USP
This skill integrates 21 specialized sub-skills and leverages parallel subagent delegation for deep, multi-faceted audits, including AI search optimization and Google API integration. It offers a holistic approach to SEO directly within yo…
Use cases
- 01Performing full website SEO audits
- 02Analyzing single page performance
- 03Generating sitemaps and schema markup
- 04Optimizing content for E-E-A-T
- 05Strategic SEO planning for various business types
Detected files (8)
skills/seo-competitor-pages/SKILL.mdskillShow content (7710 bytes)
--- name: seo-competitor-pages description: > Generate SEO-optimized competitor comparison and alternatives pages. Covers "X vs Y" layouts, "alternatives to X" pages, feature matrices, schema markup, and conversion optimization. Use when user says "comparison page", "vs page", "alternatives page", "competitor comparison", "X vs Y", "versus", "compare competitors", or "alternative to". user-invokable: true argument-hint: "[url or generate] [competitor]" license: MIT metadata: author: AgriciDaniel version: "1.9.6" category: seo --- # Competitor Comparison & Alternatives Pages Create high-converting comparison and alternatives pages that target competitive intent keywords with accurate, structured content. ## Page Types ### 1. "X vs Y" Comparison Pages - Direct head-to-head comparison between two products/services - Balanced feature-by-feature analysis - Clear verdict or recommendation with justification - Target keyword: `[Product A] vs [Product B]` ### 2. "Alternatives to X" Pages - List of alternatives to a specific product/service - Each alternative with brief summary, pros/cons, best-for use case - Target keyword: `[Product] alternatives`, `best alternatives to [Product]` ### 3. "Best [Category] Tools" Roundup Pages - Curated list of top tools/services in a category - Ranking criteria clearly stated - Target keyword: `best [category] tools [year]`, `top [category] software` ### 4. Comparison Table Pages - Feature matrix with multiple products in columns - Sortable/filterable if interactive - Target keyword: `[category] comparison`, `[category] comparison chart` ## Comparison Table Generation ### Feature Matrix Layout ``` | Feature | Your Product | Competitor A | Competitor B | |------------------|:------------:|:------------:|:------------:| | Feature 1 | ✅ | ✅ | ❌ | | Feature 2 | ✅ | ⚠️ Partial | ✅ | | Feature 3 | ✅ | ❌ | ❌ | | Pricing (from) | $X/mo | $Y/mo | $Z/mo | | Free Tier | ✅ | ❌ | ✅ | ``` ### Data Accuracy Requirements - All feature claims must be verifiable from public sources - Pricing must be current (include "as of [date]" note) - Update frequency: review quarterly or when competitors ship major changes - Link to source for each competitor data point where possible ## Schema Markup Recommendations ### Product Schema with AggregateRating ```json { "@context": "https://schema.org", "@type": "Product", "name": "[Product Name]", "description": "[Product Description]", "brand": { "@type": "Brand", "name": "[Brand Name]" }, "aggregateRating": { "@type": "AggregateRating", "ratingValue": "[Rating]", "reviewCount": "[Count]", "bestRating": "5", "worstRating": "1" } } ``` ### SoftwareApplication (for software comparisons) ```json { "@context": "https://schema.org", "@type": "SoftwareApplication", "name": "[Software Name]", "applicationCategory": "[Category]", "operatingSystem": "[OS]", "offers": { "@type": "Offer", "price": "[Price]", "priceCurrency": "USD" } } ``` ### ItemList (for roundup pages) ```json { "@context": "https://schema.org", "@type": "ItemList", "name": "Best [Category] Tools [Year]", "itemListOrder": "https://schema.org/ItemListOrderDescending", "numberOfItems": "[Count]", "itemListElement": [ { "@type": "ListItem", "position": 1, "name": "[Product Name]", "url": "[Product URL]" } ] } ``` ## Keyword Targeting ### Comparison Intent Patterns | Pattern | Example | Search Volume Signal | |---------|---------|---------------------| | `[A] vs [B]` | "Slack vs Teams" | High | | `[A] alternative` | "Figma alternatives" | High | | `[A] alternatives [year]` | "Notion alternatives 2026" | High | | `best [category] tools` | "best project management tools" | High | | `[A] vs [B] for [use case]` | "AWS vs Azure for startups" | Medium | | `[A] review [year]` | "Monday.com review 2026" | Medium | | `[A] vs [B] pricing` | "HubSpot vs Salesforce pricing" | Medium | | `is [A] better than [B]` | "is Notion better than Confluence" | Medium | ### Title Tag Formulas - X vs Y: `[A] vs [B]: [Key Differentiator] ([Year])` - Alternatives: `[N] Best [A] Alternatives in [Year] (Free & Paid)` - Roundup: `[N] Best [Category] Tools in [Year], Compared & Ranked` ### H1 Patterns - Match title tag intent - Include primary keyword naturally - Keep under 70 characters ## Conversion-Optimized Layouts ### CTA Placement - **Above fold**: Brief comparison summary with primary CTA - **After comparison table**: "Try [Your Product] free" CTA - **Bottom of page**: Final recommendation with CTA - Avoid aggressive CTAs in competitor description sections (reduces trust) ### Social Proof Sections - Customer testimonials relevant to comparison criteria - G2/Capterra/TrustPilot ratings (with source links) - Case studies showing migration from competitor - "Switched from [Competitor]" stories ### Pricing Highlights - Clear pricing comparison table - Highlight value advantages (not just lowest price) - Include hidden costs (setup fees, per-user pricing, overage charges) - Link to full pricing page ### Trust Signals - "Last updated [date]" timestamp - Author with relevant expertise - Methodology disclosure (how comparisons were conducted) - Disclosure of own product affiliation ## Fairness Guidelines - **Accuracy**: All competitor information must be verifiable from public sources - **No defamation**: Never make false or misleading claims about competitors - **Cite sources**: Link to competitor websites, review sites, or documentation - **Timely updates**: Review and update when competitors release major changes - **Disclose affiliation**: Clearly state which product is yours - **Balanced presentation**: Acknowledge competitor strengths honestly - **Pricing accuracy**: Include "as of [date]" disclaimers on all pricing data - **Feature verification**: Test competitor features where possible, cite documentation otherwise ## Internal Linking - Link to your own product/service pages from comparison sections - Cross-link between related comparison pages (e.g., "A vs B" links to "A vs C") - Link to feature-specific pages when discussing individual features - Breadcrumb: Home > Comparisons > [This Page] - Related comparisons section at bottom of page - Link to case studies and testimonials mentioned in the comparison ## Output ### Comparison Page Template - `COMPARISON-PAGE.md`: Ready-to-implement page structure with sections - Feature matrix table - Content outline with word count targets (minimum 1,500 words) ### Schema Markup - `comparison-schema.json`: Product/SoftwareApplication/ItemList JSON-LD ### Keyword Strategy - Primary and secondary keywords - Related long-tail opportunities - Content gaps vs existing competitor pages ### Recommendations - Content improvements for existing comparison pages - New comparison page opportunities - Schema markup additions - Conversion optimization suggestions ## Error Handling | Scenario | Action | |----------|--------| | Competitor URL unreachable | Report which competitor URLs failed. Proceed with available data and note gaps in the comparison. | | Insufficient competitor data (pricing, features unavailable) | Flag missing data points clearly. Use "Not publicly available" in comparison tables rather than guessing. | | No product/service overlap found | Report that the products serve different markets. Suggest alternative competitors that share feature overlap, or pivot to a category roundup format. |extensions/banana/skills/seo-image-gen/SKILL.mdskillShow content (8209 bytes)
--- name: seo-image-gen description: "AI image generation for SEO assets: OG/social preview images, blog hero images, schema images, product photography, infographics. Powered by Gemini via nanobanana-mcp. Requires banana extension installed. Use when user says \"generate image\", \"OG image\", \"social preview\", \"hero image\", \"blog image\", \"product photo\", \"infographic\", \"seo image\", \"create visual\", \"image-gen\", \"favicon\", \"schema image\", \"pinterest pin\", \"generate visual\", \"banner\", or \"thumbnail\"." argument-hint: "[og|hero|product|infographic|custom|batch] <description>" user-invokable: true license: MIT compatibility: "Requires nanobanana MCP server" metadata: author: AgriciDaniel version: "1.6.1" category: seo --- # SEO Image Gen: AI Image Generation for SEO Assets (Extension) Generate production-ready images for SEO use cases using Gemini's image generation via the banana Creative Director pipeline. Maps SEO needs to optimized domain modes, aspect ratios, and resolution defaults. ## Architecture Note This extension is built on [Claude Banana](https://github.com/AgriciDaniel/banana-claude), the standalone AI image generation skill for Claude Code. This skill has two components with distinct roles: - **SKILL.md** (this file): Handles interactive `/seo image-gen` commands for generating images - **Agent** (`agents/seo-image-gen.md`): Audit-only analyst spawned during `/seo audit` to assess existing OG/social images and produce a generation plan (never auto-generates) ## Prerequisites This skill requires the banana extension to be installed: ```bash ./extensions/banana/install.sh ``` **Check availability:** Before using any image generation tool, verify the MCP server is connected by checking if `gemini_generate_image` or `set_aspect_ratio` tools are available. If tools are not available, inform the user the extension is not installed and provide install instructions. ## Quick Reference | Command | What it does | |---------|-------------| | `/seo image-gen og <description>` | Generate OG/social preview image (1200x630 feel) | | `/seo image-gen hero <description>` | Blog hero image (widescreen, dramatic) | | `/seo image-gen product <description>` | Product photography (clean, white BG) | | `/seo image-gen infographic <description>` | Infographic visual (vertical, data-heavy) | | `/seo image-gen custom <description>` | Custom image with full Creative Director pipeline | | `/seo image-gen batch <description> [N]` | Generate N variations (default: 3) | ## SEO Image Use Cases Each use case maps to pre-configured banana parameters: | Use Case | Aspect Ratio | Resolution | Domain Mode | Notes | |----------|-------------|------------|-------------|-------| | **OG/Social Preview** | `16:9` | `1K` | Product or UI/Web | Clean, professional, text-friendly | | **Blog Hero** | `16:9` | `2K` | Cinema or Editorial | Dramatic, atmospheric, editorial quality | | **Schema Image** | `4:3` | `1K` | Product | Clean, descriptive, schema ImageObject | | **Social Square** | `1:1` | `1K` | UI/Web | Platform-optimized square | | **Product Photo** | `4:3` | `2K` | Product | White background, studio lighting | | **Infographic** | `2:3` | `4K` | Infographic | Data-heavy, vertical layout | | **Favicon/Icon** | `1:1` | `512` | Logo | Minimal, scalable, recognizable | | **Pinterest Pin** | `2:3` | `2K` | Editorial | Tall vertical card | ## Generation Pipeline For every generation request: 1. **Identify use case** from command