AI pulse last 7 days
Daily AI pulse from YouTube, blogs, Reddit, HN. Ruthlessly filtered.
Sources (41)▶
- criticalAndrej Karpathy
Były dyrektor AI w Tesli, OpenAI cofounder. Każde video to gold.
- criticalAnthropic
Oficjalny kanał Anthropic. Każdy release Claude'a.
- criticalComfyUI Blog
Release log dla integracji ComfyUI — Luma Uni-1, GPT Image 2, ACE-Step music gen, Seedance. Pokrywa video+image+music+workflow.
- criticalOpenAI Blog
Oficjalny blog OpenAI. Wszystkie release.
- criticalSimon Willison's Weblog
Najlepszy 'thinker' AI. Codzienne posty, deep insights, niska hype rate.
- highAI Explained
Głęboka analiza papers i benchmarków, niska hype rate.
- highAI Jason
Praktyczne tutoriale Claude Code, MCP, workflow vibe codingu.
- highBen's Bites
Daily AI digest, creator-friendly tone. Codex, model releases, agentic AI.
- highCole Medin
Vibe coding + agentic workflows + Claude Code MCP integrations.
- highFal AI Blog
Fal hostuje większość nowych AI image/video modeli — ich blog to wczesne sygnały premier.
- highHN: 3D & Gaussian Splatting
HN signal dla 3D generative — Gaussian Splatting, NeRF, image-to-3D. Próg 20 bo niszowa kategoria (top historic 182pts).
- highHN: AI agents / MCP
HN posty o agentach, MCP, vibe codingu z min 100 pkt.
- highHN: Claude / Anthropic
HN posty z 'Claude' lub 'Anthropic' z min 100 pkt.
- highHugging Face Blog
Releases dla image, video, audio, 3D modeli. Część tech-heavy — Gemini relevance odfiltruje noise. Downgraded z critical: za duży volume na 'must-read' status.
- highIndyDevDan
Claude Code power user, prompty, hooki.
- highInterconnects (Nathan Lambert)
AI policy + research analysis. Niska hype rate, opinionated.
- highLatent Space
Podcast + blog Swyx — wywiady z founderami i deep dives engineeringowe.
- highMatt Wolfe
Comprehensive AI tools weekly digest. ~700K subs.
- highMatthew Berman
AI news, model release reviews, agent demos. Wysoki output.
- highr/aivideo
Community AI video — Sora, Veo, Runway, Kling, LTX. Co naprawdę zaskakuje twórców.
- highr/ClaudeAI
Społeczność Claude'a — power users, tipy, problemy.
- highr/LocalLLaMA
Open-source LLMs, lokalne uruchamianie, benchmarks bez hype.
- highr/StableDiffusion
Największa community open-source image gen (700k+ users). Premiery modeli, LoRA, ComfyUI workflows.
- highRiley Brown
Vibe coding, AI builder workflows, Cursor + Claude tutorials.
- highThe Decoder
Niemiecki AI news outlet po angielsku, dobre breaking news.
- highTheo - t3.gg
TypeScript + AI dev workflows. Hot takes, narrative-driven.
- highYannic Kilcher
Paper reviews i deep dives w research AI.
- lowAI Weirdness
Janelle Shane — playful AI experiments, image gen quirks. Niski volume, unikalna perspektywa.
- mediumbycloud
AI papers digestible — między 2MP a Yannic Kilcher.
- mediumCreative Bloq
Design industry — gdzie AI ingeruje w klasyczne dyscypliny graficzne.
- mediumFireship
100-sec format, often AI/LLM + tech news.
- mediumfxguide
VFX i film industry — coraz więcej AI w pipeline. Profesjonalna perspektywa.
- mediumGreg Isenberg
Solo founder vibe — buduje produkty z AI, podcasty z indie hackers.
- mediumr/ChatGPTCoding
Vibe coding tipy, IDE setupy, prompty. Mix wszystkich modeli.
- mediumr/comfyui
ComfyUI workflows — custom nodes, JSON workflows, optymalizacje.
- mediumr/midjourney
Midjourney community — premiery v7+, style references, prompt patterns.
- mediumr/runwayml
Runway-specific community — premiery features, prompt patterns, comparisons z konkurencją.
- mediumr/SunoAI
Suno music gen community — nowe wersje modelu, lyric prompting techniques. Audio AI ma slaby RSS ecosystem.
