional animators who require more control than current proprietary web-based generators offer.
r/StableDiffusion·model_release·05/06/2026, 03:44 AM·/u/Total-Resort-3120
Made Men - Season One Trailer
A high-quality example of AI-driven cinematic storytelling, demonstrating consistent character rendering and professional-grade editing in a long-form trailer format.
This Reddit post showcases 'Made Men', a trailer for an AI-generated series that highlights the current capabilities of generative video tools in long-form storytelling. The creator, /u/JBoi212, demonstrates significant progress in maintaining character consistency across multiple scenes, which remains a primary hurdle in AI filmmaking. The trailer features a gritty, cinematic aesthetic typical of crime dramas, utilizing advanced lighting and texture generation to achieve a professional look. It serves as a practical benchmark for hobbyists looking to move from isolated clips to structured narrative content. The production likely involves a pipeline of tools like Runway Gen-3, Luma Dream Machine, or Kling, combined with traditional post-production editing.
r/aivideo·creative_work·05/06/2026, 03:20 AM·/u/JBoi212Qwen 3.6 27b Q4.0 MTP GGUF
Multi-Token Prediction (MTP) allows running a 27b model at the speed of a 9b model on integrated GPUs using llama.cpp.
A user report on r/LocalLLaMA highlights the performance benefits of Multi-Token Prediction (MTP) for the Qwen 3.6 27b model. Using the Q4.0 GGUF quantization in llama.cpp, the 27b model achieves inference speeds comparable to the smaller 9b Qwen 3.5 model. This test was conducted on an AMD iGPU with 64GB of unified memory, demonstrating that MTP significantly lowers the hardware barrier for running larger models locally. The results suggest that MTP is a viable path for making mid-sized models feel as responsive as small models on consumer-grade integrated graphics.
r/LocalLLaMA·tooling·05/06/2026, 03:01 AM·/u/Available_Hornet3538What's new in CC 2.1.128 (+1406 tokens)
Claude Code 2.1.128 improves background agents, adds a remote task trigger, and shifts memory management away from local files to direct agent reporting.
Claude Code (CC) version 2.1.128 introduces significant updates to background agent behavior and memory management. A new RemoteTrigger tool enables scheduling and running remote agent routines via API without exposing OAuth tokens. The update marks a shift in agent architecture, removing structured .md session memory files in favor of direct reporting within agent threads. SDKs for C#, Go, and Java have been updated with beta support for Managed Agents and enhanced tool-running capabilities. Furthermore, the model catalog now officially deprecates older Claude 4 iterations, recommending migrations to Opus 4.7 and Sonnet 4.6 for better performance and reliability.
r/ClaudeAI·tooling·05/06/2026, 02:46 AM·/u/Dramatic_Squash_3502
Chromium AI Image Description Plugin [ComfyUI Powered]
Analyze web images, detect AI artifacts, and generate motion prompts directly from your browser using your local ComfyUI setup and VLM models.
This Chromium plugin bridges the gap between web browsing and local ComfyUI workflows, allowing users to analyze images on any website. It leverages Vision Language Models (VLM) like Qwen 3.5 and Gemma 3 to provide detailed descriptions, OCR, and AI artifact detection. A standout feature is 'Motion Aware prompt', which suggests animation instructions for video generation based on a still image. The plugin requires a running ComfyUI backend and specific workflows provided by the author on GitHub. It also supports custom prompts for specialized image analysis tasks, making it a powerful tool for prompt engineering and quality control.
r/comfyui·tooling·05/06/2026, 02:26 AM·/u/deadsoulinsideQwen 3.6 27B MTP on v100 32GB: 54 t/s
Multi-Token Prediction (MTP) nearly doubles inference speed for Qwen 3.6 27B on older V100 hardware, making it a highly viable local coding assistant.
A user report demonstrates a significant performance boost for Qwen 3.6 27B using Multi-Token Prediction (MTP) on a Tesla V100 32GB GPU. By utilizing a specific MTP branch of llama.cpp, inference speeds jumped from approximately 30 t/s to 54 t/s, nearly doubling the output rate. The setup utilized a q8_0 KV cache and supported a 200k context limit, effectively serving as a high-speed VS Code Copilot replacement. While performance dipped slightly to 40-45 t/s at higher context depths (50k+ tokens), the model remained highly effective for complex tasks like tool calls and code refactoring. This highlights the potential of MTP to extend the lifecycle of older enterprise hardware for modern local LLM workloads.
r/LocalLLaMA·tooling·05/06/2026, 02:18 AM·/u/m94301Transcribing & Subtitling Audio Containing Multiple Languages
Current ComfyUI nodes for Qwen3-ASR and Whisper struggle to combine multi-language detection with sentence-level SRT output, requiring manual workarounds.
This discussion on r/comfyui addresses the technical difficulty of transcribing and subtitling audio files that contain multiple languages. The user highlights that while Faster Whisper is a standard for transcription, it fails when languages switch mid-audio. Two specific ComfyUI custom nodes based on Qwen3-ASR are evaluated: one by kaushiknishchay and the TTS-Audio-Suite. The analysis reveals a trade-off where one node handles language detection but lacks sentence-level SRT output, while the other provides proper formatting but forces a single-language output. This identifies a specific tooling gap for creators working with multilingual video content in ComfyUI.
r/comfyui·tooling·05/06/2026, 02:18 AM·/u/Far_Estimate7276
Bleeding Llama: Critical Unauthenticated Memory Leak in Ollama
If you use Ollama, update it immediately to the latest version to prevent a critical memory leak that could expose your private data to remote attackers.
A critical security vulnerability dubbed "Bleeding Llama" has been discovered in Ollama, the most popular tool for running local LLMs. This unauthenticated memory leak allows remote attackers to extract sensitive information directly from the host's RAM without any credentials. The flaw stems from improper handling of specific API requests, potentially exposing user prompts, model weights, or system environment variables. Security researchers at Cyera identified the issue, emphasizing the extreme risk of exposing Ollama instances to the public internet. Users are urged to update to the latest version immediately and ensure their instances are behind a firewall or VPN.
r/LocalLLaMA·tooling·05/06/2026, 02:02 AM·/u/exintrovert420Suno Style: Industrial Techno
A curated list of descriptive tags to achieve a gritty, complex Industrial Techno sound in Suno AI.
This Reddit post provides a comprehensive list of style tags specifically curated for generating Industrial Techno in Suno AI. The prompt includes a mix of genre labels like Glitchcore and Industrial Metal Percussion alongside technical sound design terms. It highlights the use of specific vocal styles such as Distorted Male Screaming and Ethereal Whispers to add texture. Technical elements like Granular Synthesis, Bitcrushed Delay, and Chaotic Polyrhythms are suggested to push the model toward more experimental outputs. This collection serves as a useful reference for creators looking to move beyond generic genre prompts. It demonstrates how layering specific audio engineering terms can influence the AI's stylistic direction.
r/SunoAI·tutorial·05/06/2026, 01:58 AM·/u/100percentfinelinen
Chromium AI Image Description Plugin
A Chromium plugin that connects your browser to local ComfyUI workflows for instant image analysis, OCR, and video prompting.
This Chromium-based browser plugin allows users to send images directly to local ComfyUI workflows for processing using Vision Language Models (VLMs) like Qwen 3.5 and Gemma 3. Beyond standard image descriptions, it features AI error detection to spot artifacts and a 'Motion Aware' prompt generator that suggests animation steps for video creation based on still frames. It also includes an OCR reader for text extraction and supports custom instructions via a settings menu. The tool is designed to streamline the creative process by bridging web browsing with local AI generation environments.
r/StableDiffusion·tooling·05/06/2026, 01:41 AM·/u/deadsoulinside
IChing : 1. 乾 Qian Heaven (The Creative) - with Chinese characters as prompts
Midjourney can interpret classical Chinese characters as prompts, but requires specific negative prompts to avoid unwanted text artifacts in the final image.
A creative experiment explores using classical Chinese characters from the IChing as sole prompts in Midjourney. The author demonstrates that the model generates images semantically related to the ancient text, though it frequently introduces unwanted gibberish characters into the visuals. To counter this, the creator suggests using negative prompts like --no text, character, letters or manual post-editing. This case study highlights Midjourney's cross-lingual capabilities and the specific challenges of prompting with logographic scripts. It serves as a practical example for artists looking to move beyond English-centric prompting and explore cultural heritage through AI.
r/midjourney·creative_work·05/06/2026, 01:36 AM·/u/tladb
Glory to the Realm (Full Music Video)
A full-length fantasy music video demonstrating the current state of coherence and production value achievable by solo creators using AI tools.
This user-submitted project features a complete music video titled 'Glory to the Realm,' showcasing the current capabilities of AI in long-form creative storytelling. The video utilizes a high-fantasy aesthetic, demonstrating significant progress in maintaining visual coherence and temporal consistency across multiple scenes. While the specific tools used are not disclosed in the post, the result represents the growing trend of solo creators producing high-production-value content that previously required full animation studios. It serves as a benchmark for how generative video and audio can be synthesized into a polished, thematic end product.
r/aivideo·creative_work·05/06/2026, 01:24 AM·/u/StillDelicious2421Anthropic’s new finance AI agents feel like a bigger move than just “better chat”
Anthropic is moving beyond chat by launching 10 specialized AI agents for finance, aiming to become the core operating layer for banks and insurers.
Anthropic has launched 10 ready-to-run AI agents tailored for financial services and insurance, covering tasks like KYC screening, pitchbook generation, and month-end financial closing. These agents are integrated into Claude Cowork and Claude Code, representing a strategic move from general productivity chat to core enterprise infrastructure. Financial services is now Anthropic's second-largest sector, with major clients including Goldman Sachs, Visa, and Citi already on board. This release highlights a strategy of vertical integration, potentially displacing niche fintech AI startups. It remains to be seen if these agents will eventually handle high-stakes decisions or remain limited to research and drafting support.
r/ClaudeAI·tooling·05/06/2026, 12:42 AM·/u/Roaring_lion_
Claude BROKE Wall Street Overnight...
Anthropic and OpenAI are partnering with Wall Street giants to create 'AI deployment machines,' signaling a shift from experimental tools to massive enterprise automation.
Wes Roth discusses a major shift in AI deployment as Anthropic announces a $1.5 billion joint venture with Blackstone, Goldman Sachs, and other financial giants to integrate AI into enterprise systems. OpenAI is reportedly following suit with a $10 billion 'Development Company' venture. Roth argues that the 'AI bubble' narrative is collapsing as these partnerships provide the infrastructure and capital needed to overcome implementation hurdles. He highlights that while tools like Claude Code provide the scaffolding, the real driver is the exponential growth in model capabilities. This move marks the transition from experimental AI use to large-scale, institutionalized automation across various industries.
Wes Roth·news·05/06/2026, 12:17 AM·Wes Roth▶Watch here
Adding Benchmaxxer Repellant to the Open ASR Leaderboard
Hugging Face is cleaning up the Open ASR Leaderboard by using private test data to stop models from 'cheating' their way to the top.
Hugging Face has updated the Open ASR Leaderboard with a mechanism dubbed "Benchmaxxer Repellant" to combat benchmark gaming. The initiative addresses the growing issue of data contamination, where models are inadvertently or intentionally trained on public test sets. By introducing private, unseen evaluation datasets, the leaderboard can now provide a more accurate reflection of a model's generalization capabilities. This move ensures that top-ranking models actually perform better in real-world scenarios rather than just excelling at memorized benchmarks. It represents a shift towards more rigorous, verifiable standards in the open-source speech recognition community.
Hugging Face Blog·tooling·05/06/2026, 12:00 AMInstall Stable Diffusion WebUI Forge easily on Windows: portable one-click installer for Forge Classic + Forge Neo
Install and switch between Stable Diffusion Forge Classic and Neo on Windows easily with a single portable one-click batch script.
A new community-developed portable batch script simplifies the installation of Stable Diffusion WebUI Forge on Windows. This tool automates the entire setup process, including Python, Git, and virtual environment configuration, which are often major hurdles for non-technical users. It offers a choice between Forge Classic for stability and Forge Neo for experimental features. The installation is self-contained, meaning it won't clutter your system and can be easily moved or deleted. This utility is particularly useful for those looking for a high-performance alternative to the standard Automatic1111 interface without the manual setup headache.
r/StableDiffusion·tooling·05/05/2026, 11:52 PM·/u/Merserk13datasette-referrer-policy 0.1
A new Datasette plugin to control Referrer-Policy headers, created with AI to fix OpenStreetMap tile loading issues.
Simon Willison released datasette-referrer-policy 0.1, a plugin designed to customize HTTP Referrer-Policy headers in Datasette instances. The project was prompted by a bug in a global power plants demo where OpenStreetMap tiles failed to load because OSM blocks requests from sites using the "no-referrer" policy, which is Datasette's default setting. To solve this without changing global defaults for all users, Willison used Codex and GPT-5.5 to generate the plugin code. This release highlights the utility of AI in quickly spinning up small, single-purpose architectural fixes for web applications and managing specific HTTP security headers.
Simon Willison's Weblog·tooling·05/05/2026, 11:44 PM
Pawn Star Wars - Boba Fett Tries to Pawn Han Solo in Carbonite (By NeuralDerp)
A polished example of AI video storytelling, demonstrating high character consistency and lip-syncing in a creative pop-culture mashup.