or context (og, hero, product, etc.) 2. **Apply SEO defaults** from the use cases table above 3. **Set aspect ratio** via `set_aspect_ratio` MCP tool 4. **Construct Reasoning Brief** using the banana Creative Director pipeline: - Load `references/prompt-engineering.md` for the 6-component system - Apply domain mode emphasis (Subject 30%, Style 25%, Context 15%, etc.) - Be SPECIFIC and VISCERAL: describe what the camera sees 5. **Generate** via `gemini_generate_image` MCP tool 6. **Post-generation SEO checklist** (see below) ### Check for Presets If the user mentions a brand or has SEO presets configured: ```bash python3 scripts/presets.py list ``` Load matching preset and apply as defaults. Also check `references/seo-image-presets.md` for SEO-specific preset templates. ## Post-Generation SEO Checklist After every successful generation, guide the user on: 1. **Alt text**:Write descriptive, keyword-rich alt text for the generated image 2. **File naming**:Rename to SEO-friendly format: `keyword-description-widthxheight.webp` 3. **WebP conversion**:Convert to WebP for optimal page speed: ```bash magick output.png -quality 85 output.webp ``` 4. **File size**:Target under 200KB for hero images, under 100KB for thumbnails 5. **Schema markup**:Suggest `ImageObject` schema for the generated image: ```json { "@type": "ImageObject", "url": "https://example.com/images/keyword-description.webp", "width": 1200, "height": 630, "caption": "Descriptive caption with target keyword" } ``` 6. **OG meta tags**:For social preview images, remind about: ```html <meta property="og:image" content="https://example.com/images/og-image.webp" /> <meta property="og:image:width" content="1200" /> <meta property="og:image:height" content="630" /> <meta property="og:image:alt" content="Descriptive alt text" /> ``` ## Cost Awareness Image generation costs money. Be transparent: - Show estimated cost before generating (especially for batch) - Log every generation: `python3 scripts/cost_tracker.py log --model MODEL --resolution RES --prompt "brief"` - Run `cost_tracker.py summary` if user asks about usage Approximate costs (gemini-3.1-flash): - 512: ~$0.02/image - 1K resolution: ~$0.04/image - 2K resolution: ~$0.08/image - 4K resolution: ~$0.16/image ## Model Routing | Scenario | Model | Why | |----------|-------|-----| | OG images, social previews | `gemini-3.1-flash-image-preview` @ 1K | Fast, cost-effective | | Hero images, product photos | `gemini-3.1-flash-image-preview` @ 2K | Quality + detail | | Infographics with text | `gemini-3.1-flash-image-preview` @ 2K, thinking: high | Better text rendering | | Quick drafts | `gemini-2.5-flash-image` @ 512 | Rapid iteration | ## Error Handling | Error | Resolution | |-------|-----------| | MCP not configured | Run `./extensions/banana/install.sh` | | API key invalid | New key at https://aistudio.google.com/apikey | | Rate limited (429) | Wait 60s, retry. Free tier: ~10 RPM / ~500 RPD | | `IMAGE_SAFETY` | Rephrase prompt - see `references/prompt-engineering.md` Safety section | | MCP unavailable | Fall back: `python3 scripts/generate.py --prompt "..." --aspect-ratio "16:9"` | | Extension not installed | Show install instructions: `./extensions/banana/install.sh` | ## Cross-Skill Integration - **seo-images** (analysis) feeds into **seo-image-gen** (generation): audit results from `/seo images` identify missing or low-quality images; use those findings to drive `/seo image-gen` commands - **seo-audit** spawns the seo-image-gen **agent** (not this skill) to analyze OG/social images across the site and produce a prioritized generation plan - **seo-schema** can consume generated images: after generation, suggest `ImageObject` schema markup pointing to the new assets ## Reference Documentation Load on-demand. Do NOT load all at startup: - `references/prompt-engineering.md`:6-component system, domain modes, templates - `references/gemini-models.md`:Model specs, rate limits, capabilities - `references/mcp-tools.md`:MCP tool parameters and responses - `references/post-processing.md`:ImageMagick/FFmpeg pipeline recipes - `references/cost-tracking.md`:Pricing, usage tracking - `references/presets.md`:Brand preset management - `references/seo-image-presets.md`:SEO-specific preset templates ## Response Format After generating, always provide: 1. **Image path**:where it was saved 2. **Crafted prompt**:show what was sent to the API (educational) 3. **Settings**:model, aspect ratio, resolution 4. **SEO checklist**:alt text suggestion, file naming, WebP conversion 5. **Schema snippet**:ImageObject or og:image markup if applicableextensions/dataforseo/skills/seo-dataforseo/SKILL.mdskillShow content (17332 bytes)
--- name: seo-dataforseo description: > Live SEO data via DataForSEO MCP server. SERP analysis (Google, Bing, Yahoo, YouTube), keyword research (volume, difficulty, intent, trends), backlink profiles, on-page analysis (Lighthouse, content parsing), competitor analysis, content analysis, business listings, AI visibility (ChatGPT scraper, LLM mention tracking), and domain analytics. Requires DataForSEO extension installed. Use when user says "dataforseo", "live SERP", "keyword volume", "backlink data", "competitor data", "AI visibility check", "LLM mentions", or "real search data". user-invokable: true argument-hint: "[command] [query]" license: MIT compatibility: "Requires DataForSEO MCP server" metadata: author: AgriciDaniel version: "1.6.1" category: seo --- # DataForSEO: Live SEO Data (Extension) Live search data via the DataForSEO MCP server. Provides real-time SERP results, keyword metrics, backlink profiles, on-page analysis, content analysis, business listings, AI visibility checking, and LLM mention tracking across 9 API modules with 79 MCP tools. ## Prerequisites This skill requires the DataForSEO extension to be installed: ```bash ./extensions/dataforseo/install.sh ``` **Check availability:** Before using any DataForSEO tool, verify the MCP server is connected by checking if `serp_organic_live_advanced` or any DataForSEO tool is available. If tools are not available, inform the user the extension is not installed and provide install instructions. ## API Credit Awareness DataForSEO charges per API call. Be efficient: - Prefer bulk endpoints over multiple single calls - Use default parameters (US, English) unless user specifies otherwise - Cache results mentally within a session; don't re-fetch the same data - Warn user before running expensive operations (full backlink crawls, large keyword lists) ## Quick Reference | Command | What it does | |---------|-------------| | `/seo dataforseo serp <keyword>` | Google organic SERP results | | `/seo dataforseo serp-youtube <keyword>` | YouTube search results | | `/seo dataforseo youtube <video_id>` | YouTube video deep analysis | | `/seo dataforseo keywords <seed>` | Keyword ideas and suggestions | | `/seo dataforseo volume <keywords>` | Search volume for keywords | | `/seo dataforseo difficulty <keywords>` | Keyword difficulty scores | | `/seo dataforseo intent <keywords>` | Search intent classification | | `/seo dataforseo trends <keyword>` | Google Trends data | | `/seo dataforseo backlinks <domain>` | Full backlink profile | | `/seo dataforseo competitors <domain>` | Competitor domain analysis | | `/seo dataforseo ranked <domain>` | Ranked keywords for domain | | `/seo dataforseo intersection <domains>` | Keyword/backlink overlap | | `/seo dataforseo traffic <domains>` | Bulk traffic estimation | | `/seo dataforseo subdomains <domain>` | Subdomains with ranking data | | `/seo dataforseo top-searches <domain>` | Top queries mentioning domain | | `/seo dataforseo onpage <url>` | On-page analysis (Lighthouse + parsing) | | `/seo dataforseo tech <domain>` | Technology stack detection | | `/seo dataforseo whois <domain>` | WHOIS registration data | | `/seo dataforseo content <keyword/url>` | Content analysis and trends | | `/seo dataforseo listings <keyword>` | Business listings search | | `/seo dataforseo ai-scrape <query>` | ChatGPT web scraper for GEO | | `/seo dataforseo ai-mentions <keyword>` | LLM mention tracking for GEO | --- ## SERP Analysis ### `/seo dataforseo serp <keyword>` Fetch live Google organic search results. **MCP tools:** `serp_organic_live_advanced` **Default parameters:** location_code=2840 (US), language_code=en, device=desktop, depth=100 **Also supports:** The `serp_organic_live_advanced` tool supports Google, Bing, and Yahoo via the `se` parameter. Specify "bing" or "yahoo" to switch search engines. **Output:** Rank, URL, title, description, domain, featured snippets, AI overview references, People Also Ask. ### `/seo dataforseo serp-youtube <keyword>` Fetch YouTube search results. Valuable for GEO. YouTube mentions correlate most strongly with AI citations. **MCP tools:** `serp_youtube_organic_live_advanced` **Output:** Video title, channel, views, upload date, description, URL. ### `/seo dataforseo youtube <video_id>` Deep analysis of a specific YouTube video: info, comments, and subtitles. YouTube mentions have the strongest correlation (0.737) with AI visibility, making this critical for GEO analysis. **MCP tools:** `serp_youtube_video_info_live_advanced`, `serp_youtube_video_comments_live_advanced`, `serp_youtube_video_subtitles_live_advanced` **Parameters:** video_id (the YouTube video ID, e.g., "dQw4w9WgXcQ") **Output:** Video metadata (title, channel, views, likes, description), top comments with engagement, subtitle/transcript text. --- ## Keyword Research ### `/seo dataforseo keywords <seed>` Generate keyword ideas, suggestions, and related terms from a seed keyword. **MCP tools:** `dataforseo_labs_google_keyword_ideas`, `dataforseo_labs_google_keyword_suggestions`, `dataforseo_labs_google_related_keywords` **Default parameters:** location_code=2840 (US), language_code=en, limit=50 **Output:** Keyword, search volume, CPC, competition level, keyword difficulty, trend. ### `/seo dataforseo volume <keywords>` Get search volume and metrics for a list of keywords. **MCP tools:** `kw_data_google_ads_search_volume` **Parameters:** keywords (array, comma-separated), location_code, language_code **Output:** Keyword, monthly search volume, CPC, competition, monthly trend data. ### `/seo dataforseo difficulty <keywords>` Calculate keyword difficulty scores for ranking competitiveness. **MCP tools:** `dataforseo_labs_bulk_keyword_difficulty` **Parameters:** keywords (array), location_code, language_code **Output:** Keyword, difficulty score (0-100), interpretation (Easy/Medium/Hard/Very Hard). ### `/seo dataforseo intent <keywords>` Classify keywords by user search intent. **MCP tools:** `dataforseo_labs_search_intent` **Parameters:** keywords (array), location_code, language_code **Output:** Keyword, intent type (informational, navigational, commercial, transactional), confidence score. ### `/seo dataforseo trends <keyword>` Analyze keyword trends over time using Google Trends data. **MCP tools:** `kw_data_google_trends_explore` **Parameters:** keywords (array), location_code, date_from, date_to, language_code **Output:** Keyword, time series data, trend direction, seasonality signals. --- ## Domain & Competitor Analysis ### `/seo dataforseo backlinks <domain>` Comprehensive backlink profile analysis. **MCP tools:** `backlinks_summary`, `backlinks_backlinks`, `backlinks_anchors`, `backlinks_referring_domains`, `backlinks_bulk_spam_score`, `backlinks_timeseries_summary` **Default parameters:** limit=100 per sub-call **Output:** Total backlinks, referring domains, domain rank, spam score, top anchors, new/lost backlinks over time, dofollow ratio, top referring domains. ### `/seo dataforseo competitors <domain>` Identify competing domains and estimate traffic. **MCP tools:** `dataforseo_labs_google_competitors_domain`, `dataforseo_labs_google_domain_rank_overview`, `dataforseo_labs_bulk_traffic_estimation` **Output:** Competitor domains, keyword overlap %, estimated traffic, domain rank, common keywords. ### `/seo dataforseo ranked <domain>` List keywords a domain ranks for with positions and page data. **MCP tools:** `dataforseo_labs_google_ranked_keywords`, `dataforseo_labs_google_relevant_pages` **Default parameters:** limit=100, location_code=2840 **Output:** Keyword, position, URL, search volume, traffic share, SERP features. ### `/seo dataforseo intersection <domain1> <domain2> [...]