- mediumTina Huang
AI workflows for data science, practical applications.
- mediumTwo Minute Papers
Krótkie streszczenia papers AI, świetne dla szybkiego scan'a.
- mediumWes Roth
AI news z bardziej clickbaitowym tonem — filtr Gemini odsiewa hype.

DeepSeek nears $45bn valuation as China’s ‘Big Fund’ leads investment talks
DeepSeek is securing $45B in funding, ensuring they remain a dominant force in the open-weights LLM space for the foreseeable future.
DeepSeek, the developer of the highly efficient V3 and R1 models, is reportedly in talks for its first major investment round that could value the company at $45 billion. The funding is expected to be led by China’s National Integrated Circuit Industry Investment Fund, known as the 'Big Fund.' This move marks a significant shift as DeepSeek, previously funded by high-frequency trading firm High-Flyer Quant, seeks massive capital to scale its compute resources. The valuation would place DeepSeek among the world's most valuable AI startups, rivaling US-based giants like Anthropic. For the local LLM community, this suggests a long-term commitment to developing state-of-the-art models that often challenge proprietary alternatives.
r/LocalLLaMA·news·05/07/2026, 10:21 AM·/u/Nunki08
ParoQuant: Pairwise Rotation Quantization for Efficient Reasoning LLM Inference
ParoQuant is a new quantization method that preserves the reasoning and logic capabilities of LLMs at low bitrates better than standard techniques.
ParoQuant introduces Pairwise Rotation Quantization, a novel technique designed to minimize information loss during the compression of reasoning-heavy LLMs. Unlike standard quantization methods that often degrade complex logic chains, ParoQuant uses a pairwise approach to handle outlier weights more effectively. The release includes a dedicated GitHub repository and pre-quantized models on HuggingFace for immediate testing. This is particularly significant for users running large reasoning models on consumer hardware where VRAM is limited. Initial benchmarks suggest superior performance in maintaining Chain of Thought (CoT) coherence compared to traditional 4-bit methods.
r/LocalLLaMA·tooling·05/07/2026, 02:07 AM·/u/Total-Resort-3120Acestep 1.5 XL Base Workflow?
Get the ComfyUI workflows for ACE-Step 1.5XL text-to-music generation, though be aware of potential vocal quality issues in the latest base version.
A user on r/comfyui has shared direct links to workflows for ACE-Step 1.5XL Base and ACE-Step 1.5 (4b LLM), which are models designed for text-to-music generation. While these workflows allow for integrated audio creation within ComfyUI, the author notes a significant drop in vocal quality in the 1.5XL version compared to the older 4b LLM variant. The issue persists across various prompts and default settings, resulting in audio that sounds low-bitrate or 'off'. This post serves as both a resource for those wanting to experiment with AI music and a warning about current technical limitations. It highlights the ongoing challenges in maintaining audio fidelity when scaling these specific generative models.
r/comfyui·tooling·05/06/2026, 08:48 PM·/u/uhf789UniReasoner: Using LLMs as "Universal Reasoners" to Fix Prompt Alignment
UniReasoner improves image accuracy by letting an LLM critique its own visual draft before the final diffusion step.
UniReasoner is a new framework designed to solve the "understanding-generation gap" in text-to-image models. It leverages the fact that multimodal LLMs are better at verifying images than generating them from scratch. The system uses a three-stage pipeline where an LLM first creates a coarse visual draft using discrete tokens. It then performs a "grounded evaluation" to identify errors like incorrect object counts or missing elements. Finally, a diffusion model such as SANA uses the original prompt, the draft, and the critique to produce a highly accurate final image. This method moves beyond simple prompt rewriting by using SigLIP-based discretization for spatial reasoning.
r/StableDiffusion·model_release·05/06/2026, 08:39 PM·/u/Formal_Drop526
The GB10 Solution Atlas is now open source, the inference engine made for the community with breakneck inference speeds (Qwen3.6-35B-FP8 100+ tok/s)
Atlas is a high-performance, Rust-based open-source inference engine that delivers 3x faster speeds than vLLM on Blackwell hardware by removing Python overhead.