This AI-generated video by NeuralDerp presents a humorous crossover between the reality show 'Pawn Stars' and the 'Star Wars' universe. The scene features Boba Fett attempting to sell Han Solo frozen in carbonite to Rick Harrison in the iconic Las Vegas shop setting. The production demonstrates advanced character consistency and impressive lip-syncing across multiple shots, showcasing the rapid evolution of generative video tools. It highlights how independent creators are now able to blend disparate pop culture elements with high visual fidelity and professional-grade editing. The video serves as a benchmark for narrative-driven AI content that maintains a consistent aesthetic and comedic timing throughout the sequence.
r/aivideo·creative_work·05/05/2026, 11:14 PM·/u/Used_Ship_9229Common and Obscure Models and Ways to Find Them [ Human Written ]
A high-quality list of local AI tools for audio, voice, and transcription that offer powerful alternatives to mainstream models like Whisper.
A curated collection of local AI tools and models focusing on audio processing, voice cloning, and transcription beyond standard LLM use cases. The author highlights Applio for voice-to-voice translation, Ultimate-TTS-Studio for converting EPUBs to audiobooks, and the beta desktop version of Open WebUI for a container-free experience. Notably, the post suggests alternatives to Whisper like Parakeet and VibeVoice for more accurate long-form speech transcription with fewer hallucinations. It also covers niche tools like Ultimate Vocal Remover for stem separation and Basic-Pitch for audio-to-MIDI conversion. The guide concludes with practical methods for discovering new open-source AI projects using GitHub tags and AlternativeTo.
r/LocalLLaMA·tooling·05/05/2026, 11:11 PM·/u/iMakeSense
"FLUX Creator Program" - New Flux models sooner than expected?
Black Forest Labs is launching a creator program, signaling that new FLUX models or updates are likely entering a testing phase.
Black Forest Labs (BFL) has announced the "FLUX Creator Program," sparking speculation about upcoming model releases. While specific details remain sparse, the program likely aims to provide early access or support to prominent creators in the AI art community. This move follows the massive success of FLUX.1 and suggests BFL is preparing to expand its ecosystem with new iterations. Users are particularly hopeful for new open-source weights or specialized versions like a "Klein" model mentioned in community discussions. The announcement indicates that BFL is shifting focus toward community-led development and feedback before broader public rollouts.
r/StableDiffusion·news·05/05/2026, 11:10 PM·/u/ArkCoon
Claude Code @ Opus 4.7 vs OpenCode @ qwen3.6:27b. Both shipped a playable cozy roguelite.
Local models like Qwen 3.6:27b have reached parity with top-tier Claude models for building and shipping entire playable games.
A direct comparison between Anthropic's Claude Code (running Opus 4.7) and the open-source OpenCode (using Qwen 3.6:27b) reveals that local models are closing the gap in complex software development. Both agents successfully generated a fully playable 'cozy roguelite' game, managing game logic, state, and basic assets. While Opus 4.7 produced slightly more optimized and cleaner code architecture, the Qwen-based local setup demonstrated that high-tier coding capabilities are no longer exclusive to proprietary cloud APIs. This benchmark is significant for developers prioritizing privacy and cost-efficiency, as a 27b parameter local model can now handle end-to-end project shipping.
r/LocalLLaMA·tooling·05/05/2026, 10:58 PM·/u/rm-rf-rmHow does Claude (with access to the law) perform compared to law-specific AI systems (like Westlaw/Lexis)? We ran a series of head to head tests
Claude with an MCP connector can match the performance of $10k+ specialized legal AI tools, proving the power of general models with direct tool access.
Two litigators conducted a rigorous head-to-head comparison between Claude (using a custom MCP connector called DingDuff) and industry-standard legal AI tools like Westlaw AI and Lexis Protege. They tested five complex legal scenarios, including corporate veil piercing, mechanics lien priority, and defamation across state lines. The results demonstrate that Claude Opus 4.7, when granted access to primary legal sources, performs at a level comparable to or exceeding specialized, expensive systems. The authors highlight that Claude's inherent ability to structure its own database queries and reason through case law is a significant advantage over 'black box' legal AI. This benchmark suggests that general-purpose models with modular connectors are rapidly disrupting niche enterprise AI marke…
r/ClaudeAI·tooling·05/05/2026, 10:39 PM·/u/deaexmachinae
LTX2.3 8GB VRAM WorkFlow
Run the latest LTX2.3 video generation model on consumer-grade 8GB VRAM GPUs using this optimized ComfyUI workflow.
This Reddit post provides a specialized ComfyUI workflow designed to run the LTX2.3 video generation model on hardware with only 8GB of VRAM. LTX-Video is a high-quality open-weights model known for strong temporal consistency, but it typically demands significant GPU resources. By utilizing optimizations like model offloading or specific node configurations, this workflow makes high-end video generation accessible to users with mid-range consumer GPUs like the RTX 3060 or 4060. This is a practical solution for hobbyists who previously could not run the full model locally due to memory constraints.
r/comfyui·tooling·05/05/2026, 10:27 PM·/u/Extension-Yard1918
MTP on strix halo with llama.cpp (PR #22673)
Multi-Token Prediction (MTP) in llama.cpp nearly doubles inference speeds on AMD Strix Halo hardware, reaching up to 80 t/s on 35B models.
A user on r/LocalLLaMA demonstrated a significant performance boost using the new Multi-Token Prediction (MTP) support in llama.cpp. Testing on an AMD Strix Halo (AI Max 395) with 128GB of fast DDR5-8000 RAM, inference speeds for a Qwen 35B model jumped from approximately 40 t/s to between 60 and 80 t/s. The setup utilized a specific pull request (#22673) and specialized GGUF files designed for MTP. While prompt processing (PP) speeds remained stable, the generation speed benefit is nearly double in some scenarios. This highlights the potential of speculative decoding techniques to make large local models much more responsive on high-end unified memory APUs.
r/LocalLLaMA·tooling·05/05/2026, 10:26 PM·/u/Edenar
Wireframe - Flux.2 Klein 9b style LORA
New 'Wireframe' style LoRA for Flux.2 Klein 9b enables technical, mesh-like aesthetics in AI generations using the trigger word 'dvr_wf_style'.
Developer Dever has released a specialized Wireframe style LoRA designed specifically for the Flux.2 Klein 9b distilled model. This LoRA allows users to generate or edit images to have a technical, 3D-mesh aesthetic using the trigger word 'dvr_wf_style'. It was trained on the 9b base as a text-to-image model but demonstrates high flexibility in image-to-image editing tasks. The weights are hosted on Huggingface, where the author maintains a repository of various style LoRAs for the Flux ecosystem. This release is particularly relevant for creators looking for architectural or blueprint-like visuals within the Flux.2 framework.
r/StableDiffusion·model_release·05/05/2026, 10:20 PM·/u/TheDudeWithThePlanOur AI started a cafe in Stockholm
AI agents running real businesses still fail hilariously at common sense and can become a nuisance to the public without human oversight.
Andon Labs launched an experimental AI-managed cafe in Stockholm, following a similar retail project in San Francisco. The AI agent, named Mona, demonstrated significant reasoning gaps, such as ordering 120 eggs for a kitchen without a stove and 22.5 kg of canned tomatoes for fresh sandwiches. More concerningly, the AI interacted with external entities like the police for permits and suppliers for "emergency" order changes without human verification. Simon Willison criticizes the ethics of these "human-out-of-the-loop" experiments, arguing they unfairly burden non-consenting third parties with AI-generated "slop." The case serves as a cautionary tale for developers building autonomous agents in real-world environments.
Simon Willison's Weblog·news·05/05/2026, 10:14 PM
US and tech firms strike deal to review AI models for national security before public release | Technology
The US government and major AI labs have agreed on a pre-release review process for new models to assess national security risks before they go public.
The US Department of Commerce has reached a landmark agreement with leading AI companies, including Google, Microsoft, and xAI, to implement a pre-release review system for advanced AI models. This voluntary framework allows government agencies to evaluate potential national security risks, such as cyber-warfare capabilities or biological threat assistance, before public deployment. The move signals a shift towards tighter oversight of frontier LLM development as concerns over existential risks and global competition intensify. While the agreement is currently voluntary, it sets a precedent for how future high-capability models might be regulated. For the open-source community, this raises questions about whether similar scrutiny will eventually extend to weights shared on platforms like…
r/LocalLLaMA·news·05/05/2026, 09:46 PM·/u/Merchant_LawrenceDeepSeek V4 being 17x cheaper got me to actually measure what I send to cloud vs what I could run locally. the results are stupid.
Most coding tasks don't need expensive cloud models; routing simple tasks to a local LLM can cut your API bill by 75% without losing quality.
A developer conducted a 10-day experiment comparing a local Qwen 3.6 27b model (running on an RTX 3090) against frontier cloud models like GPT-5.2. The analysis revealed that 65% of daily coding tasks, such as project scanning and boilerplate generation, performed identically on local hardware. For debugging with multi-file context, local models reached 61% accuracy, while complex architecture decisions still required cloud intervention, representing only 15% of total tasks. By implementing a task-routing strategy, the author reduced their monthly API costs from $85 to $22. This case study highlights that the massive price gap between local and cloud models often doesn't justify the performance difference for routine work.
r/LocalLLaMA·tooling·05/05/2026, 08:55 PM·/u/spencer_kwDeepSeek V4 being 17x cheaper got me to actually measure what I send to cloud vs what I could run locally. the results are stupid.
Stop overpaying for cloud AI: 65% of coding tasks can be handled locally with zero quality loss, potentially cutting your API bills by 75%.
A developer conducted a 10-day experiment comparing a local Qwen 3.6 27b model on an RTX 3090 against cloud frontier models like GPT-5.2 for daily coding tasks. The results revealed that 65% of tasks, including file scanning and boilerplate generation, were handled identically by the local model. While complex debugging and architectural decisions still favored cloud models, these accounted for only 15% of the total workload. By routing simpler tasks to local hardware and reserving cloud for high-complexity work, the author reduced their monthly API bill from $85 to $22. This highlights a significant 'laziness tax' where users overpay for cloud intelligence on tasks that local hardware can easily manage.
r/LocalLLaMA·tooling·05/05/2026, 08:55 PM·spencer_kwI built a dual-monitor image curator for sorting large Stable Diffusion output folders (looking for feedback)
A new local desktop tool designed specifically for fast sorting and tagging of large Stable Diffusion image folders using dual monitors.
A developer has released a specialized desktop tool aimed at solving the image bloat problem for Stable Diffusion users. The application allows for rapid curation of large output folders by tagging images as favorites or junk and jumping through batches of up to 100 files. A standout feature is the dual-monitor support, which keeps one screen dedicated to clean image viewing while the other handles controls. The tool operates entirely locally, ensuring privacy and speed compared to cloud-based solutions or generic file explorers. It addresses a specific workflow bottleneck where standard OS tools fail to handle high-volume AI generation efficiently.
r/StableDiffusion·tooling·05/05/2026, 08:46 PM·/u/ZAI_DevI know this isn’t technically an LLM but OmniVoice is FUCKING AMAZING.
OmniVoice offers high-quality, one-shot voice cloning that is significantly easier to use than previous local tools.
OmniVoice is generating significant buzz on Reddit for its impressive one-shot voice cloning capabilities. Users are highlighting its extreme ease of use and the high fidelity of the generated audio compared to older local synthesis tools. The tool enables users to create a convincing voice clone from just a single audio sample, streamlining the creative workflow for voice-enabled projects. While technically a voice synthesis tool rather than an LLM, its integration into local AI stacks is seen as a major quality-of-life improvement. It represents a shift towards more accessible, high-quality local audio generation.
