USP
Daft uniquely combines native multimodal processing with built-in AI operations, offering a Python-native experience powered by Rust for blazing performance and seamless scaling to distributed clusters without JVM complexity.
Use cases
- 01Processing images, audio, video, and embeddings at scale
- 02Running LLM prompts and generating embeddings
- 03Optimizing User-Defined Functions (UDFs) for GPU inference or async I/O
- 04Scaling data workflows to distributed Ray or Kubernetes clusters
- 05ETL for AI and machine learning pipelines
Detected files (4)
.claude/skills/daft-udf-tuning/SKILL.mdskillShow content (1410 bytes)
--- name: "daft-udf-tuning" description: "Optimize Daft UDF performance. Invoke when user needs GPU inference, encounters slow UDFs, or asks about async/batch processing." --- # Daft UDF Tuning Optimize User-Defined Functions for performance. ## UDF Types | Type | Decorator | Use Case | |---|---|---| | **Stateless** | `@daft.func` | Simple transforms. Use `async` for I/O-bound tasks. | | **Stateful** | `@daft.cls` | Expensive init (e.g., loading models). Supports `gpus=N`. | | **Batch** | `@daft.func.batch` | Vectorized CPU/GPU ops (NumPy/PyTorch). Faster. | ## Quick Recipes ### 1. Async I/O (Web APIs) ```python @daft.func async def fetch(url: str): async with aiohttp.ClientSession() as s: return await s.get(url).text() ``` ### 2. GPU Batch Inference (PyTorch/Models) ```python @daft.cls(gpus=1) class Classifier: def __init__(self): self.model = load_model().cuda() # Run once per worker @daft.method.batch(batch_size=32) def predict(self, images): return self.model(images.to_pylist()) # Run with concurrency df.with_column("preds", Classifier(max_concurrency=4).predict(df["img"])) ``` ## Tuning Keys - **`max_concurrency`**: Total parallel UDF instances. - **`gpus=N`**: GPU request per instance. - **`batch_size`**: Rows per call. Too small = overhead; too big = OOM. - **`into_batches(N)`**: Pre-slice partitions if memory is tight..claude/skills/daft-distributed-scaling/SKILL.mdskillShow content (2227 bytes)
--- name: "daft-distributed-scaling" description: "Scale Daft workflows to distributed Ray clusters. Invoke when optimizing performance or handling large data." --- # Daft Distributed Scaling Scale single-node workflows to distributed execution. ## Core Strategies | Strategy | API | Use Case | Pros/Cons | |---|---|---|---| | **Shuffle** | `repartition(N)` | Light data (e.g. file paths), Joins | **Global balance**. High memory usage (materializes data). | | **Streaming** | `into_batches(N)` | Heavy data (images, tensors) | **Low memory** (streaming). High scheduling overhead if batches too small. | ## Quick Recipes ### 1. Light Data: Repartitioning Best for distributing file paths before heavy reads. ```python # Create enough partitions to saturate workers df = daft.read_parquet("s3://metadata").repartition(100) df = df.with_column("data", read_heavy_data(df["path"])) ``` ### 2. Heavy Data: Streaming Batches Best for processing large partitions without OOM. ```python # Stream 1GB partition in 64-row chunks to control memory df = df.read_parquet("heavy_data").into_batches(64) df = df.with_column("embed", model.predict(df["img"])) ``` ## Advanced Tuning Target: Keep all actors busy without OOM or scheduling bottlenecks. ### Formula 1: Repartitioning (Light Data / Paths) Calculate the **Max Partition Count** to ensure each task has enough data to feed local actors. 1. **Min Rows Per Partition** = `Batch Size * (Total Concurrency / Nodes)` 2. **Max Partitions** = `Total Rows / Min Rows Per Partition` **Example**: - 1M rows, 4 nodes, 16 total concurrency, Batch Size 64. - **Min Rows**: `64 * (16/4) = 256`. - **Max Partitions**: `1,000,000 / 256 ≈ 3906`. - *Recommendation*: Use ~1000 partitions to run multiple batches per task. ```python df = df.repartition(1000) # Balanced fan-out ``` ### Formula 2: Streaming (Heavy Data / Images) Avoid creating tiny partitions. Use `into_batches` to stream data within larger partitions. **Strategy**: Keep partitions large (e.g. 1GB+), use `into_batches(Batch Size)` to control memory. ```python # Stream batches to control memory usage per actor df = df.into_batches(64).with_column("preds", model(max_concurrency=16).predict(df["img"])) ```.claude/skills/daft-docs-navigation/SKILL.mdskillShow content (1130 bytes)