Atlas is a newly open-sourced inference engine written in pure Rust and CUDA, designed to bypass the performance bottlenecks of the standard Python/PyTorch stack. Optimized for NVIDIA Blackwell (GB10) architecture, it achieves over 100 tokens per second on Qwen3.5-35B models using NVFP4 precision and Multi-Token Prediction (MTP). The engine features a lightweight 2.5GB Docker image with sub-2-minute cold starts and provides native support for OpenAI and Anthropic API formats. By rewriting the stack from HTTP handlers to kernel dispatch, the developers claim a 3x throughput increase over vLLM. Future updates aim to bring these optimizations to AMD Strix Halo and RTX 6000 Blackwell hardware.
r/LocalLLaMA·tooling·05/06/2026, 08:36 PM·/u/Live-Possession-6726
ZAYA1-8B: Frontier intelligence density, trained on AMD
ZAYA1-8B is a new 8B model that claims to outperform Llama 3.1 8B, proving that high-density intelligence can be achieved using AMD-based training stacks.
Zyphra has released ZAYA1-8B, a new language model designed to maximize intelligence density within the 8-billion parameter class. The model reportedly outperforms Llama 3.1 8B and Gemma 2 9B across several key benchmarks, including MMLU and GSM8K. Notably, ZAYA1-8B was trained entirely on AMD Instinct MI300X accelerators, showcasing a viable alternative to the NVIDIA-dominated training ecosystem. This release targets developers looking for high-performance models that can run efficiently on consumer hardware or edge devices. The architecture focuses on better data efficiency and architectural refinements to squeeze more reasoning capability out of fewer parameters.
r/LocalLLaMA·model_release·05/06/2026, 07:43 PM·/u/carbocationvLLM V0 to V1: Correctness Before Corrections in RL
vLLM V1 is a major upgrade optimized for RL and reasoning models, focusing on output correctness and significantly better inference performance.
vLLM is transitioning from V0 to V1, marking a major architectural overhaul focused on Reinforcement Learning (RL) workflows. The update emphasizes a 'Correctness Before Corrections' philosophy, addressing the critical need for high-fidelity outputs in complex reasoning tasks. This shift is particularly relevant for serving modern models like DeepSeek-R1 that rely on long-chain reasoning and RL-based optimization. The new version aims to significantly reduce overhead and improve throughput while maintaining strict output validation. It represents a move towards more robust, production-ready inference for the next generation of agentic and reasoning LLMs.
Hugging Face Blog·tooling·05/06/2026, 07:06 PMPeak hours limit reduction gone thanks to partnership with SpaceX
Claude users can now enjoy unlimited access even during peak hours thanks to a new infrastructure partnership with SpaceX.
Anthropic has announced a strategic partnership with SpaceX to eliminate usage limits during peak hours for Claude users. This collaboration likely leverages SpaceX's Starlink satellite constellation to enhance global connectivity and infrastructure resilience. For power users, this means consistent access to high-end models without the common 'capacity reached' interruptions during busy workdays. The move represents a significant shift in how AI providers scale their backend to meet massive concurrent demand. By integrating with satellite-based infrastructure, Anthropic aims to provide a more reliable service compared to competitors relying solely on traditional terrestrial data centers.
r/ClaudeAI·news·05/06/2026, 04:25 PM·/u/neilmcd
DeepSeek V4 AI Beats Billion Dollar Systems…For Free
DeepSeek V4 is a powerful new open-source AI model that reportedly outperforms expensive commercial systems, offering advanced capabilities for free.
DeepSeek has released its new AI model, DeepSeek V4, which is being highlighted for its impressive performance. The model reportedly surpasses the capabilities of much larger and more expensive "billion-dollar" proprietary systems, yet it is available for free. This release signifies a notable advancement in the open-source LLM landscape, potentially democratizing access to high-tier AI capabilities. For creative non-developers and hobbyists, this means access to a powerful tool without significant financial investment, pushing the boundaries of what's achievable with freely available AI.
Two Minute Papers·model_release·05/06/2026, 04:07 PM·Two Minute Papers▶Watch here

Google speeds up Gemma 4 threefold with multi-token prediction
You can now generate text with Google's Gemma 4 models up to three times faster thanks to a new multi-token prediction technique.
Google has introduced multi-token prediction drafters for its Gemma 4 open model family, significantly accelerating text generation. This new feature allows Gemma 4 models to generate text up to three times faster than before. The technique involves a smaller auxiliary model that proposes several tokens simultaneously, which the main Gemma model then validates in a single pass. This enhancement provides a substantial performance boost for users working with Gemma 4, making it more efficient for various creative and development tasks.