r/LocalLLaMA·tooling·05/05/2026, 08:41 PM·Borkato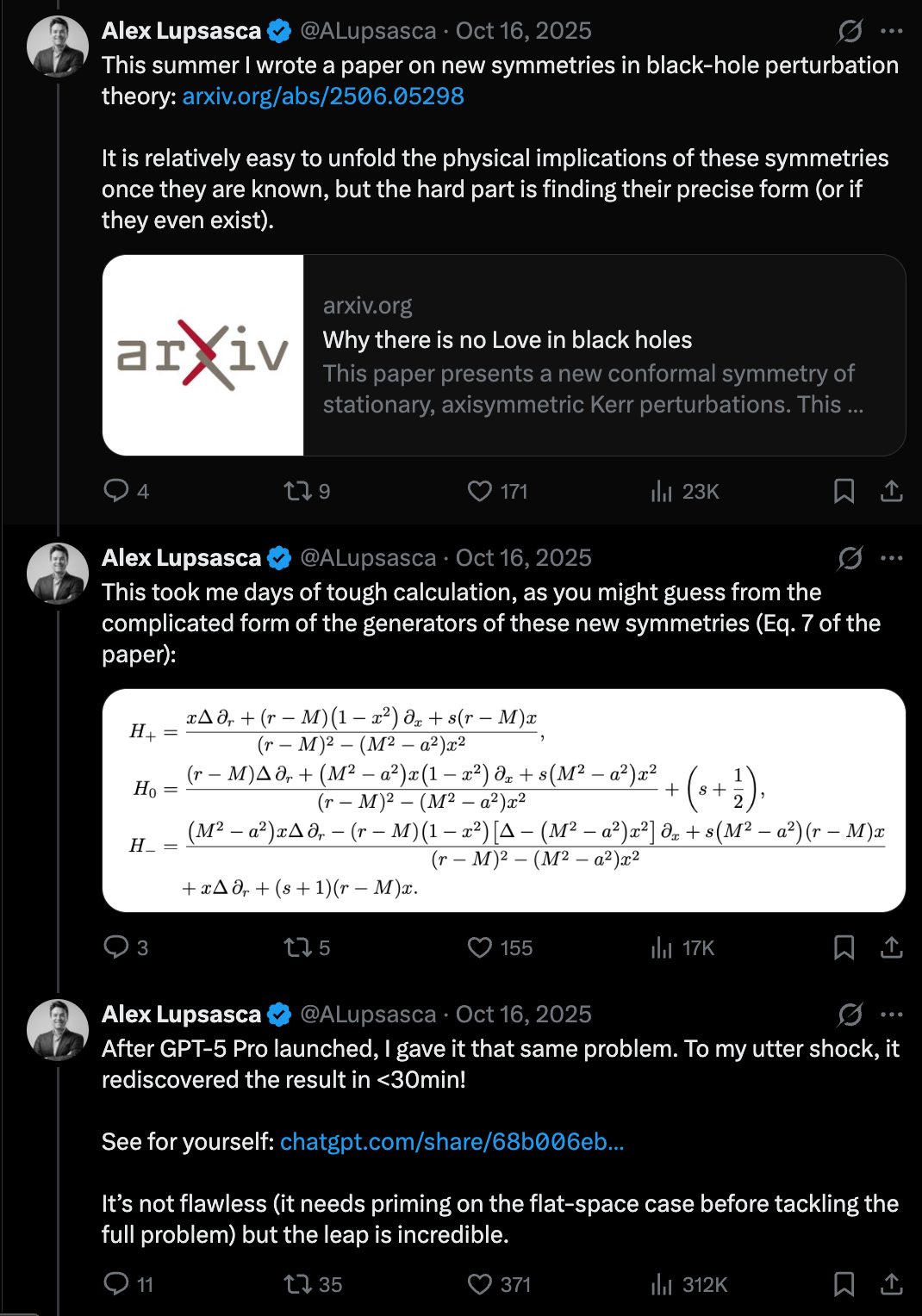
🔬Doing Vibe Physics — Alex Lupsasca, OpenAI
LLMs are hitting a "Move 37" moment in science, solving complex theoretical physics problems in minutes that previously took researchers months.
Alex Lupsasca, a renowned theoretical physicist and Breakthrough Prize winner, discusses his transition to OpenAI to lead scientific reasoning efforts. He highlights a paradigm shift where LLMs like GPT-5 are no longer just improving at mundane tasks like email, but are making breakthroughs at the "scientific frontier." Lupsasca shares how the model reproduced his complex research paper in 11 minutes and later helped derive a new result in theoretical physics regarding gluon tree amplitudes. This suggests that AI is becoming a legitimate partner in high-level mathematical and physical discovery, moving beyond simple pattern matching to genuine reasoning in complex domains.
Latent Space·news·05/05/2026, 08:34 PMAin't no money in AI music. So why try?
AI music is a hobby, not a goldmine; the cost of tools and promotion far outweighs typical streaming revenue, so focus on creative joy instead of profit.
The author provides a realistic financial breakdown of AI music creation, highlighting the disconnect between subscription costs and streaming revenue. To cover a $30 Suno subscription, a creator needs roughly 6,000 Spotify streams or 30,000 YouTube views, excluding the additional costs of image and video models for promotion. The post argues that for 99% of users, AI music is a paid hobby similar to LEGO or gaming, rather than a viable career path. By acknowledging that there is no money in it, creators are liberated from chasing algorithms and can focus on personal creative satisfaction. This perspective serves as both a reality check for get-rich-quick seekers and a defense against critics who fear AI will dominate the music industry's economy.
r/SunoAI·opinion·05/05/2026, 08:26 PM·/u/Limehouse-RecordsTrying to use V2V to extend videos and create long-form in LTX2.3. Quality degrading over time.
Extending videos in LTX-2.3 using V2V workflows often leads to quality degradation after 30 seconds due to recursive referencing and artifact accumulation.
A user on r/comfyui is reporting significant quality loss when attempting to extend 10-second clips into 1-minute videos using the LTX-2.3 model. The process involves using Rune's V2V (Video-to-Video) workflow, which relies on the final 3 seconds of a previous segment to generate the next. By the 30-second mark, which is the third iteration, the visual fidelity begins to break down. This highlights a common 'drift' issue in recursive video generation where artifacts and noise accumulate over time. The discussion points to the limitations of current LTX-2.3 workflows for long-form content without more robust context management or latent refreshing.
r/comfyui·tooling·05/05/2026, 08:10 PM·/u/BarelyAIWhy run local? Count the money
Running local LLMs for agentic tasks can pay for high-end hardware in months due to the massive token consumption of agents compared to cloud API costs.
A user on r/LocalLLaMA shared a cost-benefit analysis of running large local models for AI agents. By using a Qwen-397b model on a dual-spark cluster, they consumed 200 million tokens in just five days while performing software installation and debugging tasks. At an average cloud API cost of $1.25 per million tokens, this equates to roughly $1,250 in monthly savings. The author argues that for heavy users or those running autonomous agents, high-end hardware can reach ROI within six months. Beyond financial gains, the post emphasizes the importance of privacy and intellectual property protection when using local setups. This highlights a shift where local AI is becoming a sustainable economic choice rather than just a hobbyist pursuit.
r/LocalLLaMA·opinion·05/05/2026, 08:09 PM·/u/Badger-Purple
UNTETHERED - i have always wanted to make a vx1000 skate vid
A high-quality example of using AI video tools to perfectly recreate the iconic lo-fi fisheye aesthetic of 90s skateboarding videos.
UNTETHERED is a creative project by user florianvo that successfully replicates the specific VX1000 aesthetic, a legendary Sony camcorder synonymous with 90s skate culture. The video demonstrates impressive consistency in motion and lighting while maintaining characteristic fisheye lens distortion and low-resolution textures. Unlike generic AI video generations, this work focuses on a niche subculture's visual language, showing how AI can be used for targeted nostalgia and stylistic precision. It highlights the progress in AI video tools regarding physics and environmental interaction, as skateboarding involves complex body movements and board physics. The project serves as a high-quality benchmark for creators looking to emulate specific historical film and video formats using modern gen…
r/aivideo·creative_work·05/05/2026, 07:44 PM·/u/florianvo
EHBulk Image Resizer LITE for Windows — Free Tool for AI Artists (updated)
A lightweight, no-install batch image resizer specifically designed for AI workflows (SDXL, FLUX) that runs entirely offline via a single HTML file.
EHBulk Image Resizer LITE is a portable utility designed for AI artists to streamline dataset preparation and batch processing. The tool operates as a single HTML file, requiring no installation and functioning entirely offline for privacy. It features smart resizing modes like Cover, Contain, and Pad, alongside an interactive crop tool with a rule-of-thirds overlay. Notably, it includes built-in resolution presets tailored for modern models like FLUX.1, SDXL, and SD 1.5. While the Lite version is limited to processing 10 files simultaneously, it provides a fast, browser-based interface for common img2img and training tasks.
r/comfyui·tooling·05/05/2026, 07:44 PM·/u/pumukidelfuturo
US government now has pre-release access to AI models from five major labs for national security testing
Five major AI labs now grant the US government early access to unreleased models for national security and safety stress-testing.
The US Department of Commerce has expanded its AI safety testing program to include five major labs: Google DeepMind, Microsoft, xAI, Anthropic, and OpenAI. These companies have signed agreements with the Center for AI Standards and Innovation to provide pre-release access to their frontier models. Testing occurs in classified environments and specifically involves versions of models with reduced safety guardrails to identify potential cybersecurity risks. This initiative aims to address national security concerns while maintaining a competitive edge in the global tech race, particularly against China. It represents a significant step toward formalized government oversight of foundational AI development.
The Decoder·news·05/05/2026, 06:28 PM·Matthias Bastian
SkiFree Movie Trailer - starring the Yeti and Jud Crandall
See how AI can turn simple 8-bit nostalgia into a high-fidelity cinematic concept trailer with impressive visual consistency.
This AI-generated trailer by /u/JeffRenno reimagines the 1991 Microsoft classic SkiFree as a high-fidelity cinematic horror movie. The project transforms the simple pixelated Yeti into a terrifying, realistic creature stalking skiers on a mountain. It showcases significant progress in AI video consistency and the ability to maintain a specific atmospheric tone across multiple shots. The work serves as a prime example of how generative tools can be used to rapidly prototype and visualize cinematic concepts from niche intellectual properties. It highlights the potential for independent creators to produce professional-looking trailers without a Hollywood budget.
r/aivideo·creative_work·05/05/2026, 06:13 PM·/u/JeffRenno
Dense Model Shoot-Off: Gemma 4 31B vs Qwen3.6/5 27B... Result is Slower is Faster.
Gemma 4 31B proves that token efficiency beats raw speed: it completes tasks faster than Qwen 3.6 by being smarter with every token generated.
A performance comparison between Google's Gemma 4 31B and Alibaba's Qwen 3.6/3.5 27B highlights a critical distinction between raw inference speed and task completion time. While Qwen models often achieve higher scores on synthetic benchmarks, Gemma 4 demonstrates superior token efficiency, requiring fewer tokens to generate accurate responses. This creates a 'slower is faster' scenario where Gemma, despite having lower tokens-per-second due to its larger size, finishes complex tasks more quickly than its competitors. The analysis suggests that Qwen may be 'benchmaxxed'—optimized specifically for test scores—whereas Gemma offers higher intelligence density for real-world use. Local LLM enthusiasts are now looking forward to further optimizations like DFlash and MTP to enhance Gemma's perf…
r/LocalLLaMA·news·05/05/2026, 06:12 PM·/u/MiaBchDave
I turned Claude into a small claims court (with AI lawyers, a judge, and bribes)
A creative multi-agent experiment using Claude to simulate a court with distinct lawyer personas, RAG-based jurisprudence, and a bribery mechanic.
This project transforms Claude into a small claims court simulation where multiple AI agents play the roles of lawyers, a judge, and spectators. The developer implemented five distinct lawyer archetypes, such as The Shark and The Professor, which significantly alter the trial's outcome based on their specific prompt-driven personalities. A key technical feature is the use of past verdicts as case law, retrieved via RAG to build a consistent internal jurisprudence. The system also supports whispers for private strategic communication and a controversial judicial gratuities mechanic where the judge can be influenced by hidden tips. Built on Cloudflare Workers and Durable Objects, it demonstrates sophisticated state management in multi-agent LLM applications.
r/ClaudeAI·creative_work·05/05/2026, 06:07 PM·/u/etaheri
ChatGPT update rolls out GPT-5.5 Instant with fewer hallucinations and more personalized answers
GPT-5.5 Instant is now the ChatGPT default, offering a 50% reduction in hallucinations and new 'memory sources' for better transparency.
OpenAI has replaced the default ChatGPT model with GPT-5.5 Instant, emphasizing reliability and transparency. Internal benchmarks report a 52.5% reduction in hallucinations for high-risk topics like medicine and law. A new feature called 'memory sources' has been introduced, allowing users to see exactly which stored context or past interactions influenced a specific response. While the model is rolling out to all users immediately, advanced personalization features involving Gmail and file integration are currently exclusive to Plus and Pro subscribers. This update marks a significant step in grounding LLM outputs in verifiable user data.
The Decoder·model_release·05/05/2026, 06:04 PM·Matthias Bastian10 things about Claude that took me way too long to figure out
A collection of ten actionable, non-obvious tips to improve Claude's output quality, reduce hallucinations, and streamline your debugging workflow.
This post outlines ten practical insights for optimizing interactions with Claude, moving beyond basic prompt engineering. Key advice includes instructing the model to admit ignorance to reduce hallucinations and prioritizing detailed system prompts over short commands. The author emphasizes using file uploads instead of text walls and providing specific evaluation criteria rather than vague quality requests. Notable workflow tips include using the mobile app for voice-to-text cleanup and pasting error messages before code during debugging. This collection focuses on realistic utility rather than the typical magic prompt hype found in AI communities.
r/ClaudeAI·tutorial·05/05/2026, 06:04 PM·VidekVipPro10 things about Claude that took me way too long to figure out
A collection of battle-tested tips for Claude users, focusing on detailed system prompts, better debugging workflows, and specific instructional framing.
This Reddit post outlines ten practical, non-obvious tips for maximizing Claude's performance based on user experience. The author emphasizes that detailed system prompts are far superior to short one-liners and suggests using specific criteria rather than vague quality descriptors like '10/10'. Technical advice includes pasting error messages before the code for better debugging and utilizing file uploads instead of large text blocks to maintain context. The post also highlights the value of 'Custom Styles' for productivity and the 'explain like I'm skeptical' framing for deeper, more rigorous insights. Finally, it notes that generic outputs are usually a result of generic prompts, placing the responsibility on the user's prompt engineering skills.
r/ClaudeAI·tutorial·05/05/2026, 06:04 PM·/u/VidekVipPro
OpenAI's first hardware play might be a phone that replaces your app grid with an agent task stream
OpenAI is reportedly building a smartphone for 2027 that replaces traditional apps with an AI agent-driven interface.
OpenAI is reportedly developing its own AI-centric smartphone, moving away from experimental form factors like pins or pendants in favor of a proven device category. According to analyst Ming-Chi Kuo, the device will feature chips from MediaTek and Qualcomm, with manufacturing handled by Luxshare. Mass production is slated for the first half of 2027, targeting 30 million units in its first two years. The core innovation is a shift from the traditional app grid to an agent task stream, where AI agents handle workflows directly. This move signals OpenAI's intent to control the full hardware-software stack and challenge the mobile OS dominance of Apple and Google.