--- name: "daft-docs-navigation" description: "Navigate Daft documentation. Invoke when user asks general questions about APIs, concepts, or examples, or wants to search the docs." --- # Daft Docs Navigation Navigate Daft's documentation for APIs, concepts, and examples. ## Documentation Structure 1. **Live Site**: [`https://docs.daft.ai`](https://docs.daft.ai) (Primary source, searchable). 2. **Source Repo**: `docs/` directory in the repository. - If `docs/` is missing or empty, clone the repo: `git clone https://github.com/Eventual-Inc/Daft.git` ## Key Locations in `docs/` - **API Reference**: `api/` (e.g., `api/io.md` for reading/writing). - **Optimization**: `optimization/` (e.g., `optimization/partitioning.md`). - **Distributed**: `distributed/` (e.g., `distributed/ray.md`). - **UDFs**: `custom-code/` (e.g., `func.md`, `cls.md`). - **Connectors**: `connectors/` (e.g., S3, Lance). - **Table of Contents**: `docs/SUMMARY.md`. ## Usage **Search for API Usage:** ```bash grep_search(pattern='from_glob', path='docs/') ``` **Browse Topics:** ```bash read(file_path='docs/SUMMARY.md') ```.claude-plugin/marketplace.jsonmarketplaceShow content (327 bytes)
{ "name": "Eventual-Inc", "owner": { "name": "Eventual, Inc.", "email": "yksu@eventualcomputing.com" }, "plugins": [ { "name": "daft", "source": "./", "description": "Skills for working with Daft: UDF tuning, distributed scaling, and docs navigation", "version": "0.1.0" } ] }
README
|Banner|
|CI| |PyPI| |Latest Tag| |Coverage| |Slack|
Website <https://www.daft.ai>_ • Docs <https://docs.daft.ai>_ • Installation <https://docs.daft.ai/en/stable/install/>_ • Daft Quickstart <https://docs.daft.ai/en/stable/quickstart/>_ • Community and Support <https://github.com/Eventual-Inc/Daft/discussions>_
Daft: High-Performance Data Engine for AI and Multimodal Workloads
|TrendShift|
Daft <https://www.daft.ai>_ is a high-performance data engine for AI and multimodal workloads. Process images, audio, video, and structured data at any scale.
- Native multimodal processing: Process images, audio, video, and embeddings alongside structured data in a single framework
- Built-in AI operations: Run LLM prompts, generate embeddings, and classify data at scale using OpenAI, Transformers, or custom models
- Python-native, Rust-powered: Skip the JVM complexity with Python at its core and Rust under the hood for blazing performance
- Seamless scaling: Start local, scale to distributed clusters on
Ray <https://docs.daft.ai/en/stable/distributed/ray/>,Kubernetes <https://docs.daft.ai/en/stable/distributed/kubernetes/> - Universal connectivity: Access data anywhere (S3, GCS, Iceberg, Delta Lake, Hugging Face, Unity Catalog)
- Out-of-box reliability: Intelligent memory management and sensible defaults eliminate configuration headaches
Getting Started
Installation ^^^^^^^^^^^^
Install Daft with pip install daft. Requires Python 3.10 or higher.
For more advanced installations (e.g. installing from source or with extra dependencies such as Ray and AWS utilities), please see our Installation Guide <https://docs.daft.ai/en/stable/install/>_
Quickstart ^^^^^^^^^^
Get started in minutes with our Quickstart <https://docs.daft.ai/en/stable/quickstart/>_ - load a real-world e-commerce dataset, process product images, and run AI inference at scale.