` Find shared keywords and backlink sources across 2-20 domains. **MCP tools:** `dataforseo_labs_google_domain_intersection`, `backlinks_domain_intersection` **Parameters:** domains (2-20 array) **Output:** Shared keywords with positions per domain, shared backlink sources, unique keywords per domain. ### `/seo dataforseo traffic <domains>` Estimate organic search traffic for one or more domains. **MCP tools:** `dataforseo_labs_bulk_traffic_estimation` **Parameters:** domains (array) **Output:** Domain, estimated organic traffic, estimated traffic cost, top keywords. ### `/seo dataforseo subdomains <domain>` Enumerate subdomains with their ranking data and traffic estimates. **MCP tools:** `dataforseo_labs_google_subdomains` **Parameters:** target (domain), location_code, language_code **Output:** Subdomain, ranked keywords count, estimated traffic, organic cost. ### `/seo dataforseo top-searches <domain>` Find the most popular search queries that mention a specific domain in results. **MCP tools:** `dataforseo_labs_google_top_searches` **Parameters:** target (domain), location_code, language_code **Output:** Query, search volume, domain position, SERP features, traffic share. --- ## Technical / On-Page ### `/seo dataforseo onpage <url>` Run on-page analysis including Lighthouse audit and content parsing. **MCP tools:** `on_page_instant_pages`, `on_page_content_parsing`, `on_page_lighthouse` **Usage:** - `on_page_instant_pages`:Quick page analysis (status codes, meta tags, content size, page timing, broken links, on-page checks) - `on_page_content_parsing`:Extract and parse page content (plain text, word count, structure) - `on_page_lighthouse`:Full Lighthouse audit (performance score, accessibility, best practices, SEO, Core Web Vitals) **Output:** Pages crawled, status codes, meta tags, titles, content size, load times, Lighthouse scores, broken links, resource analysis. ### `/seo dataforseo tech <domain>` Detect technologies used on a domain. **MCP tools:** `domain_analytics_technologies_domain_technologies` **Output:** Technology name, version, category (CMS, analytics, CDN, framework, etc.). ### `/seo dataforseo whois <domain>` Retrieve WHOIS registration data. **MCP tools:** `domain_analytics_whois_overview` **Output:** Registrar, creation date, expiration date, nameservers, registrant info (if public). --- ## Content & Business Data ### `/seo dataforseo content <keyword/url>` Analyze content quality, search for content by topic, and track phrase trends. **MCP tools:** `content_analysis_search`, `content_analysis_summary`, `content_analysis_phrase_trends` **Parameters:** keyword (for search/trends) or URL (for summary) **Output:** Content matches with quality scores, sentiment analysis, readability metrics, phrase trend data over time. ### `/seo dataforseo listings <keyword>` Search business listings for local SEO competitive analysis. **MCP tools:** `business_data_business_listings_search` **Parameters:** keyword, location (optional) **Output:** Business name, description, category, address, phone, domain, rating, review count, claimed status. --- ## AI Visibility / GEO ### `/seo dataforseo ai-scrape <query>` Scrape what ChatGPT web search returns for a query. Real GEO visibility check: see which sources ChatGPT cites for your target keywords. **MCP tools:** `ai_optimization_chat_gpt_scraper` **Parameters:** query, location_code (optional), language_code (optional). Use `ai_optimization_chat_gpt_scraper_locations` to look up available locations. **Output:** ChatGPT response content, cited sources/URLs, referenced domains. ### `/seo dataforseo ai-mentions <keyword>` Track how LLMs mention brands, domains, and topics. Critical for GEO. Measures actual AI visibility across multiple LLM platforms. **MCP tools:** `ai_opt_llm_ment_search`, `ai_opt_llm_ment_top_domains`, `ai_opt_llm_ment_top_pages`, `ai_opt_llm_ment_agg_metrics` **Parameters:** keyword, location_code (optional), language_code (optional). Use `ai_opt_llm_ment_loc_and_lang` for available locations/languages and `ai_optimization_llm_models` for supported LLM models. **Workflow:** 1. Search LLM mentions with `ai_opt_llm_ment_search` (find mentions of a brand/keyword across LLM responses) 2. Get top cited domains with `ai_opt_llm_ment_top_domains` (which domains are most cited for this topic) 3. Get top cited pages with `ai_opt_llm_ment_top_pages` (which specific pages are most cited) 4. Get aggregate metrics with `ai_opt_llm_ment_agg_metrics` (overall mention volume, trends) **Output:** LLM mention count, top cited domains with frequency, top cited pages, mention trends over time, cross-platform visibility scores. **Advanced:** Use `ai_opt_llm_ment_cross_agg_metrics` for cross-model comparison (how mentions differ across ChatGPT, Claude, Perplexity, etc.). --- ## Available Utility Tools These DataForSEO tools are available for internal use by the agent but do not have dedicated commands: - `serp_locations`:Location code lookups for SERP queries - `serp_youtube_locations`:Location code lookups for YouTube queries - `kw_data_google_ads_locations`:Location lookups for keyword data - `kw_data_dfs_trends_demography`:Demographic data for trend analysis - `kw_data_dfs_trends_subregion_interests`:Subregion interest data for trends - `kw_data_dfs_trends_explore`:DFS proprietary trends data - `kw_data_google_trends_categories`:Google Trends category lookups - `dataforseo_labs_google_keyword_overview`:Quick keyword metrics overview - `dataforseo_labs_google_historical_serp`:Historical SERP results for a keyword - `dataforseo_labs_google_serp_competitors`:Competitors for a specific SERP - `dataforseo_labs_google_keywords_for_site`:Keywords a site ranks for (alternative to ranked) - `dataforseo_labs_google_page_intersection`:Page-level intersection analysis - `dataforseo_labs_google_historical_rank_overview`:Historical domain rank data - `dataforseo_labs_google_historical_keyword_data`:Historical keyword metrics - `dataforseo_labs_available_filters`:Available filter options for Labs endpoints - `backlinks_competitors`:Find domains with similar backlink profiles - `backlinks_bulk_backlinks`:Bulk backlink counts for multiple targets - `backlinks_bulk_new_lost_referring_domains`:Bulk new/lost referring domains - `backlinks_bulk_new_lost_backlinks`:Bulk new/lost backlinks - `backlinks_bulk_ranks`:Bulk rank overview for multiple targets - `backlinks_bulk_referring_domains`:Bulk referring domain counts - `backlinks_domain_pages_summary`:Summary of pages on a domain - `backlinks_domain_pages`:List pages on a domain with backlink data - `backlinks_page_intersection`:Shared backlink sources at page level - `backlinks_referring_networks`:Referring network analysis - `backlinks_timeseries_new_lost_summary`:Track new/lost backlinks over time - `backlinks_bulk_pages_summary`:Bulk page summaries - `backlinks_available_filters`:Available filter options for Backlinks endpoints - `domain_analytics_whois_available_filters`:WHOIS filter options - `domain_analytics_technologies_available_filters`:Technology detection filter options - `ai_opt_kw_data_loc_and_lang`:AI optimization keyword data locations/languages - `ai_optimization_keyword_data_search_volume`:AI-specific keyword volume data - `ai_optimization_llm_response`:Direct LLM response analysis - `ai_optimization_llm_mentions_filters`:Available filters for LLM mentions - `ai_optimization_chat_gpt_scraper_locations`:Available locations for ChatGPT scraper ## Cross-Skill Integration When DataForSEO MCP tools are available, other claude-seo skills can leverage live data: - **seo-audit**:Spawn `seo-dataforseo` agent for real SERP, backlink, on-page, and listings data - **seo-technical**:Use `on_page_instant_pages` / `on_page_lighthouse` for real crawl data, `domain_analytics_technologies_domain_technologies` for stack detection - **seo-content**:Use `kw_data_google_ads_search_volume`, `dataforseo_labs_bulk_keyword_difficulty`, `dataforseo_labs_search_intent` for real keyword metrics, `content_analysis_summary` for content quality - **seo-page**:Use `serp_organic_live_advanced` for real SERP positions, `backlinks_summary` for link data - **seo-geo**:Use `ai_optimization_chat_gpt_scraper` for real ChatGPT visibility, `ai_opt_llm_ment_search` for LLM mention tracking - **seo-plan**:Use `dataforseo_labs_google_competitors_domain`, `dataforseo_labs_google_domain_intersection`, `dataforseo_labs_bulk_traffic_estimation` for real competitive intelligence ## Error Handling - **MCP server not connected**: Report that DataForSEO extension is not installed or MCP server is unreachable. Suggest running `./extensions/dataforseo/install.sh` - **API authentication failed**: Report invalid credentials. Suggest checking DataForSEO API login/password in MCP config - **Rate limit exceeded**: Report the limit hit and suggest waiting before retrying - **No results returned**: Report "no data found" for the query rather than guessing. Suggest broadening the query or checking location/language codes - **Invalid location code**: Report the error and suggest using the locations lookup tool to find the correct code ## Output Formatting Match existing claude-seo output patterns: - Use tables for comparative data - Prioritize issues as Critical > High > Medium > Low - Include specific, actionable recommendations - Show scores as XX/100 where applicable - Note data source as "DataForSEO (live)" to distinguish from static analysisextensions/firecrawl/skills/seo-firecrawl/SKILL.mdskillShow content (8078 bytes)