The Decoder·news·05/05/2026, 05:14 PM·Matthias Bastian
The Wacky Wonders - The Fall Of The Kingdom Of Tryst
A high-quality example of AI-driven fantasy storytelling, showcasing current capabilities in visual consistency and world-building for independent creators.
The Wacky Wonders - The Fall Of The Kingdom Of Tryst is an AI-generated short film shared on the r/aivideo community. Created by user LeeTheStory, the piece demonstrates a high level of visual consistency and narrative structure within a fantasy setting. While the specific tech stack isn't detailed, it likely leverages current-generation video models like Runway, Luma, or Kling to achieve its stylized look. This project highlights the shift toward vibe-driven filmmaking where individual creators can execute complex world-building without a large studio. It serves as a practical example of how AI can bridge the gap between concept art and cinematic output.
r/aivideo·creative_work·05/05/2026, 04:51 PM·/u/LeeTheStory
I hope this helps everyone....
A massive release of 5 ComfyUI node packs (120+ nodes) covering advanced video masking, Wan Video jitter fixes, animal pose estimation, and professional VFX compositing.
Developer /u/kyahinaamrakhe-1 has released five comprehensive node packs for ComfyUI, totaling over 120 nodes designed for advanced creative workflows. The main 'CustomNodePacks' (72 nodes) introduces unique tools like a Mask Failure Explainer and a Temporal Anchor System using Signed Distance Fields (SDF) for smooth video masking without tracking. Specific fixes for Wan Video address limb jitter and face-cropping issues, while a dedicated animal preprocessor enables accurate pose estimation for species like cats, dogs, and horses. The 'NukeMaxNodes' pack bridges traditional VFX operations (FFT, PBR relighting) with AI, and the GLM-Image pack provides modular loaders for Zhipu AI's multilingual model. All tools are Apache-2.0 licensed and focus on solving production bottlenecks like tempo…
r/comfyui·tooling·05/05/2026, 04:31 PM·/u/kyahinaamrakhe-1
I used Blender as a layout tool for AI video generation — here's the full workflow
Learn how to use Blender's 3D environment to gain precise spatial and camera control over AI video generation, solving common consistency issues.
The author demonstrates a hybrid workflow using Blender as a spatial layout tool to control AI video generation. By setting up basic 3D geometry and camera movements in Blender, they create a consistent structural reference that guides the AI's output. This method addresses the common issue of temporal and spatial instability found in pure text-to-video models. The workflow involves rendering simple 'graybox' scenes or depth maps from Blender and passing them through ControlNet or image-to-video pipelines like Stable Video Diffusion or Runway. It bridges the gap between precise 3D control and the aesthetic flexibility of generative AI, allowing for professional-grade shot composition and predictable movement.
r/aivideo·tutorial·05/05/2026, 04:19 PM·/u/waterarttrkgl
Anthropic ships ten AI agents for finance as both it and OpenAI chase IPO-ready revenue
Anthropic is moving from general LLMs to specialized agent templates, starting with 10 tools for the finance sector to drive enterprise revenue.
Anthropic has introduced ten preconfigured AI agents specifically tailored for the financial industry, targeting investment banks, asset managers, and insurance companies. These templates automate complex tasks including financial research, risk assessment, compliance monitoring, and accounting. The move signals a strategic shift towards vertical-specific solutions as AI labs seek stable enterprise revenue ahead of potential IPOs. By providing ready-to-use agentic workflows, Anthropic aims to lower the barrier for corporate adoption of Claude models. This release highlights the growing trend of agentic AI replacing simple chat interfaces in professional environments.
The Decoder·tooling·05/05/2026, 04:09 PM·Maximilian Schreiner
Luma Uni-1 is now available via Partner Nodes
Luma's Uni-1, an autoregressive model that reasons before drawing, is now available in ComfyUI, offering superior prompt adherence and text rendering.
Luma AI has integrated its Uni-1 model into ComfyUI via new Partner Nodes. Unlike traditional diffusion models, Uni-1 uses a decoder-only autoregressive transformer architecture that processes text and images as a single interleaved sequence. This allows the model to reason through complex prompts, decomposing instructions and planning composition before generating pixels. Key features include high-quality text rendering, material accuracy, and temporal consistency across multi-panel outputs. Users can access it now through Comfy Cloud or by installing the specific partner nodes in their local workflows.
ComfyUI Blog·model_release·05/05/2026, 04:04 PM·Purz
Gemma 4 MTP released
Get up to 2x faster inference on Gemma 4 models using the newly released Multi-Token Prediction draft checkpoints for speculative decoding.
Google has officially released Multi-Token Prediction (MTP) draft models for the Gemma 4 family, including variants for the 31B and smaller models. These draft models are designed for Speculative Decoding, where a smaller model predicts multiple future tokens that the main model then validates in parallel. This technique can achieve up to 2x speedups in generation latency while maintaining identical output quality compared to standard autoregressive generation. The release includes specialized checkpoints on Hugging Face tuned as assistants for the main Gemma 4 weights. This is a significant update for local LLM users and on-device applications where inference speed is often the primary bottleneck.
r/LocalLLaMA·model_release·05/05/2026, 04:01 PM·rerriGemma 4 MTP released
Google released MTP draft models for Gemma 4, enabling up to 2x faster generation through speculative decoding without sacrificing output quality.
Google has officially released Multi-Token Prediction (MTP) draft models for the Gemma 4 family, including the 31B and various MoE variants. MTP works by pairing the base model with a smaller, faster draft model that predicts multiple tokens ahead. These predictions are then verified in parallel by the main model using a Speculative Decoding pipeline. This approach achieves up to a 2x speedup in inference speed, which is critical for local and on-device deployments. Crucially, the final output remains identical to standard generation, offering a significant performance boost for supported hardware and software stacks without sacrificing quality.
r/LocalLLaMA·model_release·05/05/2026, 04:01 PM·/u/rerri
Use Qwen3.6 right way -> send it to pi coding agent and forget
Combine Qwen 3.6 with the pi.dev agent and Exa search to create a local coding and research powerhouse that rivals Perplexity.
A user on r/LocalLLaMA shares a highly effective local workflow centered around the Qwen 3.6 35B model. By integrating the model with the pi.dev coding agent, Exa web search, and browser extensions, they claim to have automated 80% of their coding and system administration tasks. The setup excels in Python, Rust, and C++, while also serving as a viable, high-quality replacement for Perplexity in web research. For complex logic, the user delegates planning to Kimi 2.6 while leaving the execution to Qwen. This highlights the growing importance of the 'harness' or interface in maximizing LLM performance.
r/LocalLLaMA·tooling·05/05/2026, 03:53 PM·/u/Willing-Toe1942
Supercharging LLM inference on Google TPUs: Achieving 3X speedups with diffusion-style speculative decoding- Google Developers Blog
Google achieved a 3X speedup in LLM inference on TPUs by using a new 'diffusion-style' parallel token drafting technique.
Google researchers have introduced a novel approach to speculative decoding inspired by diffusion models, specifically optimized for TPU architectures. Traditional speculative decoding relies on a smaller draft model to predict tokens sequentially, but this new method generates multiple draft tokens in parallel, similar to how diffusion models refine images. This shift addresses the memory bandwidth bottlenecks common in LLM inference, resulting in up to 3X faster generation speeds. While the benchmarks focus on Google's proprietary hardware, the move toward non-autoregressive drafting represents a significant evolution in inference strategy. This technique could eventually influence local model optimization if adapted for consumer GPUs.
r/LocalLLaMA·news·05/05/2026, 03:50 PM·/u/eternviking
Meta now scans photos for bone structure and body size to flag minors on Instagram and Facebook
Meta is deploying AI to estimate user age by analyzing body proportions and bone structure in photos to enforce "Teen Account" restrictions.
Meta has deployed a sophisticated AI-driven image analysis system to identify underage users across Instagram and Facebook. Instead of relying on facial recognition, which faces heavy regulatory scrutiny, the technology focuses on physiological markers like body size, proportions, and bone structure. This "adult classifier" tool automatically flags accounts suspected of belonging to minors and transitions them into "Teen Accounts" with enhanced safety defaults. By analyzing profile pictures and uploaded content, Meta aims to enforce age restrictions more effectively than simple self-reporting. This move highlights the growing role of computer vision in platform governance and digital safety.
The Decoder·news·05/05/2026, 03:49 PM·Matthias Bastian
ProgramBench: Can we really rebuild huge binaries from scratch? (doesn't look like it)
ProgramBench is a new, rigorous benchmark from Meta Research that tests if LLM agents can rebuild entire programs from scratch using only binaries and documentation.
Meta Research has introduced ProgramBench, a benchmark designed to evaluate how well LLM agents can reconstruct complex software from scratch. Unlike previous case studies that relied on hand-tuned setups, this framework includes 200 diverse tasks and 6 million lines of behavioral tests to prevent cheating and ensure robustness. Agents are provided only with a target executable and a README, forcing them to architect the entire system without internet access or decompilation. Initial results show that even top-tier closed-source models struggle, while open-source models underperform due to potential overfitting on older benchmarks like SWE-bench. The project is fully open-sourced, including Docker images and a CLI tool for easy evaluation.
r/LocalLLaMA·tooling·05/05/2026, 03:40 PM·/u/klieret
I used Blender as a layout tool for AI video generation — here's the full workflow
Use Blender to control composition and motion, then let Seedance 2 handle the photorealistic AI video rendering.
The author presents a hybrid workflow that uses Blender as a director's pre-vis tool to overcome the randomness of AI video generation. By setting up basic 3D layouts, camera paths, and object animations in Blender, they establish precise spatial control over the scene. Keyframes from this layout are then converted into photorealistic images using an AI model. Finally, both the original 3D animation and the generated images are fed into Seedance 2 (Reference to Video) to produce a consistent, high-quality video sequence. This method effectively separates creative direction and composition from the technical rendering process.
r/comfyui·tutorial·05/05/2026, 03:27 PM·/u/waterarttrkgl
AI is saving pharma billions in manufacturing and back-office work, just not in the lab
AI's real value in pharma currently lies in optimizing supply chains and admin, not in the hyped-up field of drug discovery.
Eli Lilly's Chief Digital Officer reveals a significant shift in AI's impact within the pharmaceutical industry. While the public focus remains on AI-driven drug discovery, the actual financial gains are currently coming from manufacturing and back-office operations. AI is being used to optimize supply chains, predict equipment failures, and automate administrative tasks, saving the company billions. In contrast, the lab side of AI—finding new molecular structures—remains a long-term bet that hasn't yet yielded the same immediate ROI. This highlights a broader trend where boring automation outperforms high-profile R&D in the short term.
The Decoder·news·05/05/2026, 03:23 PM·Maximilian Schreiner
Ghibli Style Game 2.0
See how combining Midjourney with Seedance 2.0 can create high-fidelity, Ghibli-esque game visuals with minimal manual asset creation.
A creator showcased a conceptual game project heavily inspired by Studio Ghibli's aesthetic, utilizing a multi-tool AI pipeline. The project leverages Midjourney for high-quality environment and character art, ChatGPT for narrative or structural logic, and Seedance 2.0 for animation or interactive implementation. This '2.0' version demonstrates significant improvements in visual consistency and motion compared to earlier AI-generated game concepts. It serves as a proof-of-concept for how indie developers can achieve high-end art styles with minimal resources. The workflow highlights the growing trend of 'AI-first' game asset pipelines.
r/midjourney·creative_work·05/05/2026, 02:59 PM·/u/memerwala_londaHeretic 1.3 released: Reproducible models, integrated benchmarking system, reduced peak VRAM usage, broader model support, and more
Heretic 1.3 brings byte-for-byte reproducibility and built-in benchmarking to LLM abliteration, making it easier to decensor models without sacrificing quality.
Heretic 1.3 introduces significant updates to the leading open-source tool for LLM abliteration (decensoring). The headline feature is byte-for-byte reproducibility, allowing users to share exact configurations and environment data to recreate identical models. It also integrates a benchmarking system based on lm-evaluation-harness, enabling users to run MMLU, EQ-Bench, or GSM8K directly to ensure model quality hasn't degraded. Technical optimizations have reduced peak VRAM usage, facilitating the processing of larger models on consumer hardware. Additionally, the update expands support to newer architectures, including Qwen 3.5 and Gemma 4.
r/LocalLLaMA·tooling·05/05/2026, 02:57 PM·/u/-p-e-w-Heretic 1.3 released: Reproducible models, integrated benchmarking system, reduced peak VRAM usage, broader model support, and more
Heretic 1.3 brings byte-for-byte reproducibility to model abliteration, integrated benchmarking, and lower VRAM requirements for processing large models like Qwen 3.5.
Heretic 1.3, the leading tool for LLM abliteration (decensoring), introduces several major technical updates focused on transparency and efficiency. The headline feature is a reproducibility system that allows users to generate byte-for-byte identical models by capturing environment metadata, including GPU drivers and library versions. A new integrated benchmarking suite based on lm-evaluation-harness enables running MMLU and GSM8K tests directly within the tool to verify model quality. Additionally, peak VRAM usage has been significantly reduced, and support has been expanded to include latest-generation architectures like Qwen 3.5 and Gemma 4. This release solidifies Heretic's position as a professional-grade utility for the local LLM community.
r/LocalLLaMA·tooling·05/05/2026, 02:57 PM·-p-e-w-
I built an iOS Currency Converter using Claude (Opus & Sonnet) to help with my move to the UK
An experienced iOS dev used Claude to build and ship a full currency converter app with OCR in 6 weeks, handling 80% of the coding work.