More Resources ^^^^^^^^^^^^^^
Examples <https://docs.daft.ai/en/stable/examples/>_ - see Daft in action with use cases across text, images, audio, and moreUser Guide <https://docs.daft.ai/en/stable/>_ - take a deep-dive into each topic within DaftAPI Reference <https://docs.daft.ai/en/stable/api/>_ - API reference for public classes/functions of Daft
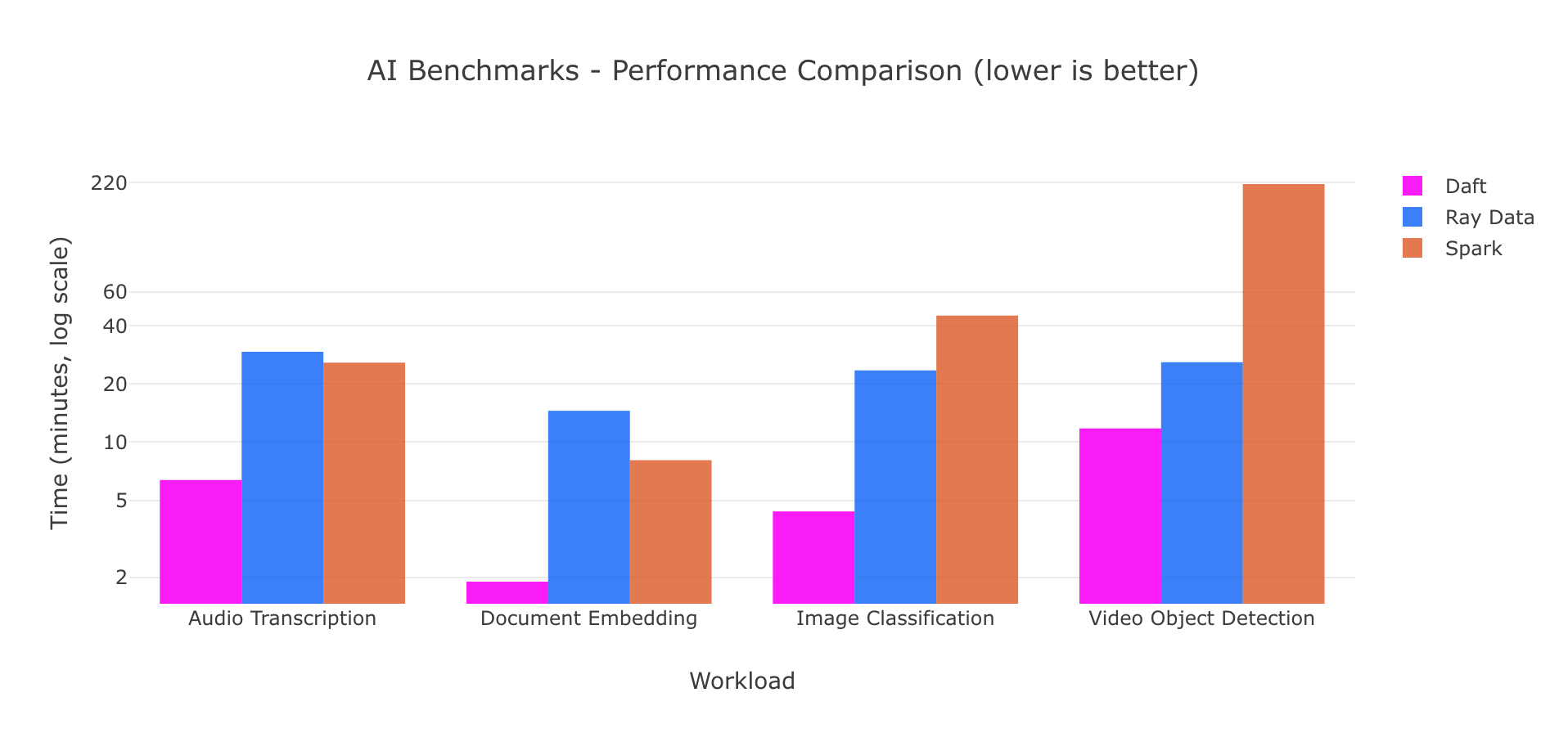
Benchmarks
|Benchmark Image|
To see the full benchmarks, detailed setup, and logs, check out our benchmarking page. <https://docs.daft.ai/en/stable/benchmarks>_
Contributing
We ❤️ developers! To start contributing to Daft, please read CONTRIBUTING.md <https://github.com/Eventual-Inc/Daft/blob/main/CONTRIBUTING.md>_. This document describes the development lifecycle and toolchain for working on Daft. It also details how to add new functionality to the core engine and expose it through a Python API.
Here's a list of good first issues <https://github.com/Eventual-Inc/Daft/issues?q=is%3Aopen+is%3Aissue+label%3A%22good+first+issue%22>_ to get yourself warmed up with Daft. Comment in the issue to pick it up, and feel free to ask any questions!
Telemetry
To help improve Daft, we collect non-identifiable data via Scarf (https://scarf.sh).
To disable this behavior, set the environment variable DO_NOT_TRACK=true.