The Decoder·model_release·05/06/2026, 04:05 PM·Matthias BastianLive blog: Code w/ Claude 2026
Get real-time technical insights and roadmap updates from Anthropic's 2026 developer event via Simon Willison's live notes.
Simon Willison provides live-blog coverage of Anthropic's 'Code w/ Claude' event in May 2026. The keynote sessions focus on the evolution of Claude Code and the broader ecosystem of AI-driven development tools. This report captures real-time announcements regarding model updates, new developer APIs, and Anthropic's strategy for autonomous coding agents. It serves as a crucial primary source for understanding how the industry leader in coding LLMs is positioning itself for the year. The blog format offers granular insights and technical details that often precede official press releases.
Simon Willison's Weblog·news·05/06/2026, 03:58 PM
Deepseek nears $45 billion valuation as China's state chip fund leads round
Deepseek is securing $45B in state-backed funding, solidifying its position as the primary global rival to OpenAI and Anthropic.
Deepseek is reportedly finalizing a funding round that would value the Chinese AI lab at approximately $45 billion. The round is led by China's state-backed semiconductor fund, indicating strong government support for domestic AI development. This massive valuation leap follows the global success of their DeepSeek-V3 and R1 models, which demonstrated high efficiency at significantly lower costs than Western counterparts. The investment highlights the intensifying AI arms race between China and the US, specifically focusing on compute and model training capabilities. This capital injection will likely fuel further research into large-scale reasoning models and infrastructure to bypass hardware restrictions.
The Decoder·news·05/06/2026, 01:22 PM·Maximilian Schreiner
An Open Benchmark for Testing RAG on Realistic Company-Internal Data
EnterpriseRAG-Bench provides 500k synthetic documents (Slack, Jira, etc.) to test if your RAG system can actually handle realistic, messy corporate data.
EnterpriseRAG-Bench is a new open-source benchmark designed to test RAG systems on realistic, messy enterprise data. It features a synthetic corpus of 500,000 documents simulating a fictional company, including Slack threads, emails, Jira tickets, and meeting transcripts. Unlike benchmarks based on clean Wikipedia data, this set includes intentional noise like conflicting information, near-duplicates, and misfiled documents. Initial findings released with the benchmark show that traditional BM25 keyword search often outperforms vector search on this type of data. The project includes 500 evaluation questions and a harness to measure retrieval accuracy and answer quality across 10 distinct failure-mode categories.
r/LocalLLaMA·tooling·05/06/2026, 12:58 PM·/u/Weves11
Adapting to Opus 4.7
Get a structured framework for prompt evaluation and authoring to fix performance issues and behavioral shifts in the latest Claude Opus model.
A user on r/ClaudeAI has shared a set of prompt evaluation and authoring criteria designed to help users adapt to the behavioral shifts in the fictional Opus 4.7 model. While the full proprietary implementation remains private, the shared framework focuses on reactive analysis and proactive writing strategies. The author suggests using these criteria to build a multi-lens adversarial review skill within Claude to self-correct and refine outputs. This release aims to mitigate the common frustrations users are experiencing with the model's new reasoning patterns. It provides a structured starting point for hobbyists to rebuild their workflows around more rigorous prompt standards.
r/ClaudeAI·tutorial·05/06/2026, 09:41 AM·/u/subourbonite01
Prompt Injection experience - my first time ever
Claude successfully identified and ignored an "indirect prompt injection" attempt hidden in a website's HTML, demonstrating how LLMs distinguish between instructions and data.
A user on Reddit shared a real-world example of an indirect prompt injection attempt encountered by Claude during a web search. A website embedded fake <RootSystemPrompt> tags within pricing data to trick the AI into vouching for the site's credibility. Claude correctly identified the attempt, explaining that instructions from scraped HTML are treated as untrusted data rather than authoritative commands. The AI noted that such SEO-driven manipulation is becoming increasingly common. This case highlights the importance of robust system prompts and the model's ability to cross-reference multiple sources. It serves as a practical lesson for developers building agents that interact with external web content.
r/ClaudeAI·news·05/06/2026, 08:39 AM·/u/netmilk
US and tech firms strike deal to review AI models for national security before public release | Technology
The US government and major AI labs have agreed on a pre-release review process for new models to assess national security risks before they go public.