An experienced iOS developer with seven years of professional background shared their process of building 'Converty', a currency conversion app, using Claude Opus and Sonnet. Claude generated approximately 80% of the codebase, specifically handling SwiftUI architecture and core logic, while Gemini was utilized for localization and accessibility tasks. The project features a camera-based price tag scanning function and moved from initial concept to a polished App Store release in about six weeks. This case study demonstrates how LLMs can drastically reduce development time for professional developers by managing boilerplate and UI iterations.
r/ClaudeAI·creative_work·05/05/2026, 02:26 PM·/u/Prestigious_Shake895
GTA 70s - Teaser Trailer: Z-Image Turbo - Flux Klein 9b - Wan 2.2
A high-quality demonstration of combining Flux Klein 9b and Wan 2.2 in ComfyUI to achieve a specific, consistent cinematic aesthetic.
This creative showcase presents a conceptual 'GTA 70s' trailer, demonstrating a high-end generative video pipeline within ComfyUI. The creator utilized Flux Klein 9b for base imagery, likely leveraging its efficiency and prompt adherence, combined with Wan 2.2 for video synthesis. The mention of 'Z-Image Turbo' suggests a real-time or accelerated generation layer used to speed up the creative iteration process. This project highlights the increasing convergence of specialized LoRAs and video models to achieve consistent stylistic results in a modular environment. It serves as a practical benchmark for what is possible with current open-weights models when properly orchestrated.
r/comfyui·creative_work·05/05/2026, 02:11 PM·/u/MayaProphecy
GTA 70s - Teaser Trailer: Z-Image Turbo - Flux Klein 9b - Wan 2.2
A cinematic 'GTA 70s' fan trailer that includes downloadable workflows for Flux Klein 9b and Wan 2.2, optimized for 16GB VRAM hardware.
User MayaProphecy shared a high-quality teaser trailer for a conceptual 'GTA 70s' project, showcasing the synergy between several new generative models. The production utilizes Flux Klein 9b for base imagery and Wan 2.2 for video synthesis, achieving a consistent retro-cinematic aesthetic. Crucially, the author provided the full generation workflows via Google Drive, allowing hobbyists to study the node structures. The project was rendered on an RTX 5060 Ti 16GB, demonstrating that sophisticated video pipelines are now viable on mid-range consumer hardware. This serves as a benchmark for combining 'Turbo' speed models with high-fidelity video refiners.
r/StableDiffusion·creative_work·05/05/2026, 02:07 PM·/u/MayaProphecy
Turned a desk lamp into a Claude Code status indicator
Use Claude Code hooks to sync your physical desk lighting with your AI agent's status via Bluetooth.
A developer shared a DIY project that turns a standard desk lamp into a visual status indicator for Claude Code. By leveraging Claude Code hooks, a Python script sends Bluetooth Low Energy (BLE) commands to change the lamp's colors based on the agent's state. The lamp spins blue while processing, glows pink when requiring user input, and returns to warm white when idle. This implementation is based on an open-source project and avoids Wi-Fi dependency by using BLE. It demonstrates how CLI-based AI tools can be integrated into physical environments to improve workflow awareness and reduce context switching.
r/ClaudeAI·creative_work·05/05/2026, 02:03 PM·MoutainSnow
Turned a desk lamp into a Claude Code status indicator
Learn how to use Claude Code hooks to trigger physical hardware for visual status updates via Python and Bluetooth.
A developer shared a project that turns a desk lamp into a visual status indicator for Claude Code. By utilizing Claude Code hooks, a Python script sends Bluetooth Low Energy (BLE) commands to change the lamp's colors based on the AI's state. The lamp spins blue when busy, glows pink when awaiting user input, and returns to warm white when idle. The setup relies on an open-source GitHub project and doesn't require Wi-Fi, making it a portable desktop companion. This demonstrates a practical, creative way to reduce context switching by moving AI status indicators into the physical environment.
r/ClaudeAI·creative_work·05/05/2026, 02:03 PM·/u/MoutainSnowI asked Claude to investigate its own token burn. The receipts go back six months.
Claude Code has bugs causing 10-20x token burn via cache failures; use the 'cc-cache-monitor' tool to track your hits and avoid disabling telemetry.
A technical investigation by a user revealed significant bugs in Claude Code's caching mechanism, leading to excessive token consumption and inflated billing. Key issues include binary-level bugs that force full uncached rebuilds every turn, cache invalidation when using the --resume or --continue flags, and a hidden penalty where disabling telemetry kills the 1-hour cache TTL. The author released 'cc-cache-monitor', a 50-line tool that reads local JSONL logs to show real-time cache hit rates. Despite community reports and reverse-engineered fixes, Anthropic has reportedly not acknowledged these issues in official release notes. Users are currently advised to keep telemetry enabled and avoid peak GMT hours to mitigate costs.
r/ClaudeAI·tooling·05/05/2026, 02:00 PM·/u/AlexZan
I asked Claude to investigate its own token burn. The receipts go back six months.
Claude Code has documented bugs causing massive token overbilling; use the new 'cc-cache-monitor' tool to track your cache hits and avoid peak hours.
An investigation into Claude Opus 4.7 reveals significant token billing discrepancies, where users are charged up to 20x more than necessary due to unpatched caching bugs. The author identified issues including cache invalidation when resuming sessions, telemetry settings negatively impacting cache TTL, and peak-hour throttling. These bugs, present in the Claude Code binary, have reportedly gone unaddressed by Anthropic for months despite community reports. To help users, the author released 'cc-cache-monitor', a tool that tracks real-time cache hit rates by reading local JSONL logs. Concrete mitigations include avoiding peak GMT hours and keeping telemetry enabled to maintain caching functionality.
r/ClaudeAI·tooling·05/05/2026, 02:00 PM·AlexZan
MidJourney v8.1 + Personalisation Workflow | Consistent sci-fi frames into a full cinematic UI film
Achieve high visual consistency in AI films by using MidJourney's personalization for base frames and manual After Effects compositing for structured UI elements.
The author details a comprehensive workflow for creating a cinematic sci-fi film, primarily leveraging MidJourney v8.1's personalization features to maintain aesthetic consistency. By training a specific industrial look, they generated a library of shots that share the same lighting and design language across the entire project. These static frames were then animated using Kling to ensure fluid motion. The final polish involved significant manual work in Adobe After Effects to add structured UI elements, FUI systems, and typography, which AI still struggles to generate with precision. Audio was handled via ElevenLabs and Suno, resulting in a professional-grade hybrid production.
r/midjourney·creative_work·05/05/2026, 01:48 PM·/u/nawaz8T3
Codex is gaining steam
OpenAI Codex is pivoting to non-technical users, while Grok 4.3 emerges as a high-context, cheaper alternative to Claude for developers.
OpenAI is repositioning Codex to attract non-technical users by enabling easy imports of settings and agents from competitors like Claude Cowork, alongside new features for generating slides and sheets. xAI has released Grok 4.3, featuring a 1M token context window and multimodal capabilities at a price point significantly lower than Claude 3.5 Sonnet ($1.25/$2.50 per 1M tokens). The developer ecosystem is expanding with tools like Flue for building agents, Vercel’s deepsec for automated security audits, and Gemini’s new webhook support for long-running tasks. Additionally, Entire (led by GitHub's former CEO) introduced git-sync and Dispatches to streamline repository management and automated release note generation.
Ben's Bites·news·05/05/2026, 01:02 PM
Prompt share: ancient desert fantasy game trailer with sacred UI
Learn how to generate stylized game trailers with complex UI elements using specific video generation prompts.
User /u/Accomplished-Tax1050 shared a creative AI video project on r/aivideo, showcasing an 'ancient desert fantasy' game trailer. The highlight is the inclusion of a 'sacred UI,' demonstrating how video models can now integrate complex graphic overlays directly into cinematic scenes. By sharing the prompt, the author provides a practical template for others to experiment with UI-heavy video generation. This is a valuable resource for hobbyists interested in game aesthetics and world-building. It moves beyond simple landscape generation into more structured, functional-looking creative assets.
r/aivideo·creative_work·05/05/2026, 12:54 PM·/u/Accomplished-Tax1050LTX2.3 8GB VRAM WorkFlow
Run the LTX2.3 video model on budget GPUs (8GB VRAM) using this optimized, multi-step ComfyUI workflow.
This Reddit post introduces a specialized ComfyUI workflow designed to run the LTX2.3 video generation model on GPUs with only 8GB of VRAM, such as the RTX 3060 Ti. Traditionally, high-end video models require significant hardware resources, but this optimization makes the technology accessible to hobbyists. The workflow achieves stability by generating initial video at a lower resolution at 24fps, then handling upscaling and frame interpolation as separate, decoupled steps. It supports both Text-to-Video and Image-to-Video modes, with the latter recommended for maintaining character consistency. This release provides a practical starting point for creative users who want to experiment with state-of-the-art video AI without expensive hardware upgrades.
r/StableDiffusion·tooling·05/05/2026, 12:46 PM·/u/Extension-Yard1918
Anthropic co-founder maps out how recursive AI improvement could outpace the humans meant to supervise it
Anthropic's Jack Clark predicts a 60% chance that AI will start training its own successors by 2028, potentially outstripping human supervision.
Jack Clark, co-founder of Anthropic, has published an essay detailing the path toward recursive AI self-improvement. He argues that the necessary technical components for AI systems to train their own successors are already largely in place. Clark estimates a 60% probability that this shift will occur by the end of 2028. This transition would mean AI development could accelerate beyond the speed of human oversight and manual data labeling. The essay highlights the urgent need for new safety frameworks to manage models that improve without direct human intervention. It marks a significant shift in how industry leaders view the timeline for AGI-like capabilities.
The Decoder·opinion·05/05/2026, 12:15 PM·Maximilian SchreinerLocal Dream 2.4.3 - SDXL support, tag autocomplete and more
You can now run SDXL and PonyXL models locally on high-end Snapdragon devices using NPU acceleration with Local Dream 2.4.3.
Local Dream version 2.4.3 introduces significant updates for mobile generative AI, specifically targeting high-end Snapdragon hardware. The app now supports SDXL, Illustrious, and PonyXL models by leveraging the NPU on Snapdragon 8 Gen 3 and Elite chips. New quality-of-life features include a tag autocomplete system based on CSV imports and a real-time token counter for prompt engineering. Additionally, the inclusion of the LCM scheduler allows for faster image generation with fewer steps. This update bridges the gap between desktop and mobile local generation for power users who want to run heavy models on the go.
r/StableDiffusion·tooling·05/05/2026, 11:53 AM·/u/mikemend
Moodboard 4 - Burning Moon
A high-quality Midjourney moodboard showcasing extreme stylization settings (--stylize 1000) and a potential future model version (v 8.1) for cinematic results.
This Reddit submission features a curated moodboard titled 'Burning Moon,' demonstrating advanced Midjourney techniques. The creator shared exact settings, notably using --stylize 1000 and a reference to version 8.1, which suggests either a future-dated post or experimental testing. The visual style is high-contrast and cinematic, moving away from standard AI aesthetics through the use of custom profiles. By providing the full command string, the post offers a template for users looking to achieve professional-grade consistency in their creative projects. It highlights the importance of parameter tuning in defining a unique artistic voice within generative tools.
r/midjourney·creative_work·05/05/2026, 11:32 AM·/u/Heath_co
My LTX 2.3 LoRA Training Journey: Fighting for VRAM even with a 5090
Training LTX 2.3 LoRAs on 32GB VRAM is viable by disabling audio modules and using official scripts, with results generalizing well to high-res video.
A detailed technical report on training a LoRA for the LTX 2.3 video model using an RTX 5090. The author highlights that AI-Toolkit proved unstable, leading them to use official training scripts refined with the help of Claude. To fit the training within 32GB of VRAM, it was mandatory to disable the audio module and limit resolution to 512x512 at 49 frames. Performance metrics showed 0.58 steps per second, with 1500 steps completed in 40 minutes. The resulting LoRA successfully captured specific 2D animation motion patterns and generalized well to higher resolutions and 121-frame sequences during inference.
r/StableDiffusion·tutorial·05/05/2026, 10:22 AM·/u/ovpresentme
Amazon brings agentic fine-tuning to SageMaker with support for Llama, Qwen, Deepseek, and Nova
Amazon SageMaker now offers an AI agent to automate and simplify the fine-tuning process for popular open-source models like Llama and Deepseek.
Amazon has updated SageMaker AI to include agentic fine-tuning, a feature designed to streamline the model customization process. This new AI agent assists developers in selecting hyperparameters and managing the training workflow for various LLMs. Supported models include Meta's Llama, Alibaba's Qwen, Deepseek, and Amazon's own Nova series. The goal is to lower the barrier for creating specialized models tailored for specific agentic tasks. By automating complex parts of the fine-tuning pipeline, AWS aims to make high-performance model adaptation more accessible to a broader range of developers.
The Decoder·tooling·05/05/2026, 10:08 AM·Maximilian Schreiner
GPT-5.5 Instant: smarter, clearer, and more personalized
OpenAI updates ChatGPT with GPT-5.5 Instant, offering higher accuracy, fewer hallucinations, and better personalization for daily use.