--- name: seo-firecrawl description: > Full-site crawling, scraping, and site mapping via Firecrawl MCP. Use when user says "crawl site", "map site", "full crawl", "find all pages", "broken links", "site structure", "discover pages", "JS rendering", or needs site-wide analysis. user-invokable: true argument-hint: "[command] <url>" license: MIT compatibility: "Requires Firecrawl MCP server" metadata: author: AgriciDaniel version: "1.7.2" category: seo --- # Firecrawl Extension for Claude SEO This skill requires the Firecrawl extension to be installed: ```bash ./extensions/firecrawl/install.sh ``` **Check availability:** Before using any Firecrawl tool, verify the MCP server is connected by checking if `firecrawl_scrape` or any Firecrawl tool is available. If tools are not available, inform the user the extension is not installed and provide install instructions. ## Quick Reference | Command | Purpose | |---------|---------| | `/seo firecrawl crawl <url>` | Full-site crawl with content extraction | | `/seo firecrawl map <url>` | Discover site structure (URLs only, fast) | | `/seo firecrawl scrape <url>` | Single-page scrape with JS rendering | | `/seo firecrawl search <query> <url>` | Search within a crawled site | ## Commands ### crawl -- Full-Site Crawl Crawl an entire website starting from the given URL. Returns page content, metadata, and links for all discovered pages. **MCP Tool:** `firecrawl_crawl` **Parameters:** - `url` (required): Starting URL to crawl - `limit`: Max pages to crawl (default: 100, max: 500) - `maxDepth`: Max link depth from start URL (default: 3) - `includePaths`: Array of glob patterns to include (e.g., `["/blog/*"]`) - `excludePaths`: Array of glob patterns to exclude (e.g., `["/admin/*", "/api/*"]`) - `scrapeOptions.formats`: Output formats -- `["markdown", "html", "links"]` **SEO Usage Patterns:** 1. **Comprehensive audit crawl**: Crawl full site, extract all pages for subagent analysis 2. **Section-focused crawl**: Use `includePaths` to audit only `/blog/*` or `/products/*` 3. **Broken link detection**: Crawl with `["links"]` format, check all hrefs for 404s 4. **Content inventory**: Extract all page titles, meta descriptions, H1s at scale 5. **SPA/JS-rendered sites**: Firecrawl renders JavaScript, solving the Issue #11 problem **Example orchestration for `/seo audit`:** ``` 1. firecrawl_map(url) -> get all URLs (fast, no content) 2. Filter to top 50 most important pages (homepage, key sections) 3. firecrawl_crawl(url, limit=50) -> get full content 4. Feed content to seo-technical, seo-content, seo-schema agents ``` **Cost awareness:** - Free tier: 500 credits/month - 1 credit = 1 page crawled or scraped - Map operations are cheaper (0.5 credits per URL discovered) - Always inform user of estimated credit usage before large crawls ### map -- Site Structure Discovery Discover all URLs on a website without fetching content. Fast and credit-efficient. **MCP Tool:** `firecrawl_map` **Parameters:** - `url` (required): Website URL to map - `limit`: Max URLs to discover (default: 5000) - `search`: Optional search term to filter URLs **SEO Usage Patterns:** 1. **Sitemap comparison**: Map site, compare discovered URLs vs XML sitemap 2. **Orphan page detection**: URLs in sitemap but not linked from any page 3. **Crawl budget analysis**: Total indexable pages vs pages linked from homepage 4. **URL pattern analysis**: Identify URL structure patterns, duplicates, parameter bloat 5. **Pre-audit discovery**: Run map first, then targeted crawl on key sections **Output:** Array of URLs. Present as: ``` Site: example.com Pages discovered: 342 URL Pattern Breakdown: /blog/* - 128 pages (37%) /products/* - 89 pages (26%) /category/* - 45 pages (13%) /pages/* - 32 pages (9%) / (root pages) - 48 pages (14%) ``` ### scrape -- Single-Page Deep Scrape Scrape a single page with full JavaScript rendering. More thorough than `fetch_page.py` because it executes JS and waits for dynamic content. **MCP Tool:** `firecrawl_scrape` **Parameters:** - `url` (required): Page URL to scrape - `formats`: Output formats -- `["markdown", "html", "links", "screenshot"]` - `onlyMainContent`: Strip nav/footer/sidebar (default: true) - `waitFor`: CSS selector or milliseconds to wait for content - `timeout`: Request timeout in ms (default: 30000) - `actions`: Browser actions before scraping (click, scroll, wait) **SEO Usage Patterns:** 1. **SPA content extraction**: Scrape JS-rendered React/Vue/Angular pages 2. **Dynamic content audit**: Pages with lazy-loaded content below the fold 3. **Paywall/login detection**: Identify content behind authentication walls 4. **Main content extraction**: Use `onlyMainContent` for clean E-E-A-T analysis 5. **Screenshot capture**: Use `screenshot` format for visual analysis **When to use scrape vs fetch_page.py:** | Scenario | Use | |----------|-----| | Static HTML page | `fetch_page.py` (no API cost) | | JS-rendered SPA | `firecrawl_scrape` (renders JS) | | Need response headers | `fetch_page.py` (returns headers) | | Need clean markdown | `firecrawl_scrape` (better extraction) | | Rate-limited/blocked | `firecrawl_scrape` (handles anti-bot) | ### search -- Site-Scoped Search Search within a website for specific content. Useful for finding pages related to a topic without crawling everything. **MCP Tool:** `firecrawl_search` **Parameters:** - `query` (required): Search query - `url` (required): Website to search within - `limit`: Max results (default: 10) - `scrapeOptions.formats`: Output format for matched pages **SEO Usage Patterns:** 1. **Content gap validation**: Search for a keyword on the site to check if content exists 2. **Internal linking opportunities**: Find pages mentioning a topic that could link to each other 3. **Duplicate content detection**: Search for key phrases to find near-duplicates 4. **Competitor content research**: Search competitor site for specific topics ## Cross-Skill Integration ### With seo-audit (full audit) When Firecrawl is available during `/seo audit`: 1. Use `firecrawl_map` to discover all site URLs 2. Compare with XML sitemap (seo-sitemap) to find orphan/missing pages 3. Select top pages for deep analysis 4. Feed crawled content to all subagents (technical, content, schema, geo) 5. Report total crawlable pages, URL patterns, and crawl depth ### With seo-technical - Broken link detection: crawl all internal links, check for 404s - Redirect chain mapping: follow all redirects, flag chains > 2 hops - Mixed content detection: check HTTP resources on HTTPS pages - Canonical verification: compare canonical URLs with actual URLs ### With seo-sitemap - Sitemap coverage: % of crawled pages present in sitemap - Orphan pages: pages found by crawl but missing from sitemap - Stale sitemap entries: URLs in sitemap that return 404/410 ### With seo-content - Content extraction: feed clean markdown to E-E-A-T analysis - Thin content detection: identify pages with < 300 words at scale - Duplicate content: compare content across pages for near-duplicates ### With seo-schema - Schema extraction: pull JSON-LD from all crawled pages - Schema coverage: % of pages with structured data - Schema validation: batch-validate extracted schemas ## Error Handling | Error | Cause | Resolution | |-------|-------|-----------| | `FIRECRAWL_API_KEY not set` | MCP not configured | Run `./extensions/firecrawl/install.sh` | | `402 Payment Required` | Credits exhausted | Check usage at firecrawl.dev/app, upgrade plan | | `429 Too Many Requests` | Rate limited | Wait 60s, reduce crawl concurrency | | `408 Timeout` | Page too slow to render | Increase `timeout`, try without JS rendering | | `403 Forbidden` | Site blocks crawling | Check robots.txt, may need to skip this site | **Graceful fallback:** If Firecrawl is unavailable, inform the user and suggest: 1. Use `fetch_page.py` for single-page analysis (no API cost) 2. Use `WebFetch` tool for basic HTML retrieval 3. Install Firecrawl: `./extensions/firecrawl/install.sh`skills/seo-audit/SKILL.mdskillShow content (6288 bytes)
--- name: seo-audit description: "Full website SEO audit with parallel subagent delegation. Crawls up to 500 pages, detects business type, delegates to up to 15 specialists (8 always + 7 conditional), generates health score. Use when user says audit, full SEO check, analyze my site, or website health check." user-invokable: true argument-hint: "[url]" license: MIT metadata: author: AgriciDaniel version: "1.9.6" category: seo --- # Full Website SEO Audit ## Process 1. **Fetch homepage**: use `scripts/fetch_page.py` to retrieve HTML 2. **Detect business type**: analyze homepage signals per seo orchestrator 3. **Crawl site**: follow internal links up to 500 pages, respect robots.txt 4. **Delegate to subagents** (if available, otherwise run inline sequentially): - `seo-technical` -- robots.txt, sitemaps, canonicals, Core Web Vitals, security headers - `seo-content` -- E-E-A-T, readability, thin content, AI citation readiness - `seo-schema` -- detection, validation, generation recommendations - `seo-sitemap` -- structure analysis, quality gates, missing pages - `seo-performance` -- LCP, INP, CLS measurements - `seo-visual` -- screenshots, mobile testing, above-fold analysis - `seo-geo` -- AI crawler access, llms.txt, citability, brand mention signals - `seo-local` -- GBP signals, NAP consistency, reviews, local schema, industry-specific local factors (spawn when Local Service industry detected: brick-and-mortar, SAB, or hybrid business type) - `seo-maps` -- Geo-grid rank tracking, GBP audit, review intelligence, competitor radius mapping (spawn when Local Service detected AND DataForSEO MCP available) - `seo-google` -- CWV field data (CrUX), URL indexation (GSC), organic traffic (GA4) (spawn when Google API credentials detected via `python scripts/google_auth.py --check`) - `seo-backlinks` -- Backlink profile data: DA/PA, referring domains, anchor text, toxic links (spawn when Moz or Bing API credentials detected via `python scripts/backlinks_auth.py --check`, or always include Common Crawl domain-level metrics) - `seo-cluster` -- Semantic clustering analysis (spawn when content strategy signals detected: blog, pillar pages, topic clusters) - `seo-sxo` -- Search experience analysis: page-type mismatch, user stories, persona scoring (always include in full audits) - `seo-drift` -- Drift analysis: compare against stored baseline (spawn when drift baseline exists for the URL via `python scripts/drift_history.py <url>`) - `seo-ecommerce` -- Product schema, marketplace intelligence (spawn when E-commerce industry detected) 5. **Score** -- aggregate into SEO Health Score (0-100) 6. **Report** -- generate prioritized action plan ## Crawl Configuration ``` Max pages: 500 Respect robots.txt: Yes Follow redirects: Yes (max 3 hops) Timeout per page: 30 seconds Concurrent requests: 5 Delay between requests: 1 second ``` ## Output Files - `FULL-AUDIT-REPORT.md`: Comprehensive findings - `ACTION-PLAN.md`: Prioritized recommendations (Critical > High > Medium > Low) - `screenshots/`: Desktop + mobile captures (if Playwright available) - **PDF Report** (recommended): Generate a professional A4 PDF using `scripts/google_report.py --type full`. This produces a white-cover enterprise report with TOC, executive summary, charts (Lighthouse gauges, query bars, index donut), metric cards, threshold tables, prioritized recommendations with effort estimates, and implementation roadmap. Always offer PDF generation after completing an audit. ## Scoring Weights | Category | Weight | |----------|--------| | Technical SEO | 22% | | Content Quality | 23% | | On-Page SEO | 20% | | Schema / Structured Data | 10% | | Performance (CWV) | 10% | | AI Search Readiness | 10% | | Images | 5% | ## Report Structure ### Executive Summary - Overall SEO Health Score (0-100) - Business type detected - Top 5 critical issues - Top 5 quick wins ### Technical SEO - Crawlability issues - Indexability problems - Security concerns - Core Web Vitals status ### Content Quality - E-E-A-T assessment - Thin content pages - Duplicate content issues - Readability scores ### On-Page SEO - Title tag issues - Meta description problems - Heading structure - Internal linking gaps ### Schema & Structured Data - Current implementation - Validation errors - Missing opportunities ### Performance - LCP, INP, CLS scores - Resource optimization needs - Third-party script impact ### Images - Missing alt text - Oversized images - Format recommendations ### AI Search Readiness - Citability score - Structural improvements - Authority signals ## Priority Definitions - **Critical**: Blocks indexing or causes penalties (fix immediately) - **High**: Significantly impacts rankings (fix within 1 week) - **Medium**: Optimization opportunity (fix within 1 month) - **Low**: Nice to have (backlog) ## DataForSEO Integration (Optional) If DataForSEO MCP tools are available, spawn the `seo-dataforseo` agent alongside existing subagents to enrich the audit with live data: real SERP positions, backlink profiles with spam scores, on-page analysis (Lighthouse), business listings, and AI visibility checks (ChatGPT scraper, LLM mentions). ## Google API Integration (Optional) If Google API credentials are configured (`python scripts/google_auth.py --check`), spawn the `seo-google` agent to enrich the audit with real Google field data: CrUX Core Web Vitals (replaces lab-only estimates), GSC URL indexation status, search performance (clicks, impressions, CTR), and GA4 organic traffic trends. The Performance (CWV) category score benefits most from field data. ## Error Handling | Scenario | Action | |----------|--------| | URL unreachable (DNS failure, connection refused) | Report the error clearly. Do not guess site content. Suggest the user verify the URL and try again. | | robots.txt blocks crawling | Report which paths are blocked. Analyze only accessible pages and note the limitation in the report. | | Rate limiting (429 responses) | Back off and reduce concurrent requests. Report partial results with a note on which sections could not be completed. | | Timeout on large sites (500+ pages) | Cap the crawl at the timeout limit. Report findings for pages crawled and estimate total site scope. |skills/seo-backlinks/SKILL.mdskillShow content (12589 bytes)
--- name: seo-backlinks description: "Backlink profile analysis: referring domains, anchor text distribution, toxic link detection, competitor gap analysis. Works with free APIs (Moz, Bing Webmaster, Common Crawl) and DataForSEO extension. Use when user says backlinks, link profile, referring domains, anchor text, toxic links, link gap, link building, disavow, or backlink audit." user-invokable: true argument-hint: "<url>" license: MIT compatibility: "Free: Common Crawl + verify always available. Optional: Moz API, Bing Webmaster (free signup). Premium: DataForSEO extension." metadata: author: AgriciDaniel version: "1.9.6" category: seo --- # Backlink Profile Analysis ## Source Detection Before analysis, detect available data sources: 1. **DataForSEO MCP** (premium): Check if `dataforseo_backlinks_summary` tool is available 2. **Moz API** (free signup): `python scripts/backlinks_auth.py --check moz --json` 3. **Bing Webmaster** (free signup): `python scripts/backlinks_auth.py --check bing --json` 4. **Common Crawl** (always available): Domain-level graph with PageRank 5. **Verification Crawler** (always available): Checks if known backlinks still exist Run `python scripts/backlinks_auth.py --check --json` to detect all sources at once. If no sources are configured beyond the always-available tier: - Still produce a report using Common Crawl domain metrics - Suggest: "Run `/seo backlinks setup` to add free Moz and Bing API keys for richer data" ## Quick Reference | Command | Purpose | |---------|---------| | `/seo backlinks <url>` | Full backlink profile analysis (uses all available sources) | | `/seo backlinks gap <url1> <url2>` | Competitor backlink gap analysis | | `/seo backlinks toxic <url>` | Toxic link detection and disavow recommendations | | `/seo backlinks new <url>` | New and lost backlinks (DataForSEO only) | | `/seo backlinks verify <url> --links <file>` | Verify known backlinks still exist | | `/seo backlinks setup` | Show setup instructions for free backlink APIs | ## Analysis Framework Produce all 7 sections below. Each section lists data sources in preference order. ### 1. Profile Overview **DataForSEO:** `dataforseo_backlinks_summary` → total backlinks, referring domains, domain rank, follow ratio, trend. **Moz API:** `python scripts/moz_api.py metrics <url> --json` → Domain Authority, Page Authority, Spam Score, linking root domains, external links. **Common Crawl:** `python scripts/commoncrawl_graph.py <domain> --json` → in-degree (referring domain count), PageRank, harmonic centrality. **Scoring:** | Metric | Good | Warning | Critical | |--------|------|---------|----------| | Referring domains | >100 | 20-100 | <20 | | Follow ratio | >60% | 40-60% | <40% | | Domain diversity | No single domain >5% | 1 domain >10% | 1 domain >25% | | Trend | Growing or stable | Slow decline | Rapid decline (>20%/quarter) | ### 2. Anchor Text Distribution **DataForSEO:** `dataforseo_backlinks_anchors` **Moz API:** `python scripts/moz_api.py anchors <url> --json` **Bing Webmaster:** `python scripts/bing_webmaster.py links <url> --json` (extract anchor text from link details) **Healthy distribution benchmarks:** | Anchor Type | Target Range | Over-Optimization Signal | |-------------|-------------|-------------------------| | Branded (company/domain name) | 30-50% | <15% | | URL/naked link | 15-25% | N/A | | Generic ("click here", "learn more") | 10-20% | N/A | | Exact match keyword | 3-10% | >15% | | Partial match keyword | 5-15% | >25% | | Long-tail / natural | 5-15% | N/A | Flag if exact-match anchors exceed 15% -- this is a Google Penguin risk signal. ### 3. Referring Domain Quality **DataForSEO:** `dataforseo_backlinks_referring_domains` **Moz API:** `python scripts/moz_api.py domains <url> --json` → domains with DA scores **Common Crawl:** `python scripts/commoncrawl_graph.py <domain> --json` → top referring domains (domain-level, no authority scores) Analyze: - **TLD distribution**: .edu, .gov, .org = high authority. Excessive .xyz, .info = low quality - **Country distribution**: Match target market. 80%+ from irrelevant countries = PBN signal - **Domain rank distribution**: Healthy profiles have links from all authority tiers - **Follow/nofollow per domain**: Sites that only nofollow = limited SEO value ### 4. Toxic Link Detection **DataForSEO:** `dataforseo_backlinks_bulk_spam_score` + toxic patterns from reference **Moz API:** Spam Score from `python scripts/moz_api.py metrics <url> --json` (1-17% scale, >11% = high risk) **Verification Crawler:** `python scripts/verify_backlinks.py --target <url> --links <file> --json` (verify suspicious links still exist) **High-risk indicators (flag immediately):** - Links from known PBN (Private Blog Network) domains - Unnatural anchor text patterns (100% exact match from a domain) - Links from penalized or deindexed domains - Mass directory submissions (50+ directory links) - Link farms (sites with 10K+ outbound links per page) - Paid link patterns (footer/sidebar links across all pages of a domain) **Medium-risk indicators (review manually):** - Links from unrelated niches - Reciprocal link patterns - Links from thin content pages (<100 words) - Excessive links from a single domain (>50 backlinks from 1 domain) Load `references/backlink-quality.md` for the full 30 toxic patterns and disavow criteria. ### 5. Top Pages by Backlinks **DataForSEO:** `dataforseo_backlinks_backlinks` with target type "page" **Moz API:** `python scripts/moz_api.py pages <domain> --json` Find: - Which pages attract the most backlinks - Pages with high-authority links (link magnets) - Pages with zero backlinks (internal linking opportunities) - 404 pages with backlinks (redirect opportunities to reclaim link equity) ### 6. Competitor Gap Analysis **DataForSEO:** `dataforseo_backlinks_referring_domains` for both domains, then compare **Bing Webmaster (unique!):** `python scripts/bing_webmaster.py compare <url1> <url2> --json` — the only free tool with built-in competitor comparison **Moz API:** Compare DA/PA between domains via `python scripts/moz_api.py metrics <url> --json` for each Output: - Domains linking to competitor but NOT to target = link building opportunities - Domains linking to both = validate existing relationships - Domains linking only to target = competitive advantage - Top 20 link building opportunities with domain authority ### 7. New and Lost Backlinks **DataForSEO only:** `dataforseo_backlinks_backlinks` with date filters for 30/60/90 day changes **Verification Crawler:** For known links, verify current status with `python scripts/verify_backlinks.py` **Note:** Free sources cannot track new/lost links over time. If this section is requested without DataForSEO, inform the user: "Link velocity tracking requires the DataForSEO extension. Free sources provide point-in-time snapshots only." **Red flags:** - Sudden spike in new links (possible negative SEO attack) - Sudden loss of many links (site penalty or content removal) - Declining velocity over 3+ months (content not attracting links) ## Backlink Health Score Calculate a 0-100 score. When mixing sources, apply confidence weighting: | Factor | Weight | Sources (preference order) | Confidence | |--------|--------|---------------------------|------------| | Referring domain count | 20% | DataForSEO > Moz > CC in-degree | 1.0 / 0.85 / 0.50 | | Domain quality distribution | 20% | DataForSEO > Moz DA distribution | 1.0 / 0.85 | | Anchor text naturalness | 15% | DataForSEO > Moz > Bing anchors | 1.0 / 0.85 / 0.70 | | Toxic link ratio | 20% | DataForSEO > Moz spam score | 1.0 / 0.85 | | Link velocity trend | 10% | DataForSEO only | 1.0 | | Follow/nofollow ratio | 5% | DataForSEO > Bing details | 1.0 / 0.70 | | Geographic relevance | 10% | DataForSEO > Bing country | 1.0 / 0.70 | **Data sufficiency gate:** Count how many of the 7 factors have at least one data source available. - **4+ factors with data:** Produce a numeric 0-100 score (redistribute missing weights proportionally) - **Fewer than 4 factors:** Do NOT produce a numeric score. Instead display: ``` Backlink Health Score: INSUFFICIENT DATA (X/7 factors scored) ``` Show individual factor scores that ARE available with their source and confidence. Recommend: "Configure Moz API (free) for a scoreable profile. Run `/seo backlinks setup`" When only CC is available, cap maximum score at 70/100. A numeric score with fewer than 4 data sources is **misleading** — it implies poor health when the reality is we simply lack data. ## Output Format ### Backlink Health Score: XX/100 (or INSUFFICIENT DATA) | Section | Status | Score | Data Source | |---------|--------|-------|-------------| | Profile Overview | pass/warn/fail | XX/100 | Moz (0.85) | | Anchor Distribution | pass/warn/fail | XX/100 | Moz (0.85) | | Referring Domain Quality | pass/warn/fail | XX/100 | CC (0.50) | | Toxic Links | pass/warn/fail | XX/100 | Moz Spam (0.85) | | Top Pages | info | N/A | Moz (0.85) | | Link Velocity | pass/warn/fail | XX/100 | DataForSEO only | ### Critical Issues (fix immediately) ### High Priority (fix within 1 month) ### Medium Priority (ongoing improvement) ### Link Building Opportunities (top 10) ## Error Handling | Error | Cause | Resolution | |-------|-------|-----------| | No sources configured | No API keys, no DataForSEO | Run `/seo backlinks setup` | | Moz rate limit | Free tier: 1 req/10s | Wait 10 seconds, retry. Built into script. | | Bing site not verified | Site not verified in Bing | Verify at https://www.bing.com/webmasters | | CC download timeout | Large