The US Department of Commerce has reached a landmark agreement with leading AI companies, including Google, Microsoft, and xAI, to implement a pre-release review system for advanced AI models. This voluntary framework allows government agencies to evaluate potential national security risks, such as cyber-warfare capabilities or biological threat assistance, before public deployment. The move signals a shift towards tighter oversight of frontier LLM development as concerns over existential risks and global competition intensify. While the agreement is currently voluntary, it sets a precedent for how future high-capability models might be regulated. For the open-source community, this raises questions about whether similar scrutiny will eventually extend to weights shared on platforms like…
r/LocalLLaMA·news·05/05/2026, 09:46 PM·/u/Merchant_Lawrence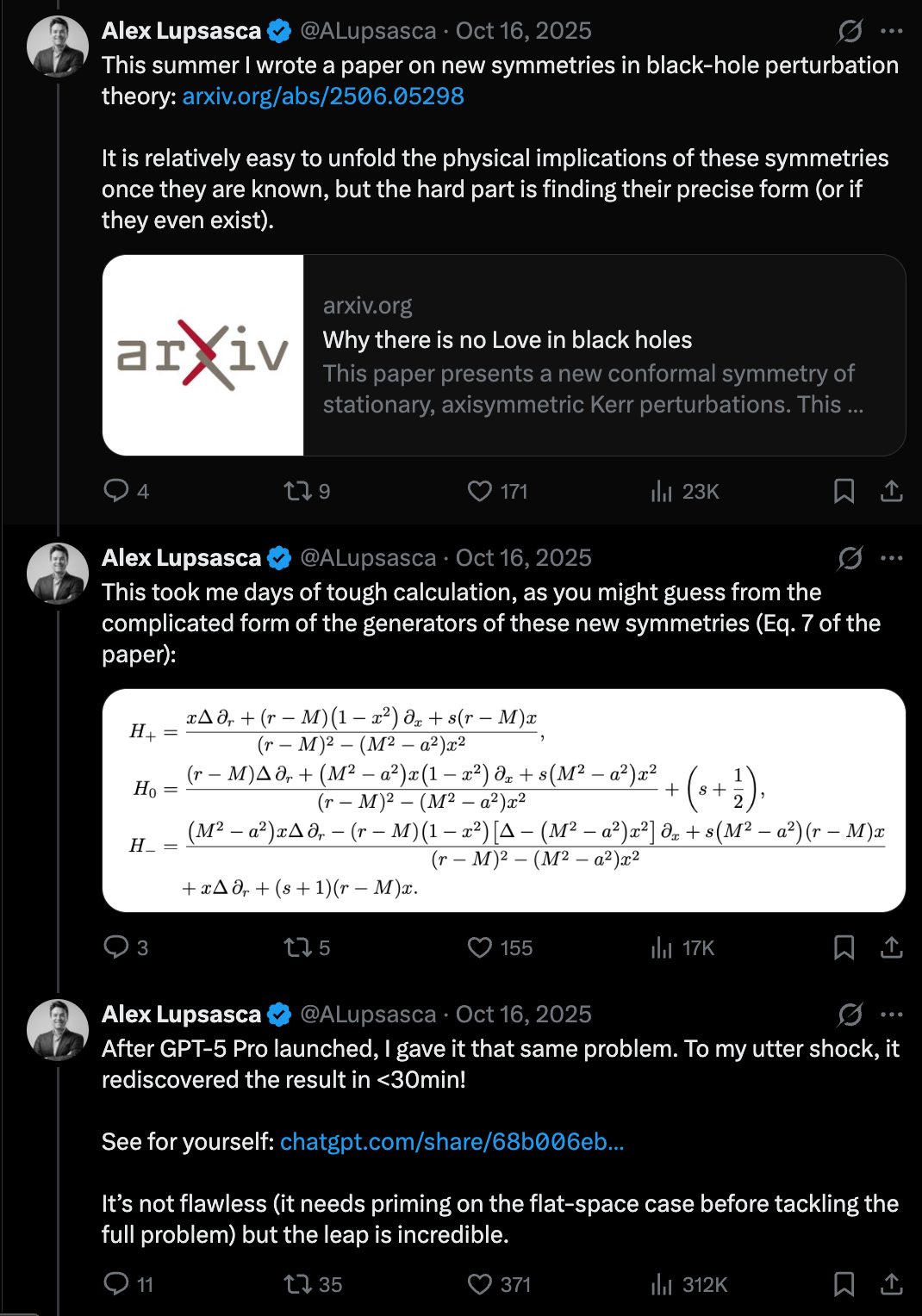
🔬Doing Vibe Physics — Alex Lupsasca, OpenAI
LLMs are hitting a "Move 37" moment in science, solving complex theoretical physics problems in minutes that previously took researchers months.