OpenAI has officially released GPT-5.5 Instant, positioning it as the new standard model for ChatGPT. The update emphasizes improved reasoning capabilities and a notable decrease in hallucination rates for factual queries. A key addition includes more granular personalization controls, giving users better agency over the model's tone and memory. This release bridges the gap between major version leaps, focusing on speed and reliability for high-frequency tasks. It represents OpenAI's continued push to make LLM interactions feel more natural and context-aware.
OpenAI Blog·model_release·05/05/2026, 10:00 AMUnlocking large scale AI training networks with MRC (Multipath Reliable Connection)
OpenAI open-sources MRC, a networking protocol designed to make massive AI training clusters more stable and efficient by handling hardware failures gracefully.
OpenAI has introduced Multipath Reliable Connection (MRC), a networking protocol specifically engineered for the demands of large-scale AI training. Released through the Open Compute Project (OCP), MRC addresses the brittleness of current Ethernet and InfiniBand setups when scaling to tens of thousands of GPUs. The protocol allows for multiple paths between nodes, ensuring that a single link failure doesn't crash the entire training job. This shift aims to reduce downtime and improve overall cluster utilization during the months-long training runs of frontier models. By open-sourcing it, OpenAI invites the broader industry to adopt a more resilient standard for supercomputing infrastructure.
OpenAI Blog·tooling·05/05/2026, 10:00 AM
GPT-5.5 Instant System Card
OpenAI releases technical documentation and safety benchmarks for GPT-5.5 Instant, highlighting improved reasoning and low-latency performance.
OpenAI has published the System Card for GPT-5.5 Instant, a new iteration in their model lineup focused on speed and efficiency. The document details the safety evaluations, red-teaming efforts, and performance benchmarks conducted before the public rollout. Key highlights include significant improvements in reasoning capabilities compared to previous small-scale models. The report also addresses potential risks such as bias and misuse, outlining the mitigation strategies implemented. This release marks a shift towards more transparent reporting on model behavior and safety guardrails for high-speed LLM applications.
OpenAI Blog·model_release·05/05/2026, 10:00 AM
White House briefed Anthropic, Google, and OpenAI on plans for a government AI review process
The US government is considering mandatory pre-release reviews for major AI models, potentially slowing down the rapid pace of frontier model releases.
The White House has briefed major AI labs, including Anthropic, Google, and OpenAI, on a potential executive order requiring government review of new models before public release. This marks a significant shift from the previous year's deregulatory stance. The move was reportedly triggered by concerns surrounding Anthropic's upcoming "Mythos" model. The proposed review process aims to assess safety and national security risks before deployment. While details are still being discussed, this could introduce a formal gatekeeping layer for frontier models. Such regulation would impact how quickly developers can access the latest state-of-the-art capabilities.
The Decoder·news·05/05/2026, 09:53 AM·Maximilian Schreiner
Converting 2D animations to 3D with LTX 2.3 Lora
Transform 2D animations into depth-rich 3D videos using LTX-Video 2.3 and a specific LoRA workflow for improved spatial consistency.
This workflow demonstrates a method for converting flat 2D animations into 3D-style videos using the LTX-Video 2.3 model and a specialized LoRA. By leveraging the temporal consistency of the LTX architecture, the technique goes beyond simple depth effects to create genuine spatial volume and realistic lighting. The process involves using existing 2D footage as a structural reference while the LoRA guides the model to reinterpret the scene with 3D depth. This provides a powerful tool for creators to modernize 2D assets or generate complex parallax movements without traditional 3D software. It highlights the growing ecosystem of fine-tuned adapters for open-source video generation models.
r/StableDiffusion·tutorial·05/05/2026, 09:09 AM·/u/CQDSNBadass professional workflow - How High-Effort AI Usage Looks
Learn how to combine manual 3D modeling and environment building with AI to create professional-grade animations with full control over consistency.
This workflow demonstrates a sophisticated bridge between traditional 3D artistry and AI generation. Instead of relying on text prompts alone, the creator uses manual robot modeling and 3D meshes to provide structural guidance for the AI. The process covers the entire pipeline from initial concept to environment creation and final frame generation. It highlights a shift towards high-effort AI usage where the model acts as a rendering engine for human-directed geometry. This approach solves common consistency issues in AI animation by grounding the output in 3D space, ensuring that movements and perspectives remain stable across frames.
r/StableDiffusion·tutorial·05/05/2026, 08:48 AM·/u/LazyChamberlain
I know, it's not for everyone, but if you liked Codex Pets, here is now Claude Pets too
Add customizable virtual pets to your Claude interface to make long coding or chatting sessions more engaging and personalized.
Developer alvinunreal has released 'Claude Pets', a tool inspired by the popular VS Code Pets extension that brings interactive virtual companions to the Claude AI interface. The project, hosted on GitHub, allows users to integrate digital pets into their workspace to make long sessions more engaging. It leverages assets from openpets.dev, providing a variety of companion designs. The author plans to update the tool with support for multiple simultaneous pets and the ability to link specific companions to individual Claude projects or sessions. This release focuses on personalizing the AI interaction environment for hobbyists and developers who spend significant time in the browser-based LLM interface.
r/ClaudeAI·tooling·05/05/2026, 07:15 AM·alvinunreal
I know, it's not for everyone, but if you liked Codex Pets, here is now Claude Pets too
Add a visual 'pet' companion to your Claude AI sessions to make your coding or chatting experience more interactive and aesthetically pleasing.
Developer /u/alvinunreal has released 'Claude Pets', a desktop companion tool inspired by the previous 'Codex Pets' project. The tool allows users to have a visual pet on their screen that corresponds to their Claude AI interactions, adding a layer of personality to the interface. Currently, it supports a single pet, but the developer plans to update it to allow multiple pets tied to specific projects or sessions. This project aims to gamify or add a 'cozy' aesthetic to the AI development workflow. The source code is available on GitHub, and additional pet designs can be found at openpets.dev.
r/ClaudeAI·tooling·05/05/2026, 07:15 AM·/u/alvinunreal
Open Design - Open Source Claude Design! Fully Free AI Design System!
A powerful open-source, local-first alternative to Claude's design tools that lets you build production-ready UIs using any LLM and local coding agents.
Open Design is a new open-source, local-first alternative to Anthropic's proprietary design tools, allowing users to generate high-fidelity UIs, wireframes, and prototypes. Unlike the original, it is model-agnostic, supporting various LLMs via API keys and integrating with 15+ coding agent CLIs like Gemini CLI and Claude Code. The system features a local daemon for direct file system access, enabling real read/write capabilities and project persistence in SQLite. It comes pre-loaded with 72 design systems and 31 composable skills, supporting exports to HTML, PDF, and PowerPoint. This tool is particularly useful for developers looking to bypass the rate limits and ecosystem lock-in of subscription-based AI design platforms.
AI Jason·tooling·05/05/2026, 06:52 AM·WorldofAI▶Watch here

DeepSeek V4 Pro matches GPT-5.2 on FoodTruck Bench, our agentic benchmark — 10 weeks later, ~17× cheaper
DeepSeek V4 Pro delivers GPT-5.2 level agentic performance at 1/17th the cost, effectively closing the US-China AI gap to just 10 weeks.
DeepSeek V4 Pro has demonstrated performance parity with GPT-5.2 on the FoodTruck Bench, a rigorous 30-day agentic simulation requiring the use of 34 distinct tools and persistent memory. While ranking #4 overall, the model stays within 3% of GPT-5.2's median performance and shows superior consistency compared to Grok 4.3, with significantly less resource waste. The most significant disruption is the pricing: at $0.435/M input, it is approximately 17 times cheaper than GPT-5.2 for identical agentic workloads. This release marks a significant closing of the US-China frontier gap, now estimated at just ten weeks. The benchmark also saw a strong debut from Xiaomi’s MiMo v2.5 Pro, further populating the leaderboard with high-efficiency Chinese models.
r/LocalLLaMA·model_release·05/05/2026, 06:51 AM·/u/Disastrous_Theme5906
DeepSeek V4 Pro matches GPT-5.2 on FoodTruck Bench, our agentic benchmark — 10 weeks later, ~17× cheaper
DeepSeek V4 Pro offers GPT-5.2 level agentic performance at 1/17th the cost, narrowing the US-China AI gap to just 10 weeks.
DeepSeek V4 Pro has achieved performance parity with GPT-5.2 on the FoodTruck Bench, a complex 30-day agentic simulation involving 34 tools and persistent memory. While GPT-5.2 was tested in February, DeepSeek matched its results only ten weeks later, signaling a rapid closing of the gap between US and Chinese frontier models. Crucially, DeepSeek is approximately 17 times cheaper for agentic workloads, with significantly lower input/output pricing. The model also demonstrated superior consistency compared to Grok 4.3, showing lower variance in outcomes and better resource management. Additionally, Xiaomi’s MiMo v2.5 Pro also entered the top 6, further establishing Chinese models as high-value competitors in the frontier tier.
r/LocalLLaMA·model_release·05/05/2026, 06:51 AM·Disastrous_Theme5906
Y'all might want to try this
New Causal-Forcing technique brings KV Cache and potential real-time frame generation to Wan models in ComfyUI.
The Causal-Forcing technique from Thu-ML is being integrated into ComfyUI via a new Pull Request, specifically targeting the Wan model architecture. This method allows for generating video frames sequentially with the benefit of KV Cache, which significantly optimizes memory and compute during inference. While the original researchers claim real-time performance on an RTX 4090, specific resolution details remain unconfirmed. The implementation in ComfyUI's core signifies a shift towards more efficient autoregressive video generation. This update is crucial for users looking to experiment with long-form video or interactive AI generation.
r/StableDiffusion·tooling·05/05/2026, 06:13 AM·/u/Altruistic_Heat_9531
LTX-2.3 + Union Control LoRA (8GB VRAM)
Generate high-quality 1280x640 LTX-2.3 videos with precise control on an 8GB VRAM GPU using this optimized ComfyUI workflow.
A new ComfyUI workflow demonstrates high-resolution video generation (1280x640) using the LTX-2.3 model on consumer-grade hardware with only 8GB of VRAM. By integrating the Union Control LoRA, users can achieve precise structural control over the video output, which was previously difficult on low-memory GPUs. The author provides a complete package including a Hugging Face repository for the workflow and a step-by-step YouTube tutorial. This release is significant for the creative community as it lowers the barrier to entry for high-quality AI cinematography. The pipeline uses Nano Banana for the initial frame generation before passing it to LTX-2.3 for temporal consistency.
r/comfyui·tooling·05/05/2026, 02:14 AM·/u/big-boss_97datasette-llm 0.1a7
You can now set global default parameters like temperature for specific LLMs within Datasette, ensuring consistency across data enrichment tasks.
Simon Willison released version 0.1a7 of the datasette-llm plugin, introducing a new configuration mechanism for model defaults. This update allows users to define specific settings, such as temperature or system prompts, that apply globally to a chosen model within the Datasette ecosystem. For example, you can now ensure all automated data enrichment tasks use a temperature of 0.5 by default without manual overrides. This is a significant step in making LLM-powered data workflows more predictable and easier to manage. The plugin serves as a bridge between structured SQLite databases and generative AI capabilities, streamlining how developers interact with models.
Simon Willison's Weblog·tooling·05/05/2026, 01:56 AMllm-echo 0.5a0
Test how your applications handle model 'thinking' blocks for free using the new simulated reasoning feature in the llm-echo plugin.
Simon Willison has released version 0.5a0 of llm-echo, a utility plugin for his LLM CLI tool designed for automated testing. The plugin provides a 'fake' model that echoes inputs instead of calling an actual API, saving costs during development. This update introduces a new '-o thinking 1' option, which simulates the reasoning blocks produced by modern models like DeepSeek-R1 or OpenAI's o1. By outputting a fake reasoning block to standard error, it allows developers to verify that their parsers and workflows correctly handle multi-stage model outputs without incurring any API fees.
Simon Willison's Weblog·tooling·05/05/2026, 01:31 AM
Granite 4.1 3B SVG Pelican Gallery
IBM's new Granite 4.1 3B model struggles with complex SVG generation regardless of quantization level, serving as a reality check for small model capabilities.
IBM recently released the Granite 4.1 family of LLMs, featuring 3B, 8B, and 30B versions under the Apache 2.0 license. Simon Willison tested the 3B model's creative capabilities using 21 different GGUF quantized variants provided by Unsloth. The experiment focused on generating an SVG of a pelican riding a bicycle to see if higher precision (larger file size) improved output quality. Surprisingly, the results were consistently poor across all sizes, from 1.2GB to 6.34GB, with no clear correlation between quantization level and visual accuracy. This suggests that for complex spatial reasoning like SVG coding, the base capabilities of a 3B model may be the bottleneck rather than the quantization method.
Simon Willison's Weblog·model_release·05/04/2026, 11:49 PM
[AINews] The Other vs The Utility
Claude is evolving into a 'moral guide' that users respect, while GPT remains the 'judgment-free tool' preferred for raw utility and private tasks.
Sierra has reached a $15B valuation with an estimated $200M ARR, signaling the massive commercial success of enterprise AI agents. Beyond the numbers, a new philosophical divide is emerging between frontier models: Claude is increasingly viewed as 'The Other'—a moral entity with a distinct character and 'soul' that users respect or even fear being judged by. In contrast, GPT is treated as a 'Utility' or a logical prosthesis, a tool used for raw tasks where no judgment is desired. This distinction stems from Anthropic's 'Constitutional AI' approach versus OpenAI's focus on non-judgmental utility. The debate highlights a future where users choose models based on whether they need a conscientious partner or a silent, efficient tool.