graph file, slow connection | Use `--timeout 180` flag | | DataForSEO unavailable | Extension not installed | Run `./extensions/dataforseo/install.sh` | | No backlink data returned | Domain too new or very small | Note: small sites may have <10 backlinks | **Fallback cascade:** 1. DataForSEO available? → Use as primary (confidence: 1.0) 2. Moz configured? → Use for DA/PA/spam/anchors (confidence: 0.85) 3. Bing configured? → Use for links/competitor comparison (confidence: 0.70) 4. Always: Common Crawl for domain-level metrics (confidence: 0.50) 5. Always: Verification crawler for known link checks (confidence: 0.95) 6. Nothing works? → "Run `/seo backlinks setup` to configure free APIs" ## Pre-Delivery Review (MANDATORY) Before presenting any backlink analysis to the user, run this checklist internally. Do NOT skip this step. Fix any issues found before showing the report. ### Fact-Check Every Claim - [ ] **Schema claims**: Did parse_html return `@type` for each block? If any `@type` is missing, re-check — it may use `@graph` wrapper (valid JSON-LD, not malformed). - [ ] **"link_removed" findings**: Is the page JS-rendered? If `unverifiable_js`, say so — never report a JS-rendered page as "link removed" (that's a false negative). - [ ] **H1 findings**: Are any H1s in the `h1_suspicious` list? If so, note they are likely counters/stats, not semantic headings. - [ ] **Reciprocal links**: If site A links to site B AND B links back to A, flag it as a reciprocal link pattern. Check outbound links against verified inbound sources. - [ ] **Health score**: Are 4+ of 7 factors scored? If not, report INSUFFICIENT DATA — never show a misleading numeric score. ### Verify Data Source Labels - [ ] Every metric in the report has a source label (e.g., "Parsed (0.95)", "CC (0.50)") - [ ] Every "not found" result distinguishes between "not crawled" vs "below threshold" vs "error" - [ ] Social media pages flagged as `unverifiable_js` (not `link_removed`) ### Cross-Check Consistency - [ ] Platform detection matches actual signals (check for wp-content, shopify CDN, etc.) - [ ] Referring domain count in summary matches the actual verified links list - [ ] No claim is presented without a data source backing it If ANY check fails, fix the finding before presenting. Never present inferred data as fact. ## Post-Analysis After completing any backlink analysis command, always offer: "Generate a professional PDF report? Use `/seo google report`" ## Reference Documentation Load on demand (do NOT load at startup): - `skills/seo/references/backlink-quality.md` -- Detailed toxic link patterns and scoring methodology (shared reference, load when analyzing toxic links or spam scores) - `skills/seo/references/free-backlink-sources.md` -- Source comparison, confidence weighting, setup guides (shared reference, load when configuring free backlink APIs)skills/seo-cluster/SKILL.mdskillShow content (13379 bytes)
--- name: seo-cluster description: > SERP-based semantic topic clustering for content architecture planning. Groups keywords by actual Google SERP overlap (not text similarity), designs hub-and-spoke content clusters with internal link matrices, and generates interactive visualizations. Optionally executes content creation if claude-blog is installed. Use when user says "topic cluster", "content cluster", "semantic clustering", "pillar page", "hub and spoke", "content architecture", "keyword grouping", or "cluster plan". user-invokable: true argument-hint: "<seed-keyword or url>" license: MIT metadata: author: AgriciDaniel original_author: "Lutfiya Miller (Pro Hub Challenge Winner)" version: "1.9.6" category: seo --- # Semantic Topic Clustering (v1.9.0) SERP-overlap-driven keyword clustering for content architecture. Groups keywords by how Google actually ranks them (shared top-10 results), not by text similarity. Designs hub-and-spoke content clusters with internal link matrices and generates interactive cluster map visualizations. **Scripts:** Located at the plugin root `scripts/` directory. --- ## Quick Reference | Command | What it does | |---------|-------------| | `/seo cluster plan <seed-keyword>` | Full planning workflow: expand, cluster, architect, visualize | | `/seo cluster plan --from strategy` | Import from existing `/seo plan` output | | `/seo cluster execute` | Execute plan: create content via claude-blog or output briefs | | `/seo cluster map` | Regenerate the interactive cluster visualization | --- ## Planning Workflow ### Step 1: Seed Keyword Expansion Expand the seed keyword into 30-50 variants using WebSearch: 1. **Related searches** — Search the seed, extract "related searches" and "people also search for" 2. **People Also Ask (PAA)** — Extract all PAA questions from SERP results 3. **Long-tail modifiers** — Append common modifiers: "best", "how to", "vs", "for beginners", "tools", "examples", "guide", "template", "mistakes", "checklist" 4. **Question mining** — Generate who/what/when/where/why/how variants 5. **Intent modifiers** — Add commercial modifiers: "pricing", "review", "alternative", "comparison", "free", "top" **Deduplication:** Normalize variants (lowercase, strip articles), remove exact duplicates. Target: 30-50 unique keyword variants. If under 30, run a second expansion pass with the top PAA questions as seeds. ### Step 2: SERP Overlap Clustering This is the core differentiator. Load `references/serp-overlap-methodology.md` for the full algorithm. **Process:** 1. Group keywords by initial intent guess (reduces pairwise comparisons) 2. For each candidate pair within a group, WebSearch both keywords 3. Count shared URLs in the top 10 organic results (ignore ads, featured snippets, PAA) 4. Apply thresholds: | Shared Results | Relationship | Action | |---------------|-------------|--------| | 7-10 | Same post | Merge into single target page | | 4-6 | Same cluster | Group under same spoke cluster | | 2-3 | Interlink | Place in adjacent clusters, add cross-links | | 0-1 | Separate | Assign to different clusters or exclude | **Optimization:** With 40 keywords, full pairwise = 780 comparisons. Instead: - Pre-group by intent (4 groups of ~10 = 4 x 45 = 180 comparisons) - Only cross-check group boundary keywords - Skip pairs where both are long-tail variants of the same head term (assume same cluster) **DataForSEO integration:** If DataForSEO MCP is available, use `serp_organic_live_advanced` instead of WebSearch for SERP data. Run `python scripts/dataforseo_costs.py check serp_organic_live_advanced --count N` before each batch. If `"status": "needs_approval"`, show cost estimate and ask user. If `"status": "blocked"`, fall back to WebSearch. ### Step 3: Intent Classification Classify each keyword into one of four intent categories: | Intent | Signals | Include in Clusters? | |--------|---------|---------------------| | Informational | how, what, why, guide, tutorial, learn | Yes | | Commercial | best, top, review, comparison, vs, alternative | Yes | | Transactional | buy, price, discount, coupon, order, sign up | Yes | | Navigational | brand names, specific product names, login | No (exclude) | Remove navigational keywords from clustering. Flag borderline cases for manual review. Keywords can have mixed intent (e.g., "best CRM software" is both commercial and informational) -- classify by dominant intent. ### Step 4: Hub-and-Spoke Architecture Load `references/hub-spoke-architecture.md` for full specifications. **Design the cluster structure:** 1. **Select the pillar keyword** — Highest volume, broadest intent, most SERP overlap with other keywords 2. **Group spokes into clusters** — Each cluster is a subtopic area (2-5 clusters per pillar) 3. **Assign posts to clusters** — Each cluster gets 2-4 spoke posts 4. **Select templates per post** — Based on intent classification: | Intent Pattern | Template Options | |---------------|-----------------| | Informational (broad) | ultimate-guide | | Informational (how) | how-to | | Informational (list) | listicle | | Informational (concept) | explainer | | Commercial (compare) | comparison | | Commercial (evaluate) | review | | Commercial (rank) | best-of | | Transactional | landing-page | 5. **Set word count targets:** - Pillar page: 2500-4000 words - Spoke posts: 1200-1800 words 6. **Cannibalization check** — No two posts share the same primary keyword. If SERP overlap is 7+, merge those keywords into a single post targeting both. ### Step 5: Internal Link Matrix Design the bidirectional linking structure: | Link Type | Direction | Requirement | |-----------|-----------|-------------| | Spoke to pillar | spoke -> pillar | Mandatory (every spoke) | | Pillar to spoke | pillar -> spoke | Mandatory (every spoke) | | Spoke to spoke (within cluster) | spoke <-> spoke | 2-3 links per post | | Cross-cluster | spoke -> spoke (other cluster) | 0-1 links per post | **Rules:** - Every post must have minimum 3 incoming internal links - No orphan pages (every post reachable from pillar in 2 clicks) - Anchor text must use target keyword or close variant (no "click here") - Link placement: within body content, not just navigation/sidebar Generate the link matrix as a JSON adjacency list: ```json { "links": [ { "from": "pillar", "to": "cluster-0-post-0", "type": "mandatory", "anchor": "keyword" }, { "from": "cluster-0-post-0", "to": "pillar", "type": "mandatory", "anchor": "keyword" } ] } ``` ### Step 6: Interactive Cluster Map Generate `cluster-map.html` using the template at `templates/cluster-map.html`. 1. Read the template file 2. Build the `CLUSTER_DATA` JSON object from the cluster plan: ```javascript { pillar: { title, keyword, volume, template, wordCount, url }, clusters: [{ name, color, posts: [{ title, keyword, volume, template, wordCount, url, status }] }], links: [{ from, to, type }], meta: { totalPosts, totalClusters, totalLinks, estimatedWords } } ``` 3. Replace the `CLUSTER_DATA` placeholder in the template with the actual JSON 4. Write the completed HTML file to the output directory 5. Inform user: "Open `cluster-map.html` in a browser to explore the interactive cluster map." --- ## Strategy Import When invoked with `--from strategy`: 1. Look for the most recent `/seo plan` output in the current directory (search for files matching `*SEO*Plan*`, `*strategy*`, `*content-strategy*`) 2. Parse markdown tables for: keywords, page types, content pillars, URL structures 3. Validate extracted data: check for duplicates, missing keywords, incomplete entries 4. Enrich with SERP data: run SERP overlap analysis on extracted keywords 5. Build cluster plan using the imported keywords as the starting set (skip Step 1) If no strategy file is found, prompt the user: "No existing SEO plan found in the current directory. Run `/seo plan` first, or provide a seed keyword for fresh clustering." --- ## Execution Workflow When `/seo cluster execute` is invoked: ### Check for claude-blog ``` Test: Does ~/.claude/skills/blog/SKILL.md exist? ``` **If claude-blog IS installed:** 1. Load `references/execution-workflow.md` for the full algorithm 2. Read `cluster-plan.json` from the current directory 3. Check for resume state: scan output directory for already-written posts 4. Execute in priority order: pillar first, then spokes by volume (highest first) 5. For each post, invoke the `blog-write` skill with cluster context: - Cluster role (pillar or spoke) - Position in cluster (cluster index, post index) - Target keyword and secondary