Alex Lupsasca, a renowned theoretical physicist and Breakthrough Prize winner, discusses his transition to OpenAI to lead scientific reasoning efforts. He highlights a paradigm shift where LLMs like GPT-5 are no longer just improving at mundane tasks like email, but are making breakthroughs at the "scientific frontier." Lupsasca shares how the model reproduced his complex research paper in 11 minutes and later helped derive a new result in theoretical physics regarding gluon tree amplitudes. This suggests that AI is becoming a legitimate partner in high-level mathematical and physical discovery, moving beyond simple pattern matching to genuine reasoning in complex domains.
Latent Space·news·05/05/2026, 08:34 PM
US government now has pre-release access to AI models from five major labs for national security testing
Five major AI labs now grant the US government early access to unreleased models for national security and safety stress-testing.
The US Department of Commerce has expanded its AI safety testing program to include five major labs: Google DeepMind, Microsoft, xAI, Anthropic, and OpenAI. These companies have signed agreements with the Center for AI Standards and Innovation to provide pre-release access to their frontier models. Testing occurs in classified environments and specifically involves versions of models with reduced safety guardrails to identify potential cybersecurity risks. This initiative aims to address national security concerns while maintaining a competitive edge in the global tech race, particularly against China. It represents a significant step toward formalized government oversight of foundational AI development.
The Decoder·news·05/05/2026, 06:28 PM·Matthias Bastian
ChatGPT update rolls out GPT-5.5 Instant with fewer hallucinations and more personalized answers
GPT-5.5 Instant is now the ChatGPT default, offering a 50% reduction in hallucinations and new 'memory sources' for better transparency.
OpenAI has replaced the default ChatGPT model with GPT-5.5 Instant, emphasizing reliability and transparency. Internal benchmarks report a 52.5% reduction in hallucinations for high-risk topics like medicine and law. A new feature called 'memory sources' has been introduced, allowing users to see exactly which stored context or past interactions influenced a specific response. While the model is rolling out to all users immediately, advanced personalization features involving Gmail and file integration are currently exclusive to Plus and Pro subscribers. This update marks a significant step in grounding LLM outputs in verifiable user data.
The Decoder·model_release·05/05/2026, 06:04 PM·Matthias Bastian10 things about Claude that took me way too long to figure out
A collection of ten actionable, non-obvious tips to improve Claude's output quality, reduce hallucinations, and streamline your debugging workflow.
This post outlines ten practical insights for optimizing interactions with Claude, moving beyond basic prompt engineering. Key advice includes instructing the model to admit ignorance to reduce hallucinations and prioritizing detailed system prompts over short commands. The author emphasizes using file uploads instead of text walls and providing specific evaluation criteria rather than vague quality requests. Notable workflow tips include using the mobile app for voice-to-text cleanup and pasting error messages before code during debugging. This collection focuses on realistic utility rather than the typical magic prompt hype found in AI communities.
r/ClaudeAI·tutorial·05/05/2026, 06:04 PM·VidekVipPro
Supercharging LLM inference on Google TPUs: Achieving 3X speedups with diffusion-style speculative decoding- Google Developers Blog
Google achieved a 3X speedup in LLM inference on TPUs by using a new 'diffusion-style' parallel token drafting technique.
Google researchers have introduced a novel approach to speculative decoding inspired by diffusion models, specifically optimized for TPU architectures. Traditional speculative decoding relies on a smaller draft model to predict tokens sequentially, but this new method generates multiple draft tokens in parallel, similar to how diffusion models refine images. This shift addresses the memory bandwidth bottlenecks common in LLM inference, resulting in up to 3X faster generation speeds. While the benchmarks focus on Google's proprietary hardware, the move toward non-autoregressive drafting represents a significant evolution in inference strategy. This technique could eventually influence local model optimization if adapted for consumer GPUs.
r/LocalLLaMA·news·05/05/2026, 03:50 PM·/u/eternvikingHeretic 1.3 released: Reproducible models, integrated benchmarking system, reduced peak VRAM usage, broader model support, and more
Heretic 1.3 brings byte-for-byte reproducibility and built-in benchmarking to LLM abliteration, making it easier to decensor models without sacrificing quality.