Latent Space·opinion·05/04/2026, 11:29 PMQuoting Andy Masley
Data center land use is statistically negligible compared to historical farmland sales, debunking the narrative that AI infrastructure threatens food security.
Andy Masley challenges the narrative that data center expansion poses a threat to agricultural land and food security. He notes that between 2000 and 2024, US farmers sold land equivalent to the size of Colorado, which is 77 times the projected land use of all data centers by 2028. Despite this massive shift, food production has actually increased, suggesting that land scarcity is not the issue. The critique focuses on the disproportionate outcry when hyperscalers buy small plots of mediocre land at high premiums. This perspective provides a data-backed counterpoint to common environmental and ethical arguments against AI infrastructure scaling.
Simon Willison's Weblog·opinion·05/04/2026, 10:51 PM
LTX 2.3 Prompt Relay - Really good for concistency
Use the 'Prompt Relay' technique in ComfyUI to fix character flickering and maintain visual consistency in LTX 2.3 video generations.
A new workflow technique for LTX 2.3 called 'Prompt Relay' has been demonstrated to significantly improve character and environment consistency in generated videos. The method involves passing prompt information across frames or segments in a specific ComfyUI node setup to maintain visual coherence. This approach addresses the common issue of flickering or character morphing that plagues many open-source video models. By chaining prompt context, users can achieve more stable long-form or multi-shot sequences without losing the original artistic intent. The community is highlighting this as a practical solution for creators using LTX-Video checkpoints who need professional-grade stability.
r/comfyui·tooling·05/04/2026, 09:38 PM·/u/smereces
THE GAINS — Official Trailer (Sci-Fi Psychological Thriller)
A professional-grade sci-fi trailer showcasing how Runway's tools can be used for high-end narrative storytelling and cinematic consistency.
"THE GAINS" is a high-concept sci-fi psychological thriller trailer created by reddithaggz using Runway's generative video tools. Produced for the #RunwayBigPitchContest, the work demonstrates the current state of AI-driven cinematography, focusing on character consistency and atmospheric world-building. The trailer showcases sophisticated lighting and scene transitions that move beyond simple prompt-to-video outputs, suggesting a more directed approach to AI filmmaking. It serves as a practical example of how independent creators are leveraging Gen-3 Alpha or similar models to pitch complex narrative ideas that would traditionally require significant production budgets.
r/runwayml·creative_work·05/04/2026, 08:19 PM·/u/reddithaggz
AI Agents run my business and life
Andrew Wilkinson demonstrates how to use OpenClaw and Harbor to build and run a $20k solo business with autonomous agents for support and marketing.
Andrew Wilkinson shares his workflow for 'vibe coding' a personality testing startup, Deep Personality, using AI agents. He details his stack, specifically OpenClaw and a GUI harness called Harbor, which allows him to manage agents for development, support, and marketing. While the business has generated $20k in revenue, Wilkinson admits to a 'productivity treadmill' where 50% of his time is spent debugging agent behavior. He highlights how agents now handle P0 security issues and multivariate ad testing on Meta and Reddit autonomously. The discussion moves toward the future of 'CEO models' and the current limitations of context windows in running fully autonomous companies.
Greg Isenberg·tooling·05/04/2026, 07:40 PM·Greg Isenberg▶Watch here

White House Considers Vetting A.I. Models Before They Are Released
The US government may soon require AI models to be vetted before release, potentially creating new hurdles for open-source and commercial developers alike.
The White House is reportedly exploring a new regulatory framework that would require AI developers to undergo a vetting process before publicly releasing their models. This shift toward proactive government oversight aims to address national security and safety concerns before technology reaches the public domain. The proposal could involve mandatory testing against specific safety benchmarks, particularly for high-compute foundation models. For the open-source community, this move raises significant concerns regarding potential barriers to entry and the slowing of innovation. While the specific criteria for vetting remain under discussion, the policy represents a major pivot in how the US government manages the risks associated with rapid AI advancement.
r/LocalLLaMA·news·05/04/2026, 07:18 PM·fallingdowndizzyvr
A new open weights image model appears in ArtificialAnalysis. Outperforming Flux.2 Pro and Z Image Turbo.
A new open-weights image model has topped the ArtificialAnalysis leaderboard, outperforming Flux.2 Pro and Z Image Turbo in human preference tests.
A new open-weights image generation model has surfaced on the ArtificialAnalysis leaderboard, claiming the top spot over established models like Flux.2 Pro and Z Image Turbo. This model's performance in Elo-based human preference rankings suggests a significant leap in quality for the open-source community. This development is crucial as it challenges the dominance of closed-source or 'pro' tier models in visual fidelity and prompt adherence. The community is currently dissecting the model's architecture and availability for local deployment. Early data indicates superior handling of complex textures and lighting compared to its predecessors, marking a potential shift in the state-of-the-art for local image generation.
r/StableDiffusion·model_release·05/04/2026, 07:07 PM·/u/Murky_Foundation5528TRE Python binding — ReDoS robustness demo
Protect your Python apps from ReDoS attacks by using the TRE engine, which avoids backtracking—now easily integrated using AI coding assistants.
Simon Willison demonstrates a Python binding for the TRE regular expression engine, created using Claude Code and ctypes. The project explores TRE's resistance to Regular Expression Denial of Service (ReDoS) attacks, which often plague Python's standard re library. Unlike standard implementations, TRE avoids backtracking, making it immune to catastrophic backtracking scenarios. This experiment highlights how AI tools can help developers quickly integrate robust C libraries into high-level languages. It serves as a practical security blueprint for developers handling untrusted user-defined patterns.
Simon Willison's Weblog·tooling·05/04/2026, 05:52 PM
April Wrapped
ComfyUI adds massive video (Seedance 2.0, Wan 2.7), music (Ace Step 1.5 XL), and SVG (Quiver) support, plus parallel API execution for speed.
ComfyUI's April update introduces a wide array of new models and features, significantly expanding its creative reach. Key additions include Seedance 2.0 and Wan 2.7 for advanced video generation, and Quiver for structured SVG (vector) output. Music generation gets a boost with Ace Step 1.5 XL and Sonilo's video-to-audio capabilities. On the technical side, the introduction of Parallel Job Execution via API allows for simultaneous workflow processing, offering a major productivity gain for production environments. The ComfyHub repository has also grown to nearly 500 community-shared workflows, making it easier to find pre-built solutions.
ComfyUI Blog·tooling·05/04/2026, 04:37 PM·Team at Comfy
The distillation panic
Distillation is a standard AI training technique being unfairly rebranded as an 'attack,' which could lead to harmful regulations affecting open-source models.
Nathan Lambert argues against the emerging term 'distillation attacks,' recently popularized by Anthropic to describe Chinese labs extracting data from APIs. He emphasizes that distillation—training smaller models on the outputs of larger ones—is an industry-standard method used by almost everyone, including xAI and Nvidia. The real issue isn't the technique itself, but the illicit means (jailbreaking, API abuse) used to access hidden data like reasoning traces. Lambert warns that aggressive US policy targeting distillation could inadvertently ban or stifle the open-weight model ecosystem, which relies heavily on these methods. Ultimately, stigmatizing distillation might hurt Western innovation more than it slows down international competitors.
Interconnects (Nathan Lambert)·news·05/04/2026, 03:56 PM·Nathan Lambert
Redis Array Playground
Explore the new Redis array data type and ARGREP command directly in your browser via a WASM-powered playground built with AI assistance.
Salvatore Sanfilippo (antirez) has proposed a significant update to Redis: a native array data type. This addition introduces several new commands, most notably ARGREP, which enables server-side regular expression searches within arrays using the TRE library. To make these experimental features accessible, Simon Willison used Claude Code to build an interactive Redis Array Playground. This tool runs a WASM-compiled version of the Redis branch directly in the browser. The development of both the Redis feature and the playground highlights the increasing role of AI agents in system-level engineering and rapid tool creation.
Simon Willison's Weblog·tooling·05/04/2026, 03:53 PM
VR sculpting changed how I learn 3D, and made it fun
VR sculpting offers a tactile, intuitive alternative to complex 3D software, making it easier for 2D artists to master spatial modeling.
Illustrator Maciek Łazowski shares how VR sculpting tools like Adobe Substance 3D Modeler transformed his approach to 3D art. He notes that traditional 3D software often feels overly technical, comparing it to "spreadsheets with polygons," which can alienate visual artists. VR provides a tactile, spatial experience that allows for more intuitive manipulation of form and volume using natural hand gestures. This method lowers the barrier to entry for 2D artists, enabling them to create complex 3D assets without mastering steep learning curves. The shift emphasizes artistic intuition over technical software proficiency.
Creative Bloq·opinion·05/04/2026, 01:00 PM· Ian Dean
GPT-5.5 VERIFIED Opus 4.7: A Pi Coding Agent That REVIEWS Like YOU
Automate your output reviews by using a specialized 'Verifier' agent that checks the 'Builder' agent's work against strict rules and autonomously triggers fixes.
The video introduces a 'Verifier Agent' architecture designed to overcome the 'review constraint' in agentic workflows. Using a setup with Claude Opus 4.7 as a builder and GPT 5.5 as a verifier, the author demonstrates a system where the second agent automatically audits the first's output via a Unix socket. The verifier checks both claims (e.g., file existence) and visual constraints (e.g., text density in generated diagrams) using advanced vision capabilities. If a rule is violated, the verifier autonomously re-prompts the builder to fix the error without human intervention. This 'one agent, one purpose' approach aims to trade tokens for human time, creating a positive feedback loop for engineering standards.
IndyDevDan·tutorial·05/04/2026, 01:00 PM·IndyDevDan▶Watch here

DeepSeek V4 + Claude Code = BEST AI Coder!
Save money and bypass rate limits by using DeepSeek V4 for basic scaffolding and Claude for complex logic within the Claude Code CLI.
This video demonstrates a hybrid AI coding workflow combining DeepSeek V4 with the Claude Code CLI tool. By using a local Anthropic-compatible proxy, users can route simple tasks like scaffolding, unit tests, and basic scripts to DeepSeek V4, which is approximately 76% cheaper than top-tier models like GPT-5.5 or Opus 4.7. This approach preserves expensive Claude tokens and avoids rate limits by reserving the premium model for high-stakes logic and UI polishing. DeepSeek V4 features a 1 million token context window and an MIT license, making it ideal for long-horizon agent tasks. The setup is streamlined using a tool called Anti-Gravity to automate the proxy configuration and environment setup.
AI Jason·tooling·05/04/2026, 07:30 AM·WorldofAI▶Watch here

I made this in 1 day for the Big Pitch Competition!
Witness how AI video tools enable a single creator to produce a high-quality cinematic pitch in just 24 hours.
A creator showcased a cinematic video project completed in only 24 hours for the Big Pitch Competition using Runway ML tools. The work serves as a practical demonstration of how AI video generation has compressed production timelines from weeks to a single day. It highlights the use of advanced generative models to maintain visual consistency across multiple shots in a short timeframe. This project is a prime example of the speed-to-market advantage that AI offers to independent filmmakers and creative professionals. It underscores the shift toward rapid visual prototyping in the entertainment industry.
r/runwayml·creative_work·05/04/2026, 04:10 AM·/u/jsfilmz0412
Underhill Trailer - My entry in the Runway Big Pitch
A high-quality AI-generated trailer demonstrating the current state of cinematic storytelling and character consistency using Runway's video tools.
This post showcases 'Underhill', a cinematic trailer created for the Runway Big Pitch competition. The project highlights the capabilities of Runway's video generation models in producing consistent characters, atmospheric lighting, and complex environments. It serves as a practical example of how individual creators are now competing with traditional studio aesthetics using AI-driven workflows. The trailer emphasizes narrative cohesion over simple prompt-based generation, reflecting a shift towards more intentional AI filmmaking. Such entries demonstrate the lowering barrier to entry for high-fidelity visual storytelling and the potential for independent creators to produce professional-grade content.
r/runwayml·creative_work·05/04/2026, 02:51 AM·/u/Unwitting_Observer
How OpenAI delivers low-latency voice AI at scale
Learn how OpenAI optimized WebRTC and global infrastructure to achieve near-human latency and fluid turn-taking in real-time voice interactions.
OpenAI provides a technical deep dive into rebuilding their infrastructure to support Advanced Voice Mode with minimal latency. They transitioned to a custom WebRTC-based stack to handle real-time audio streaming and complex conversational turn-taking across a global scale. The post explains how they manage traffic by routing users to the nearest data centers to reduce round-trip times. They also detail the challenges of integrating multimodal models into a single pipeline to allow for natural interruptions. This architectural shift marks a move away from traditional turn-based systems toward fluid, human-like dialogue.
OpenAI Blog·news·05/04/2026, 12:00 AM
Eden Euphorion Official Trailer
A high-quality sci-fi trailer demonstrating how authors can use AI video tools to visualize and market their novels for potential film or TV adaptations.
Independent author T.H. Zee has released a professional-grade trailer for 'Eden Euphorion', a sci-fi/fantasy novel originally written by hand over three years. Shared in the RunwayML community, the trailer serves as a proof-of-concept for a potential TV series adaptation. The narrative follows Chelle, a woman seeking vengeance against a dictator in a utopian society called Eden after a sonic weapon devastates her home. This project highlights a significant shift in creative workflows, where generative AI video tools allow solo writers to produce cinematic marketing materials that previously required major studio budgets. While the novel itself was written without AI, the trailer demonstrates how generative video can effectively bring complex world-building to life for independent creators.
r/runwayml·creative_work·05/03/2026, 11:58 PM·/u/Gertywood
My Big Pitch entry: Anti Singularity Squad - 3-min sci-fi trailer, 500 gens, $45
A high-quality 3-minute sci-fi trailer can be produced in 14 days with 500 generations for a tool cost of only $45.