The data that we collect is:
- Non-identifiable: No session IDs or user identifiers are collected
- Metadata-only: We do not collect any of our users’ proprietary code or data
- For development only: We do not buy or sell any user data
Please see our documentation <https://docs.daft.ai/en/stable/telemetry/>_ for more details.
.. image:: https://static.scarf.sh/a.png?x-pxid=31f8d5ba-7e09-4d75-8895-5252bbf06cf6
{kind=link}
Related Projects
+---------------------------------------------------+-----------------+---------------+-------------+-----------------+-----------------------------+-------------+
| Engine | Query Optimizer | Multimodal | Distributed | Arrow Backed | Vectorized Execution Engine | Out-of-core |
+===================================================+=================+===============+=============+=================+=============================+=============+
| Daft | Yes | Yes | Yes | Yes | Yes | Yes |
+---------------------------------------------------+-----------------+---------------+-------------+-----------------+-----------------------------+-------------+
| Pandas <https://github.com/pandas-dev/pandas>_ | No | Python object | No | optional >= 2.0 | Some(Numpy) | No |
+---------------------------------------------------+-----------------+---------------+-------------+-----------------+-----------------------------+-------------+
| Polars <https://github.com/pola-rs/polars>_ | Yes | Python object | No | Yes | Yes | Yes |
+---------------------------------------------------+-----------------+---------------+-------------+-----------------+-----------------------------+-------------+
| Modin <https://github.com/modin-project/modin>_ | Yes | Python object | Yes | No | Some(Pandas) | Yes |
+---------------------------------------------------+-----------------+---------------+-------------+-----------------+-----------------------------+-------------+
| Ray Data <https://github.com/ray-project/ray>_ | No | Yes | Yes | Yes | Some(PyArrow) | Yes |
+---------------------------------------------------+-----------------+---------------+-------------+-----------------+-----------------------------+-------------+
| PySpark <https://github.com/apache/spark>_ | Yes | No | Yes | Pandas UDF/IO | Pandas UDF | Yes |
+---------------------------------------------------+-----------------+---------------+-------------+-----------------+-----------------------------+-------------+
| Dask DF <https://github.com/dask/dask>_ | No | Python object | Yes | No | Some(Pandas) | Yes |
+---------------------------------------------------+-----------------+---------------+-------------+-----------------+-----------------------------+-------------+
License
Daft has an Apache 2.0 license - please see the LICENSE file.
.. |Quickstart Image| image:: https://github.com/Eventual-Inc/Daft/assets/17691182/dea2f515-9739-4f3e-ac58-cd96d51e44a8 :alt: Dataframe code to load a folder of images from AWS S3 and create thumbnails :height: 256
.. |Benchmark Image| image:: https://raw.githubusercontent.com/Eventual-Inc/Daft/refs/heads/main/assets/benchmark.png :alt: AI Benchmarks
{kind=link}
.. |Banner| image:: https://daft.ai/images/diagram.png :target: https://www.daft.ai :alt: Daft dataframes can load any data such as PDF documents, images, protobufs, csv, parquet and audio files into a table dataframe structure for easy querying
{kind=link}
.. |CI| image:: https://github.com/Eventual-Inc/Daft/actions/workflows/pr-test-suite.yml/badge.svg :target: https://github.com/Eventual-Inc/Daft/actions/workflows/pr-test-suite.yml?query=branch:main :alt: GitHub Actions tests
{kind=link}
.. |PyPI| image:: https://img.shields.io/pypi/v/daft.svg?label=pip&logo=PyPI&logoColor=white :target: https://pypi.org/project/daft :alt: PyPI
{kind=link}
.. |Latest Tag| image:: https://img.shields.io/github/v/tag/Eventual-Inc/Daft?label=latest&logo=GitHub :target: https://github.com/Eventual-Inc/Daft/tags :alt: latest tag
.. |Coverage| image:: https://codecov.io/gh/Eventual-Inc/Daft/branch/main/graph/badge.svg?token=J430QVFE89 :target: https://codecov.io/gh/Eventual-Inc/Daft :alt: Coverage
{kind=link}
.. |Slack| image:: https://img.shields.io/badge/slack-@distdata-purple.svg?logo=slack :target: https://join.slack.com/t/dist-data/shared_invite/zt-3rh9jr9iv-tmmTNOlQpfvhEy2NTMWS_w :alt: slack community
{kind=link}
.. |TrendShift| image:: https://trendshift.io/api/badge/repositories/8239 :target: https://trendshift.io/repositories/8239 :alt: Eventual-Inc/Daft | Trendshift :width: 250px :height: 55px