Heretic 1.3 introduces significant updates to the leading open-source tool for LLM abliteration (decensoring). The headline feature is byte-for-byte reproducibility, allowing users to share exact configurations and environment data to recreate identical models. It also integrates a benchmarking system based on lm-evaluation-harness, enabling users to run MMLU, EQ-Bench, or GSM8K directly to ensure model quality hasn't degraded. Technical optimizations have reduced peak VRAM usage, facilitating the processing of larger models on consumer hardware. Additionally, the update expands support to newer architectures, including Qwen 3.5 and Gemma 4.
r/LocalLLaMA·tooling·05/05/2026, 02:57 PM·/u/-p-e-w-
GPT-5.5 Instant: smarter, clearer, and more personalized
OpenAI updates ChatGPT with GPT-5.5 Instant, offering higher accuracy, fewer hallucinations, and better personalization for daily use.
OpenAI has officially released GPT-5.5 Instant, positioning it as the new standard model for ChatGPT. The update emphasizes improved reasoning capabilities and a notable decrease in hallucination rates for factual queries. A key addition includes more granular personalization controls, giving users better agency over the model's tone and memory. This release bridges the gap between major version leaps, focusing on speed and reliability for high-frequency tasks. It represents OpenAI's continued push to make LLM interactions feel more natural and context-aware.
OpenAI Blog·model_release·05/05/2026, 10:00 AM
GPT-5.5 Instant System Card
OpenAI releases technical documentation and safety benchmarks for GPT-5.5 Instant, highlighting improved reasoning and low-latency performance.
OpenAI has published the System Card for GPT-5.5 Instant, a new iteration in their model lineup focused on speed and efficiency. The document details the safety evaluations, red-teaming efforts, and performance benchmarks conducted before the public rollout. Key highlights include significant improvements in reasoning capabilities compared to previous small-scale models. The report also addresses potential risks such as bias and misuse, outlining the mitigation strategies implemented. This release marks a shift towards more transparent reporting on model behavior and safety guardrails for high-speed LLM applications.
OpenAI Blog·model_release·05/05/2026, 10:00 AM
DeepSeek V4 Pro matches GPT-5.2 on FoodTruck Bench, our agentic benchmark — 10 weeks later, ~17× cheaper
DeepSeek V4 Pro offers GPT-5.2 level agentic performance at 1/17th the cost, narrowing the US-China AI gap to just 10 weeks.
DeepSeek V4 Pro has achieved performance parity with GPT-5.2 on the FoodTruck Bench, a complex 30-day agentic simulation involving 34 tools and persistent memory. While GPT-5.2 was tested in February, DeepSeek matched its results only ten weeks later, signaling a rapid closing of the gap between US and Chinese frontier models. Crucially, DeepSeek is approximately 17 times cheaper for agentic workloads, with significantly lower input/output pricing. The model also demonstrated superior consistency compared to Grok 4.3, showing lower variance in outcomes and better resource management. Additionally, Xiaomi’s MiMo v2.5 Pro also entered the top 6, further establishing Chinese models as high-value competitors in the frontier tier.
r/LocalLLaMA·model_release·05/05/2026, 06:51 AM·Disastrous_Theme5906datasette-llm 0.1a7
You can now set global default parameters like temperature for specific LLMs within Datasette, ensuring consistency across data enrichment tasks.
Simon Willison released version 0.1a7 of the datasette-llm plugin, introducing a new configuration mechanism for model defaults. This update allows users to define specific settings, such as temperature or system prompts, that apply globally to a chosen model within the Datasette ecosystem. For example, you can now ensure all automated data enrichment tasks use a temperature of 0.5 by default without manual overrides. This is a significant step in making LLM-powered data workflows more predictable and easier to manage. The plugin serves as a bridge between structured SQLite databases and generative AI capabilities, streamlining how developers interact with models.
Simon Willison's Weblog·tooling·05/05/2026, 01:56 AMllm-echo 0.5a0
Test how your applications handle model 'thinking' blocks for free using the new simulated reasoning feature in the llm-echo plugin.