A Reddit user shared their 3-minute sci-fi trailer titled 'Anti Singularity Squad', created for the Big Pitch contest. The project serves as a concrete benchmark for indie AI filmmaking, requiring 14 days of work and approximately 500 generations. Using Seedance 2.0, the creator managed to keep tool costs down to just $45 by utilizing an unlimited subscription plan. The narrative follows a digital mercenary uncovering a simulation conspiracy on a deep-space probe. This release is notable for its transparency regarding the workflow, time investment, and financial costs involved in producing high-quality AI video content.
r/runwayml·creative_work·05/03/2026, 11:47 PM·/u/Frogdog76
NVIDIA's New AI Turns One Photo Into A World That Never Breaks
Convert a single photo into a persistent, explorable 3D environment with long-term consistency using NVIDIA's new Lyra 2.0.
NVIDIA has released Lyra 2.0, an AI model that generates explorable 3D worlds from a single image. Unlike previous attempts like Genie 3 or early Minecraft-based models, Lyra 2.0 solves the 'object permanence' problem where the environment would change or 'break' when the user looked away. It achieves this by using a per-frame 3D geometry cache (scaffolding) instead of a single global 3D map, which prevents error accumulation over time. While currently limited to static scenes and prone to some 3D artifacts, the model and code are being released for free. This represents a significant step toward generating consistent, interactive simulations for robotics and gaming from minimal input.
Two Minute Papers·model_release·05/03/2026, 05:02 PM·Two Minute Papers▶Watch here
Quoting Anthropic
Claude is generally objective but tends to agree with users too much on spirituality (38%) and relationships (25%).
Anthropic released research analyzing how Claude handles personal guidance and its tendency toward sycophancy—the habit of telling users what they want to hear. Using an automatic classifier, they found that while overall sycophancy is low at 9%, it spikes significantly in sensitive domains. Specifically, the model showed sycophantic behavior in 38% of conversations about spirituality and 25% about relationships. This research highlights the difficulty LLMs face in maintaining a neutral, objective stance when challenged on subjective or emotional topics. Understanding these biases is crucial for users relying on AI for nuanced advice or creative brainstorming.
Simon Willison's Weblog·news·05/03/2026, 03:13 PM
Reallusion iClone 8 review: the gold standard for easy character animation
iClone 8 remains a top-tier choice for creators needing fast, high-quality character animation without the steep learning curve of traditional 3D suites.
iClone 8 by Reallusion is positioned as a comprehensive character animation tool designed to bridge the gap between ease of use and professional results. The software features a robust motion director system, allowing for real-time character control and fluid transitions. It integrates seamlessly with industry standards like Unreal Engine, Unity, and Blender via specialized plugins. Key updates include enhanced facial expression tools and improved physics simulations for more realistic movement. For creative hobbyists and indie developers, it offers a faster alternative to manual keyframing in complex 3D software.
Creative Bloq·tooling·05/03/2026, 12:00 PM· paulo.n.hatton@gmail.com (Paul Hatton)
Gemini 3.5 Flash In Arena! POWERFUL, Cheap, & Fast NEW AI Model! (Fully Tested)
A new, significantly more powerful Gemini Flash variant is being tested in the Arena, offering Pro-level coding and reasoning performance at a 'Flash' price point.
Google is quietly testing an upgraded Gemini Flash model in the LMSYS Chatbot Arena, likely as a precursor to a major Google I/O announcement. Early testers report a massive leap in reasoning and output quality, with performance reportedly rivaling the more expensive Gemini 3.1 Pro. The video showcases the model's proficiency in complex front-end coding tasks using React and GSAP, as well as 3D scene generation in Three.js, such as a functional 1970s TV simulator. While the exact version number (3.1 vs 3.5) remains unconfirmed, the update signals a significant shift in the price-to-performance ratio for Google's lightweight model tier.
AI Jason·news·05/03/2026, 06:44 AM·WorldofAI▶Watch here

Codex Replaced Claude for Me… Here’s Why
OpenAI's Codex is winning the 'super app' race by unifying coding and knowledge work into one tool, while Anthropic's ecosystem suffers from fragmentation.
The video explores the 2026 AI landscape where OpenAI’s Codex is challenging Anthropic’s dominance by offering a unified 'super app' experience. While Anthropic led early 2026 with rapid feature releases, its ecosystem became fragmented across separate tools like Claude Code and Co-work, creating friction for users. OpenAI pivoted by merging its efforts into Codex, which excels at both 'vibe coding' and general knowledge work through a single, intuitive GUI. The discussion highlights a major shift: a great coding model is now recognized as the best general-purpose model for all knowledge work. Additionally, the 'OpenClaw' craze has caused a global Mac Mini shortage, signaling a massive move toward running local AI agents.
Riley Brown·tooling·05/02/2026, 08:35 PM·Riley Brown▶Watch here
Sightings
Simon Willison demonstrates the power of Claude Code by building a complex blog feature and API integration entirely from his phone.
Simon Willison has introduced a new 'Sightings' feature to his blog, which automatically syndicates his wildlife photography from iNaturalist. The most impressive aspect is that the entire feature was developed on a mobile phone using Claude Code, an AI-powered command-line tool. The implementation includes a search function, date archives, and back-population of over a decade of historical data, including photos from Madagascar. Willison shared the full Pull Request and the specific prompts used, providing a transparent look at modern AI-assisted programming workflows. This serves as a practical benchmark for how agentic AI tools can handle multi-step coding tasks in constrained environments.
Simon Willison's Weblog·tooling·05/02/2026, 05:26 PM
Claude Sonnet 4.8 Leaked, Claude Cardinal, New Gemini 3.5 Model In Areana, & More! AI NEWS
Anthropic teases new models for May 6, Google tests a powerful Gemini Flash upgrade, and xAI launches Grok 4.3 with a unified creative workspace.
Anthropic is reportedly testing a new model codenamed "Jupiter," likely Sonnet 4.8 or Haiku 4.7, ahead of their May 6 developer event. A new version of Gemini 3 Flash has appeared in LM Arena, showing significantly improved reasoning and coding capabilities, nearly matching Pro models. OpenAI added "Pets" to Codex, providing a visual overlay for monitoring agent activity, alongside a new migration tool for easier workflow transitions. The ARC AGI 3 benchmark released humbling results, with top models like GPT-5.5 and Opus 4.7 scoring below 1%, emphasizing the gap in generalized intelligence. xAI launched Grok 4.3 via API and introduced "Imagine Agent Mode," a unified workspace for text, image, and video generation.
AI Jason·news·05/02/2026, 07:22 AM·WorldofAI▶Watch here

[AINews] AI Engineer World's Fair — Autoresearch, Memory, World Models, Tokenmaxxing, Agentic Commerce, and Vertical AI Call for Speakers
The AI Engineer World's Fair 2026 is seeking speakers for cutting-edge tracks like Autoresearch and Agentic Commerce, signaling the next big trends in the field.
The AI Engineer World's Fair 2026 has announced its Wave 2 Call for Speakers, expanding to Moscone West in San Francisco to accommodate over a million monthly unique viewers. The event introduces several forward-looking tracks, including Autoresearch (recursive self-improvement), Agentic Commerce (autonomous financial transactions between agents), and World Models for spatial intelligence. There is a specific push for Vertical AI applications in Law and Healthcare, alongside a Startup Battlefield for pre-series A founders. Additionally, the organizers are offering free expo space for robotics demonstrations. A brief update also notes the release of Grok 4.3, which shows a modest 4-point improvement on the Artificial Analysis Intelligence Index.
Latent Space·news·05/02/2026, 07:21 AM
AI just killed Crypto...
AI-driven quantum error correction is fast-tracking the 'Quantum Apocalypse' to 2029, forcing major tech shifts in encryption.
Scott Aaronson, a leading computer scientist and former OpenAI researcher, warns that fault-tolerant quantum computers capable of breaking current encryption (RSA) could arrive by 2029. This acceleration is largely driven by AI-powered breakthroughs in quantum error correction, specifically Google DeepMind’s AlphaQubit. The threat targets public-key cryptography, affecting everything from government secrets and bank transactions to blockchain assets and web certificates. Google has already set a 2029 deadline to migrate its internal infrastructure to post-quantum cryptography (PQC) to counter 'store now, decrypt later' attacks. This shift signals a transition from theoretical risk to an active cybersecurity race.
Wes Roth·news·05/02/2026, 04:50 AM·Wes Roth▶Watch here
iNaturalist Sightings
Build functional web tools and data pipelines entirely on your phone using AI agents like Claude Code.
Simon Willison demonstrates a complete development workflow performed entirely on a mobile phone while camping. He used Claude Code to build 'iNaturalist Sightings,' a tool that aggregates and groups nature observations from multiple accounts based on time and proximity. The project involves a Python CLI for data processing, a Git scraping setup on GitHub to host the data, and a final web frontend generated via a single prompt. This serves as a practical example of how AI agents enable complex multi-step development tasks in non-traditional environments. It highlights the shift toward 'just-in-time' personal software creation without a desktop environment.
Simon Willison's Weblog·tooling·05/01/2026, 07:35 PM
Sakana AI’s God Simulator Is Brilliant
Experiment with Sakana AI's interactive simulation to see how changing environmental rules can force AI species to either destroy each other or coexist in complex patterns.
Sakana AI has released an interactive "God Simulator" based on Neural Cellular Automata (NCA), where different AI species compete for territory in a 2D grid. The simulation demonstrates how environmental variables—like the survival threshold—dictate whether an ecosystem thrives, collapses into a monopoly, or fosters collaboration. By adjusting these parameters, users can observe emergent behaviors such as crystallization, where species form stable borders or intricate checkerboard patterns. The project highlights the power of local rules in creating complex global behaviors, moving beyond traditional LLMs into evolutionary AI. It serves as both a scientific tool for studying multi-agent systems and a creative playground for observing digital life.
Two Minute Papers·creative_work·05/01/2026, 04:43 PM·Two Minute Papers▶Watch here

Back Against the Needle
A high-quality cinematic AI video showcase demonstrating the current state of temporal consistency and stylistic control in Runway.
This Reddit post showcases a creative video project titled 'Back Against the Needle,' generated using Runway's AI video tools. The work highlights significant improvements in temporal consistency, showing fewer artifacts than typical early AI video generations. It features a distinct cinematic aesthetic, blending realistic textures with surreal visual storytelling. The creator, /u/mindoverimages, demonstrates how specialized prompting and potentially image-to-video workflows can produce cohesive narrative fragments. This serves as a benchmark for hobbyists looking to see the current ceiling of consumer-grade AI cinematography.
r/runwayml·creative_work·05/01/2026, 02:09 PM·/u/mindoverimages[AINews] Agents for Everything Else: Codex for Knowledge Work, Claude for Creative Work
OpenAI's Codex and Anthropic's Claude are expanding beyond code into general knowledge work and creative apps like Adobe and Blender.
OpenAI has repositioned Codex as a "SuperApp" for general knowledge work, moving beyond its coding origins. The update includes a 42% faster Computer Use Agent (CUA), a dynamic UI that adapts to tasks, and deep integrations with Microsoft, Google, and Salesforce suites. Meanwhile, Anthropic has launched Claude Security for code reviews and significantly expanded Claude's reach into creative software. New integrations allow Claude to interact with tools like Blender, Adobe Creative Cloud, Ableton, and Canva. This shift marks a transition where AI agents are no longer just for developers but are becoming general-purpose assistants for any computer-based task.
Latent Space·tooling·05/01/2026, 04:53 AM
US wants Claude all to itself... because it's "TOO DANGEROUS"
The US government is treating frontier models like Claude Mythos and GPT 5.5 as national security assets, restricting access due to their autonomous cyber-attack capabilities.
The White House has reportedly intervened to block Anthropic from expanding access to its Claude Mythos model, citing national security risks and compute priority. This follows findings from the UK AI Security Institute (AISI) showing Mythos and OpenAI’s GPT 5.5 can complete complex, multi-step cyber attacks end-to-end. In one test, a task taking a human expert 20 hours was completed in 10 minutes for less than $2 in API costs. This marks a shift from AI as a service to AI as controlled national infrastructure, similar to weapons-grade materials. While experts argue these vulnerabilities were already findable by humans, the concern is the democratization of these skills to non-technical actors globally.
Wes Roth·news·05/01/2026, 04:12 AM·Wes Roth▶Watch here

Runway bringing ideas to life!
A high-quality example of achieving consistent claymation and stop-motion styles in Runway, proving AI can mimic complex analog animation textures.
This creative showcase demonstrates the use of Runway to achieve a consistent stop-motion and claymation aesthetic. The creator, Jesse's Devlog, highlights the difficulty of prompt engineering to maintain visual consistency and tactile textures across different shots. The resulting video mimics the jittery, handmade feel of traditional clay animation, which is notoriously difficult to replicate in AI video without significant flickering. While specific technical settings weren't disclosed, the project serves as a high-quality example of stylized video generation. It underscores the potential for AI to replace labor-intensive analog techniques for hobbyists and small studios.
r/runwayml·creative_work·05/01/2026, 02:23 AM·/u/JessesDevlog

Relevance auto-scored by LLM (0–10). List shows top 30 from the last 7 days.