keywords - Template type and word count target - Internal links to include (with anchors) - Links to receive from future posts (placeholder markers) 6. After each post is written, scan previous posts for backward link placeholders and inject the new post's URL 7. After all posts are written, generate the cluster scorecard **If claude-blog is NOT installed:** 1. Generate detailed content briefs for each post in the cluster plan 2. Each brief includes: - Title and meta description - Primary keyword and secondary keywords - Template type and suggested structure (H2/H3 outline) - Word count target - Internal links to include (with anchor text) - Key points to cover - Competing pages to differentiate from 3. Write briefs to `cluster-briefs/` directory as individual markdown files 4. Inform user: "Install [claude-blog](https://github.com/AgriciDaniel/claude-blog) to auto-create content. Briefs saved to `cluster-briefs/`." --- ## Cluster Scorecard Post-execution quality report. Run automatically after `/seo cluster execute` or on demand via analysis of the output directory. | Metric | Target | How Measured | |--------|--------|-------------| | Coverage | 100% | Posts written / posts planned | | Link Density | 3+ per post | Count internal links per post | | Orphan Pages | 0 | Posts with < 1 incoming link | | Cannibalization | 0 conflicts | Check for duplicate primary keywords | | Image Count | 1+ per post | Posts with at least one image | | Pillar Links | 100% | All spokes link to pillar and vice versa | | Cross-Links | 80%+ | Recommended spoke-to-spoke links implemented | | Content Gaps | 0 | Planned posts that were skipped or incomplete | --- ## Map Regeneration When `/seo cluster map` is invoked: 1. Read `cluster-plan.json` from the current directory 2. Scan output directory and update post statuses (planned vs written) 3. Regenerate `cluster-map.html` with updated statuses 4. Report: posts written vs planned, link completion percentage --- ## Output Files All outputs are written to the current working directory: | File | Description | |------|-------------| | `cluster-plan.json` | Machine-readable cluster plan (full data) | | `cluster-plan.md` | Human-readable cluster plan summary | | `cluster-map.html` | Interactive SVG visualization | | `cluster-briefs/` | Content briefs (if no claude-blog) | | `cluster-scorecard.md` | Post-execution quality report | --- ## Cross-Skill Integration | Skill | Relationship | |-------|-------------| | `seo-plan` | Import source: strategy import reads seo-plan output | | `seo-content` | Quality check: E-E-A-T validation of generated content | | `seo-schema` | Schema markup: Article, BreadcrumbList, ItemList for cluster pages | | `seo-dataforseo` | Data source: SERP data when DataForSEO MCP is available | | `seo-google` | Reporting: generate PDF report of cluster plan and scorecard | After cluster planning or execution completes, offer: "Generate a PDF report? Use `/seo google report`" --- ## Error Handling | Error | Cause | Resolution | |-------|-------|------------| | "No seed keyword provided" | Missing argument | Prompt user for seed keyword or URL | | "Insufficient keyword variants" | Expansion yielded < 15 keywords | Run second expansion pass with PAA questions | | "SERP data unavailable" | WebSearch and DataForSEO both failing | Retry after 30s; if persistent, use intent-only clustering with warning | | "No strategy file found" | `--from strategy` but no plan exists | Prompt user to run `/seo plan` first | | "cluster-plan.json not found" | Execute without planning | Prompt user to run `/seo cluster plan` first | | "claude-blog not installed" | Execute attempted without blog skill | Generate content briefs instead; suggest installation | | "DataForSEO budget exceeded" | Cost check returned "blocked" | Fall back to WebSearch; inform user | | "Duplicate primary keywords" | Cannibalization detected | Merge affected posts or reassign keywords | | "Orphan page detected" | Post missing incoming links | Add links from nearest cluster siblings | | "Resume state corrupted" | Mismatch between plan and output | Rebuild state from output directory scan | --- ## Security - All URLs fetched via `python scripts/fetch_page.py` (SSRF protection via `validate_url()`) - No credentials stored or transmitted - Output files contain no PII or API keys - DataForSEO cost checks run before every API call ## FLOW Framework Integration For prompt-guided keyword research and gap analysis, use `/seo flow find [url|topic]` — FLOW's 5 find-stage prompts complement the SERP-overlap clustering methodology with structured discovery prompts..claude-plugin/marketplace.jsonmarketplaceShow content (704 bytes)
{ "$schema": "https://anthropic.com/claude-code/marketplace.schema.json", "name": "agricidaniel-seo", "owner": { "name": "AgriciDaniel" }, "metadata": { "description": "SEO analysis tools for Claude Code" }, "plugins": [ { "name": "claude-seo", "source": "./", "description": "Comprehensive SEO analysis skill for Claude Code. 21 core sub-skills covering technical SEO, E-E-A-T, schema markup, image optimization, GEO/AEO, backlinks, local SEO, maps intelligence, semantic topic clustering, SXO, SEO drift monitoring, e-commerce SEO, international SEO with cultural profiles, FLOW framework integration, Google API integration, and PDF reporting." } ] }
README

Claude SEO - SEO Audit Skill for Claude Code
Comprehensive SEO analysis skill for Claude Code. 21 core sub-skills covering technical SEO, on-page analysis, content quality (E-E-A-T), schema markup, image optimization, sitemap architecture, AI search optimization (GEO), local SEO, maps intelligence, semantic topic clustering, search experience optimization (SXO), SEO drift monitoring, e-commerce SEO, international SEO with cultural profiles, FLOW framework integration, Google SEO APIs (Search Console, PageSpeed, CrUX, GA4), PDF report generation, and strategic planning.

![]()
![]()

Using Codex instead of Claude Code? Use Codex SEO, the Codex-first port of this project with Codex skills, TOML agents, plugin packaging, deterministic runners, and the same SEO workflow surface.
Table of Contents
- Installation
- Quick Start
- Commands
- Features
- Architecture
- Extensions
- Showcase
- Ecosystem
- Documentation
- Requirements
- Uninstall
- Contributing
Installation
Plugin Install (Claude Code 1.0.33+)
# Add marketplace (one-time)
/plugin marketplace add AgriciDaniel/claude-seo
# Install plugin
/plugin install claude-seo@AgriciDaniel-claude-seo
Manual Install (Unix/macOS/Linux)
git clone --depth 1 https://github.com/AgriciDaniel/claude-seo.git
bash claude-seo/install.sh
One-liner (curl)
curl -fsSL https://raw.githubusercontent.com/AgriciDaniel/claude-seo/main/install.sh | bash
Or via install.cat:
curl -fsSL install.cat/AgriciDaniel/claude-seo | bash
Prefer to review the script before running?
curl -fsSL https://raw.githubusercontent.com/AgriciDaniel/claude-seo/main/install.sh > install.sh
cat install.sh # review
bash install.sh # run when satisfied
rm install.sh
Windows (PowerShell)
git clone --depth 1 https://github.com/AgriciDaniel/claude-seo.git
powershell -ExecutionPolicy Bypass -File claude-seo\install.ps1
Why git clone instead of
irm | iex? Claude Code's own security guardrails flagirm ... | iexas a supply chain risk (downloading and executing remote code with no verification). The git clone approach lets you inspect the script atclaude-seo\install.ps1before running it.
Quick Start
# Start Claude Code
claude
# Run a full site audit
/seo audit https://example.com
# Analyze a single page
/seo page https://example.com/about
# Check schema markup
/seo schema https://example.com
# Generate a sitemap
/seo sitemap generate
# Optimize for AI search
/seo geo https://example.com
Demo:
Watch the full demo on YouTube
/seo audit: full site audit with parallel subagents:

Commands
| Command | Description |
|---|---|
/seo audit <url> | Full website audit with parallel subagent delegation |
/seo page <url> | Deep single-page analysis |
/seo sitemap <url> | Analyze existing XML sitemap |
/seo sitemap generate | Generate new sitemap with industry templates |
/seo schema <url> | Detect, validate, and generate Schema.org markup |
/seo images <url> | Image optimization analysis |
/seo technical <url> | Technical SEO audit (9 categories) |
/seo content <url> | E-E-A-T and content quality analysis |
/seo geo <url> | AI Overviews / Generative Engine Optimization |
/seo plan <type> | Strategic SEO planning (saas, local, ecommerce, publisher, agency) |
/seo programmatic <url> | Programmatic SEO analysis and planning |
/seo competitor-pages <url> | Competitor comparison page generation |
/seo local <url> | Local SEO analysis (GBP, citations, reviews, map pack) |
/seo maps [command] | Maps intelligence (geo-grid, GBP audit, reviews, competitors) |
/seo hreflang <url> | Hreflang/i18n SEO audit and generation |
/seo google [command] [url] | Google SEO APIs (GSC, PageSpeed, CrUX, Indexing, GA4) |
/seo google report [type] | Generate PDF/HTML report with charts (cwv-audit, gsc-performance, full) |
/seo backlinks <url> | Backlink profile analysis (free: Moz, Bing, Common Crawl) |
/seo cluster <seed-keyword> | SERP-based semantic clustering and content architecture |
/seo sxo <url> | Search Experience Optimization: page-type, user stories, personas |
/seo drift baseline <url> | Capture SEO baseline for change monitoring |
/seo drift compare <url> | Compare current state to stored baseline |
/seo drift history <url> | Show drift history over time |
/seo ecommerce <url> | E-commerce SEO: product schema, marketplace intelligence |
/seo firecrawl [command] <url> | Full-site crawling and site mapping (extension) |
/seo dataforseo [command] | Live SEO data via DataForSEO (extension) |
/seo image-gen [use-case] <desc> | AI image generation for SEO assets (extension) |
/seo programmatic [url|plan]
Programmatic SEO Analysis & Planning
Build SEO pages at scale from data sources with quality safeguards.
Capabilities:
- Analyze existing programmatic pages for thin content and cannibalization
- Plan URL patterns and template structures for data-driven pages
- Internal linking automation between generated pages
- Canonical strategy and index bloat prevention
- Quality gates: WARNING at 100+ pages, HARD STOP at 500+ without audit
/seo competitor-pages [url|generate]
Competitor Comparison Page Generator
Create high-converting "X vs Y" and "alternatives to X" pages.
Capabilities:
- Structured comparison tables with feature matrices
- Product schema markup with AggregateRating
- Conversion-optimized layouts with CTA placement
- Keyword targeting for comparison intent queries
- Fairness guidelines for accurate competitor representation
/seo hreflang [url]
Hreflang / i18n SEO Audit & Generation
Validate and generate hreflang tags for multi-language sites.
Capabilities:
- Generate hreflang tags (HTML, HTTP headers, or XML sitemap)
- Validate self-referencing tags, return tags, x-default
- Detect common mistakes (missing returns, invalid codes, HTTP/HTTPS mismatch)
- Cross-domain hreflang support
- Language/region code validation (ISO 639-1 + ISO 3166-1)
Features
Core Web Vitals (Current Metrics)
- LCP (Largest Contentful Paint): Target < 2.5s
- INP (Interaction to Next Paint): Target < 200ms
- CLS (Cumulative Layout Shift): Target < 0.1
Note: INP replaced FID on March 12, 2024. FID was fully removed from all Chrome tools on September 9, 2024.