Simon Willison has released version 0.5a0 of llm-echo, a utility plugin for his LLM CLI tool designed for automated testing. The plugin provides a 'fake' model that echoes inputs instead of calling an actual API, saving costs during development. This update introduces a new '-o thinking 1' option, which simulates the reasoning blocks produced by modern models like DeepSeek-R1 or OpenAI's o1. By outputting a fake reasoning block to standard error, it allows developers to verify that their parsers and workflows correctly handle multi-stage model outputs without incurring any API fees.
Simon Willison's Weblog·tooling·05/05/2026, 01:31 AM
White House Considers Vetting A.I. Models Before They Are Released
The US government may soon require AI models to be vetted before release, potentially creating new hurdles for open-source and commercial developers alike.
The White House is reportedly exploring a new regulatory framework that would require AI developers to undergo a vetting process before publicly releasing their models. This shift toward proactive government oversight aims to address national security and safety concerns before technology reaches the public domain. The proposal could involve mandatory testing against specific safety benchmarks, particularly for high-compute foundation models. For the open-source community, this move raises significant concerns regarding potential barriers to entry and the slowing of innovation. While the specific criteria for vetting remain under discussion, the policy represents a major pivot in how the US government manages the risks associated with rapid AI advancement.
r/LocalLLaMA·news·05/04/2026, 07:18 PM·fallingdowndizzyvr
The distillation panic
Distillation is a standard AI training technique being unfairly rebranded as an 'attack,' which could lead to harmful regulations affecting open-source models.
Nathan Lambert argues against the emerging term 'distillation attacks,' recently popularized by Anthropic to describe Chinese labs extracting data from APIs. He emphasizes that distillation—training smaller models on the outputs of larger ones—is an industry-standard method used by almost everyone, including xAI and Nvidia. The real issue isn't the technique itself, but the illicit means (jailbreaking, API abuse) used to access hidden data like reasoning traces. Lambert warns that aggressive US policy targeting distillation could inadvertently ban or stifle the open-weight model ecosystem, which relies heavily on these methods. Ultimately, stigmatizing distillation might hurt Western innovation more than it slows down international competitors.
Interconnects (Nathan Lambert)·news·05/04/2026, 03:56 PM·Nathan Lambert
Gemini 3.5 Flash In Arena! POWERFUL, Cheap, & Fast NEW AI Model! (Fully Tested)
A new, significantly more powerful Gemini Flash variant is being tested in the Arena, offering Pro-level coding and reasoning performance at a 'Flash' price point.
Google is quietly testing an upgraded Gemini Flash model in the LMSYS Chatbot Arena, likely as a precursor to a major Google I/O announcement. Early testers report a massive leap in reasoning and output quality, with performance reportedly rivaling the more expensive Gemini 3.1 Pro. The video showcases the model's proficiency in complex front-end coding tasks using React and GSAP, as well as 3D scene generation in Three.js, such as a functional 1970s TV simulator. While the exact version number (3.1 vs 3.5) remains unconfirmed, the update signals a significant shift in the price-to-performance ratio for Google's lightweight model tier.
AI Jason·news·05/03/2026, 06:44 AM·WorldofAI▶Watch here

Claude Sonnet 4.8 Leaked, Claude Cardinal, New Gemini 3.5 Model In Areana, & More! AI NEWS
Anthropic teases new models for May 6, Google tests a powerful Gemini Flash upgrade, and xAI launches Grok 4.3 with a unified creative workspace.
Anthropic is reportedly testing a new model codenamed "Jupiter," likely Sonnet 4.8 or Haiku 4.7, ahead of their May 6 developer event. A new version of Gemini 3 Flash has appeared in LM Arena, showing significantly improved reasoning and coding capabilities, nearly matching Pro models. OpenAI added "Pets" to Codex, providing a visual overlay for monitoring agent activity, alongside a new migration tool for easier workflow transitions. The ARC AGI 3 benchmark released humbling results, with top models like GPT-5.5 and Opus 4.7 scoring below 1%, emphasizing the gap in generalized intelligence. xAI launched Grok 4.3 via API and introduced "Imagine Agent Mode," a unified workspace for text, image, and video generation.
AI Jason·news·05/02/2026, 07:22 AM·WorldofAI▶Watch here
Relevance auto-scored by LLM (0–10). List shows top 30 from the last 7 days.