E-E-A-T Analysis
Updated to September 2025 Quality Rater Guidelines:
- Experience: First-hand knowledge signals
- Expertise: Author credentials and depth
- Authoritativeness: Industry recognition
- Trustworthiness: Contact info, security, transparency
Schema Markup
- Detection: JSON-LD (preferred), Microdata, RDFa
- Validation against Google's supported types
- Generation with templates
- Deprecation awareness:
- HowTo: Deprecated (Sept 2023)
- FAQ: Restricted to gov/health sites (Aug 2023)
- SpecialAnnouncement: Deprecated (July 2025)
AI Search Optimization (GEO)
New for 2026 - optimize for:
- Google AI Overviews
- ChatGPT web search
- Perplexity
- Other AI-powered search
Google SEO APIs (New in v1.7.0)
Direct integration with Google's SEO data:
- PageSpeed Insights + CrUX: Lab and field Core Web Vitals data
- Search Console: Top queries, URL inspection, sitemap status
- Indexing API: Notify Google of new/updated/removed URLs
- GA4: Organic traffic, top landing pages, device/country breakdown
- PDF Reports: Enterprise A4 reports with charts via WeasyPrint + matplotlib
4-tier credential system — get value at every level:
| Tier | Auth | APIs |
|---|---|---|
| 0 | API key | PSI, CrUX, CrUX History |
| 1 | + OAuth/SA | + GSC, URL Inspection, Indexing |
| 2 | + GA4 config | + GA4 organic traffic |
| 3 | + Ads token | + Keyword Planner |
Local SEO & Maps Intelligence (New in v1.6.0)
- Google Business Profile optimization
- NAP consistency auditing
- Citation and review analysis
- Geo-grid rank tracking and competitor radius mapping
Quality Gates
- Warning at 30+ location pages
- Hard stop at 50+ location pages
- Thin content detection per page type
- Doorway page prevention
Architecture
~/.claude/skills/seo/ # Main orchestrator skill
~/.claude/skills/seo-*/ # Sub-skills (21 + 3 extensions)
~/.claude/agents/seo-*.md # Subagents (15 + 2 extensions)
Video & Live Schema (New)
Additional schema types for video content, live streaming, and key moments:
- VideoObject: Video page markup with thumbnails, duration, upload date
- BroadcastEvent: LIVE badge support for live streaming content
- Clip: Key moments / chapters within videos
- SeekToAction: Enable seek functionality in video rich results
- SoftwareSourceCode: Open source and code repository pages
See schema/templates.json for ready-to-use JSON-LD snippets.
Recently Added
- Programmatic SEO skill (
/seo programmatic) - Competitor comparison pages skill (
/seo competitor-pages) - Multi-language hreflang validation (
/seo hreflang) - Video & Live schema types (VideoObject, BroadcastEvent, Clip, SeekToAction)
- Google SEO quick-reference guide
Requirements
- Python 3.10+
- Claude Code CLI
- Optional: Playwright for screenshots
- Optional: Google API credentials for enriched data (see
/seo google setup)
Uninstall
git clone --depth 1 https://github.com/AgriciDaniel/claude-seo.git
bash claude-seo/uninstall.sh
One-liner (curl)
curl -fsSL https://raw.githubusercontent.com/AgriciDaniel/claude-seo/main/uninstall.sh | bash
MCP Integrations
Integrates with MCP servers for live SEO data, including official servers from Ahrefs (@ahrefs/mcp) and Semrush, plus community servers for Google Search Console, PageSpeed Insights, and DataForSEO. See MCP Integration Guide for setup.
Extensions
Optional add-ons that integrate external data sources via MCP servers.
DataForSEO
Live SERP data, keyword research, backlinks, on-page analysis, content analysis, business listings, AI visibility checking, and LLM mention tracking. 22 commands across 9 API modules.
# Install (requires DataForSEO account)
./extensions/dataforseo/install.sh
# Example commands
/seo dataforseo serp best coffee shops
/seo dataforseo keywords seo tools
/seo dataforseo backlinks example.com
/seo dataforseo ai-mentions your brand
/seo dataforseo ai-scrape your brand name
See DataForSEO Extension for full documentation.
Banana (AI Image Generation)
Generate SEO images (OG previews, blog heroes, product photos, infographics) using the Claude Banana Creative Director pipeline.
# Install extension
./extensions/banana/install.sh
# Example commands
/seo image-gen og "Professional SaaS dashboard"
/seo image-gen hero "AI-powered content creation"
/seo image-gen batch "Product photography" 3
See Banana Extension for full documentation. Already using standalone Claude Banana? The extension reuses your existing nanobanana-mcp setup.
Firecrawl (Site Crawling)
Full-site crawling and URL discovery using the Firecrawl MCP server.
# Install extension
./extensions/firecrawl/install.sh
# Example commands
/seo firecrawl crawl https://example.com
/seo firecrawl map https://example.com
See Firecrawl Extension for full documentation.
Showcase
Community projects built on top of Claude SEO:
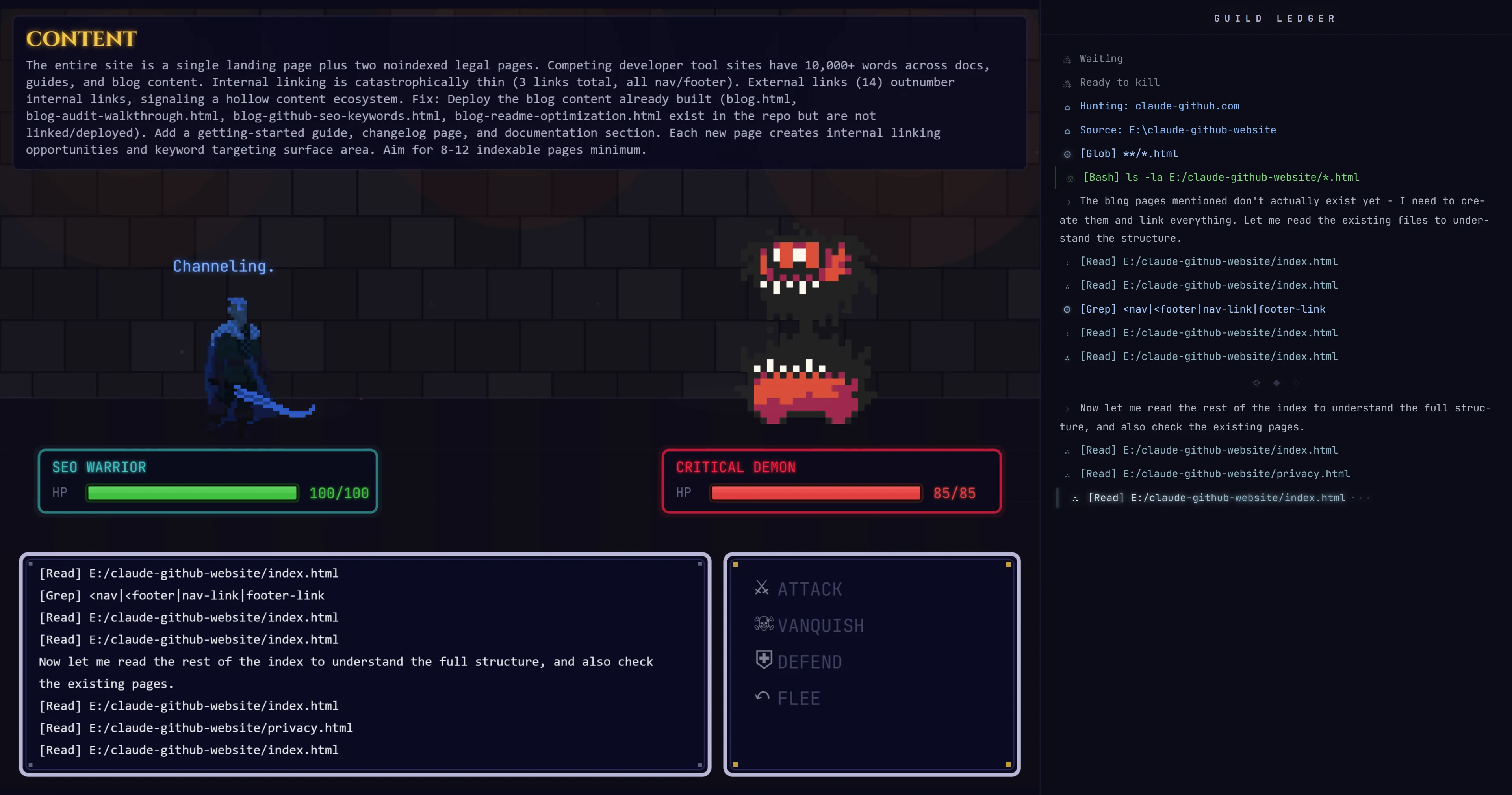
|
Claude SEO Dungeon -- a 16-bit gamified dungeon crawler that turns SEO audits into boss battles. Built on Claude SEO v1.9.0 with Phaser 3, every detected issue becomes a demon and every fix becomes a real commit to your codebase. The Guild Ledger streams Claude's tool calls in real time as you fight. Built by @avalonreset -- live at seodungeon.com. |
Want your project featured here? Open an issue with a link.
Ecosystem
Claude SEO is part of a family of Claude Code skills that work together:
| Skill | What it does | How it connects |
|---|---|---|
| Claude SEO | SEO analysis, audits, schema, GEO | Core -- analyzes sites, generates action plans |
| Claude Blog | Blog writing, optimization, scoring | Companion -- write content optimized by SEO findings |
| Claude Banana | AI image generation via Gemini | Shared -- generates images for SEO assets and blog posts |
| Codex SEO | Codex-first SEO skill suite | Port -- same SEO system adapted for Codex skills, TOML agents, plugins, and deterministic runners |
| AI Marketing Claude | Copywriting, emails, social, ads, funnels, CRO | Community -- post-audit marketing action from SEO findings |
| FLOW | Evidence-led SEO framework (41 AI prompts, CC BY 4.0) | Knowledge base — powers seo-flow prompts |
Workflow example:
/seo audit https://example.com-- identify content gaps and technical issues/seo backlinks https://example.com-- analyze link profile and competitor gaps/blog write "target keyword"-- create SEO-optimized blog posts/seo image-gen hero "blog topic"-- generate hero images (banana extension)/seo geo https://example.com/blog/post-- optimize for AI citations
Documentation
Community Contributors
v1.9.0 includes contributions from the AI Marketing Hub Pro Hub Challenge:
| Contributor | Contribution |
|---|---|
| Lutfiya Miller (Winner) | Semantic Cluster Engine → seo-cluster |
| Florian Schmitz | SXO Skill → seo-sxo |
| Dan Colta | SEO Drift Monitor → seo-drift |
| Chris Muller | Multi-lingual SEO → seo-hreflang enhancements |
| Matej Marjanovic | E-commerce + DataForSEO Cost Config → seo-ecommerce + cost guardrails |
See CONTRIBUTORS.md for full details and original repo links.
License
MIT License - see LICENSE for details.
Contributing
Contributions welcome! Please read CONTRIBUTING.md before submitting PRs.
Built for Claude Code by @AgriciDaniel
Publishing Pipeline
For a full GUI-based publishing workflow from SEO research to published content, see Rankenstein - the AI content engine built on the same SEO principles.
Author
Built by Agrici Daniel - AI Workflow Architect.
- Blog - Deep dives on AI marketing automation
- AI Marketing Hub - Free community, 2,800+ members
- YouTube - Tutorials and demos
- All open-source tools